This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data storage has been evolving, from databases to data warehouses and expansive datalakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Whether it’s unifying transactional and analytical data with Hybrid Tables, improving governance for an open lakehouse with Snowflake Open Catalog or enhancing threat detection and monitoring with Snowflake Horizon Catalog , Snowflake is reducing the number of moving parts to give customers a fully managed service that just works.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. Each of these architectures has its own unique strengths and tradeoffs.
In this episode Kevin Liu shares some of the interesting features that they have built by combining those technologies, as well as the challenges that they face in supporting the myriad workloads that are thrown at this layer of their data platform. Can you describe what role Trino and Iceberg play in Stripe's dataarchitecture?
In August, we wrote about how in a future where distributed dataarchitectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
Summary The Presto project has become the de facto option for building scalable open source analytics in SQL for the datalake. That leaves DataOps reactive to data quality issues and can make your consumers lose confidence in your data. lets you identify data quality issues and their root causes from a single dashboard.
First, we create an Iceberg table in Snowflake and then insert some data. Then, we add another column called HASHKEY , add more data, and locate the S3 file containing metadata for the iceberg table. In the screenshot below, we can see that the metadata file for the Iceberg table retains the snapshot history.
Snowflake is now making it even easier for customers to bring the platform’s usability, performance, governance and many workloads to more data with Iceberg tables (now generally available), unlocking full storage interoperability. Iceberg tables provide compute engine interoperability over a single copy of data.
Modern dataarchitectures. To eliminate or integrate these silos, the public sector needs to adopt robust data management solutions that support modern dataarchitectures (MDAs). Deploying modern dataarchitectures. Lack of sharing hinders the elimination of fraud, waste, and abuse. Forrester ).
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management RudderStack helps you build a customer data platform on your warehouse or datalake. How has the move to the cloud for data warehousing/data platforms influenced the practice of data modeling?
[link] Alireza Sadeghi: Open Source Data Engineering Landscape 2025 This article comprehensively overviews the 2025 open-source data engineering landscape, highlighting key trends, active projects, and emerging technologies.
Using the metaphor of a museum curator carefully managing the precious resources on display and in the vaults, he discusses the various layers of an enterprise data strategy. Can you walk through the stages of an ideal lifecycle for data within the context of an organizations uses for it?
At Precisely’s Trust ’23 conference, Chief Operating Officer Eric Yau hosted an expert panel discussion on modern dataarchitectures. The group kicked off the session by exchanging ideas about what it means to have a modern dataarchitecture.
Chief Technology Officer, Information Technology Industry Organizations have spent the past decade accumulating, maintaining, and securing datalakes/warehouses/fabrics that will now be expected to drive AI/LLM use cases. The technology for metadata management, data quality management, etc., No problem!
Today, as data sources become increasingly varied, data management becomes more complex, and agility and scalability become essential traits for data leaders, data fabric is quickly becoming the future of dataarchitecture. If data fabric is the future, how can you get your organization up-to-speed?
Today, as data sources become increasingly varied, data management becomes more complex, and agility and scalability become essential traits for data leaders, data fabric is quickly becoming the future of dataarchitecture. If data fabric is the future, how can you get your organization up-to-speed?
Over the past few years, datalakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Data discovery tools and platforms can help.
When it comes to the data community, there’s always a debate broiling about something— and right now “data mesh vs datalake” is right at the top of that list. In this post we compare and contrast the data mesh vs datalake to illustrate the benefits of each and help discover what’s right for your data platform.
With Cloudera’s vision of hybrid data , enterprises adopting an open data lakehouse can easily get application interoperability and portability to and from on premises environments and any public cloud without worrying about data scaling. Why integrate Apache Iceberg with Cloudera Data Platform?
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise data warehouses. On data warehouses and datalakes.
