This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this episode Kevin Liu shares some of the interesting features that they have built by combining those technologies, as well as the challenges that they face in supporting the myriad workloads that are thrown at this layer of their data platform. Can you describe what role Trino and Iceberg play in Stripe's dataarchitecture?
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Data Storage Solutions As we all know, data can be stored in a variety of ways.
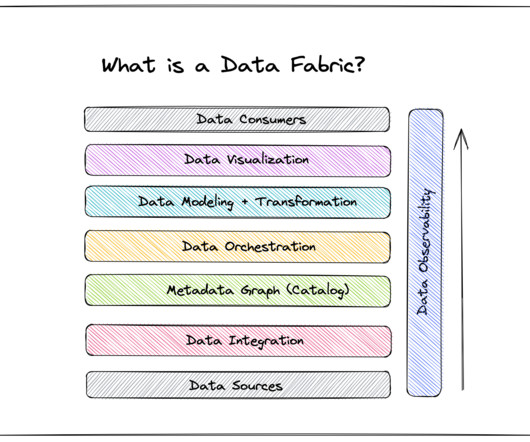
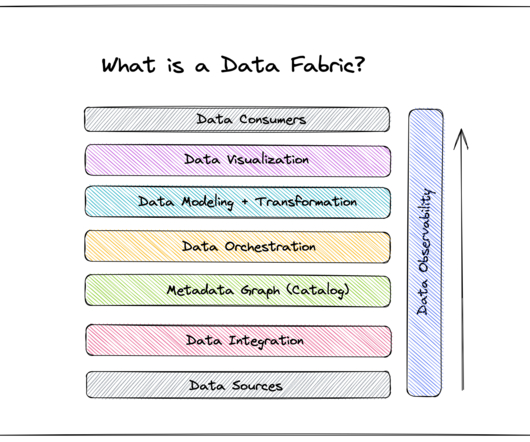
Today, as data sources become increasingly varied, data management becomes more complex, and agility and scalability become essential traits for data leaders, data fabric is quickly becoming the future of dataarchitecture. If data fabric is the future, how can you get your organization up-to-speed?
Today, as data sources become increasingly varied, data management becomes more complex, and agility and scalability become essential traits for data leaders, data fabric is quickly becoming the future of dataarchitecture. If data fabric is the future, how can you get your organization up-to-speed?
Data organizations often have a mix of centralized and decentralized activity. DataOps concerns itself with the complex flow of data across teams, data centers and organizational boundaries. It expands beyond tools and dataarchitecture and views the data organization from the perspective of its processes and workflows.
Here is the agenda, 1) Data Application Lifecycle Management - Harish Kumar( Paypal) Hear from the team in PayPal on how they build the data product lifecycle management (DPLM) systems. 3) DataOPS at AstraZeneca The AstraZeneca team talks about data ops best practices internally established and what worked and what didn’t work!!!
They need high-qualitydata in an answer-ready format to address many scenarios with minimal keyboarding. What they are getting from IT and other data sources is, in reality, poor-qualitydata in a format that requires manual customization. IT-created infrastructure such as a datalake/warehouse).
Key Takeaways Data Fabric is a modern dataarchitecture that facilitates seamless data access, sharing, and management across an organization. Data management recommendations and data products emerge dynamically from the fabric through automation, activation, and AI/ML analysis of metadata.
Data pipelines can handle both batch and streaming data, and at a high-level, the methods for measuring dataquality for either type of asset are much the same. What is a decentralized dataarchitecture?
It’s our goal at Monte Carlo to provide data observability and quality across the enterprise by monitoring every system vital in the delivery of data from source to consumption. We started with popular modern data warehouses and quickly expanded our support as datalakes became data lakehouses.
Azure Data Engineer Associate DP-203 Certification Candidates for this exam must possess a thorough understanding of SQL, Python, and Scala, among other data processing languages. Must be familiar with dataarchitecture, data warehousing, parallel processing concepts, etc.
Modern data engineering can help with this. It creates the systems and processes needed to gather, clean, transfer, and prepare data for AI models. Without it, AI technologies wouldn’t have access to high-qualitydata. AI and Data Synergy AI and data engineering have a symbiotic relationship.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content