In this context, data management in an organization is a key point for the success of its projects involving data. One of the main aspects of correct data management is the definition of a dataarchitecture. What is Delta Lake? The data became useless. The Lakehouse architecture was one of them.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide datalakes versus smaller, typically BU-Specific, “data ponds”.
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
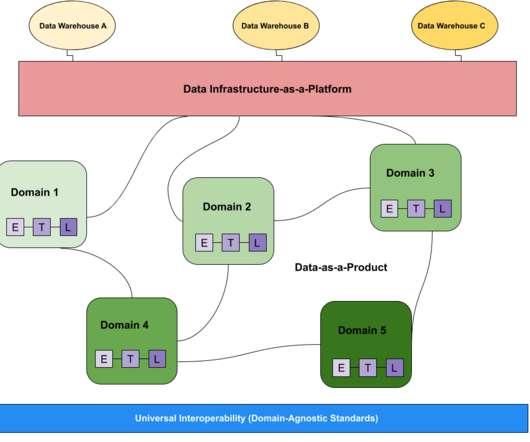
The data mesh design pattern breaks giant, monolithic enterprise dataarchitectures into subsystems or domains, each managed by a dedicated team. First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt.
In fact, we recently announced the integration with our cloud ecosystem bringing the benefits of Iceberg to enterprises as they make their journey to the public cloud, and as they adopt more converged architectures like the Lakehouse. 1: Multi-function analytics . 3: Open Performance.
The Solution: CDP Private Cloud brings a next-generation hybrid architecture with cloud-native benefits to HBL’s data platform. HBL started their data journey in 2019 when datalake initiative was started to consolidate complex data sources and enable the bank to use single version of truth for decision making.
As organizations seek greater value from their data, dataarchitectures are evolving to meet the demand — and table formats are no exception. At its core, a table format is a sophisticated metadata layer that defines, organizes, and interprets multiple underlying data files.
To get a better understanding of a data architect’s role, let’s clear up what dataarchitecture is. Dataarchitecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. Sample of a high-level dataarchitecture blueprint for Azure BI programs.
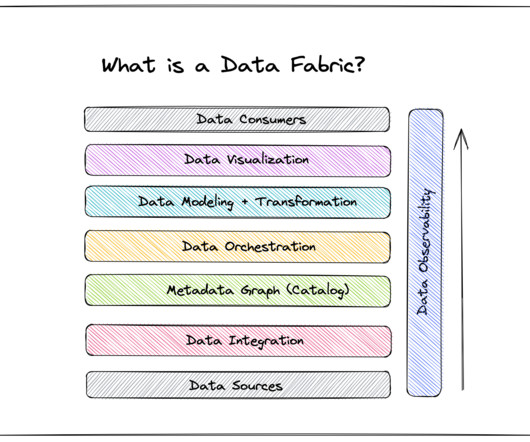
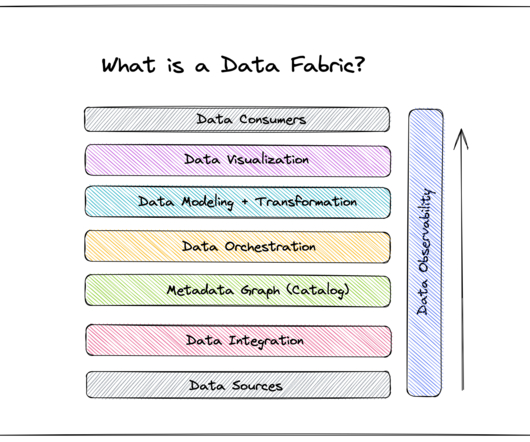
Mark: The first element in the process is the link between the source data and the entry point into the data platform. At Ramsey International (RI), we refer to that layer in the architecture as the foundation, but others call it a staging area, raw zone, or even a source datalake. What is a data fabric?
Grab’s Metasense , Uber’s DataK9 , and Meta’s classification systems use AI to automatically categorize vast data sets, reducing manual efforts and improving accuracy. Beyond classification, organizations now use AI for automated metadata generation and data lineage tracking, creating more intelligent data infrastructures.
Key Takeaways Data Fabric is a modern dataarchitecture that facilitates seamless data access, sharing, and management across an organization. Data management recommendations and data products emerge dynamically from the fabric through automation, activation, and AI/ML analysis of metadata.
As the use of ChatGPT becomes more prevalent, I frequently encounter customers and data users citing ChatGPT’s responses in their discussions. I love the enthusiasm surrounding ChatGPT and the eagerness to learn about modern dataarchitectures such as data lakehouses, data meshes, and data fabrics.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both datalakes and data warehouses and this post will explain this all. What is a data lakehouse? Data warehouse vs datalake vs data lakehouse: What’s the difference.
Managing data and metadata. There are different ways how data can be stored: a data warehouse, numerous datalakes and data hubs , etc. Data engineers control how data is stored and structured within those locations. Providing data access tools. Let’s go through the main areas.
In the dynamic world of data, many professionals are still fixated on traditional patterns of data warehousing and ETL, even while their organizations are migrating to the cloud and adopting cloud-native data services. Central to this transformation are two shifts.
Summit Essentials Date & Location The Gartner Data & AI Summit takes place May 12-15th, 2025 in London, England. This year, the event will uncover the latest in data management, data trends, governance, and dataarchitecture to deliver value for the future.
It’s our goal at Monte Carlo to provide data observability and quality across the enterprise by monitoring every system vital in the delivery of data from source to consumption. We started with popular modern data warehouses and quickly expanded our support as datalakes became data lakehouses.
First, you must understand the existing challenges of the data team, including the dataarchitecture and end-to-end toolchain. Figure 2: Example data pipeline with DataOps automation. In this project, I automated data extraction from SFTP, the public websites, and the email attachments. Monitoring Job Metadata.
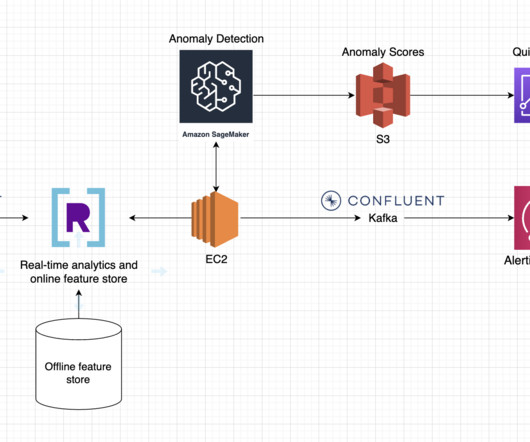
We’ve noticed many common patterns across streaming dataarchitectures and we’ll be sharing a blueprint for three of the most popular: anomaly detection, IoT, and recommendations. Offline feature store : Detecting anomalies requires historical data in order to have a baseline for comparisons. The database has two primary jobs.
A DataOps architecture is the structural foundation that supports the implementation of DataOps principles within an organization. It encompasses the systems, tools, and processes that enable businesses to manage their data more efficiently and effectively. As a result, they can be slow, inefficient, and prone to errors.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a datalake used to host large amounts of raw data.
Cons : Will this concept make it easier or more difficult for organizations to scale their data products? Another fundamental question, which could be asked of many of these futuristic data trends, is do the byproducts of data pipelines (code, data, metadata) contain value for data teams that is worth preserving?
Big Query Google’s cloud data warehouse. DataArchitectureDataarchitecture is a composition of models, rules, and standards for all data systems and interactions between them. Data Catalog An organized inventory of data assets relying on metadata to help with data management.
SiliconANGLE theCUBE: Analyst Predictions 2023 - The Future of Data Management By far one of the best analyses of trends in Data Management. 2023 predictions from the panel are; Unified metadata becomes kingmaker. The names hold less meaning to the outcome, but its fancy. link] All rights reserved ProtoGrowth Inc, India.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content