This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a data warehouse The data warehouse (DW) was an approach to dataarchitecture and structured data management that really hit its stride in the early 1990s.
Gone are the days of just dumping everything into a single database; modern dataarchitectures typically use a combination of datalakes and warehouses. Think of your datalake as a vast reservoir where you store rawdata in its original form—great for when you’re not quite sure how you’ll use it yet.
Snowflake is now making it even easier for customers to bring the platform’s usability, performance, governance and many workloads to more data with Iceberg tables (now generally available), unlocking full storage interoperability. Iceberg tables provide compute engine interoperability over a single copy of data.
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
Over the past few years, datalakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Data discovery tools and platforms can help.
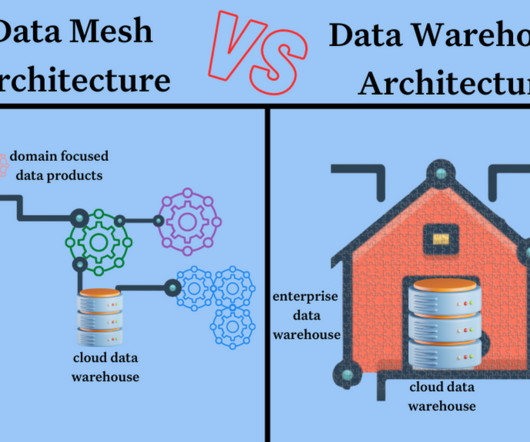
Data Gets Meshier. 2022 will bring further momentum behind modular enterprise architectures like data mesh. The data mesh addresses the problems characteristic of large, complex, monolithic dataarchitectures by dividing the system into discrete domains managed by smaller, cross-functional teams.
Data pipelines are the backbone of your business’s dataarchitecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. Understanding the essential components of data pipelines is crucial for designing efficient and effective dataarchitectures.
Mark: The first element in the process is the link between the source data and the entry point into the data platform. At Ramsey International (RI), we refer to that layer in the architecture as the foundation, but others call it a staging area, raw zone, or even a source datalake. What is a data fabric?
For the same cost, organizations can now store 50 times as much data as in a Hadoop datalake than in a data warehouse. Datalake is gaining momentum across various organizations and everyone wants to know how to implement a datalake and why.
In the dynamic world of data, many professionals are still fixated on traditional patterns of data warehousing and ETL, even while their organizations are migrating to the cloud and adopting cloud-native data services. Central to this transformation are two shifts.
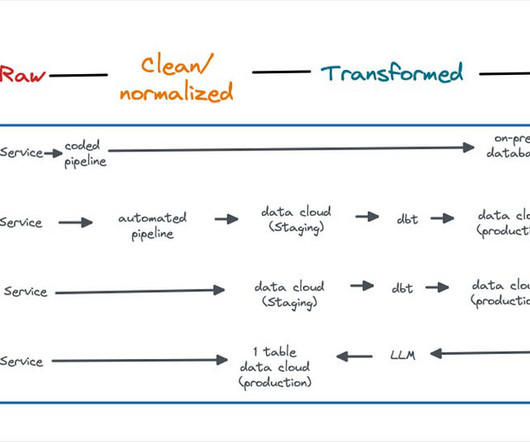
Zero-ETL What it is : A misnomer for one thing; the data pipeline still exists. Today, data is often generated by a service and written into a transactional database. An automatic pipeline is deployed which not only moves the rawdata to the analytical data warehouse, but modifies it slightly along the way.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both datalakes and data warehouses and this post will explain this all. What is a data lakehouse? Data warehouse vs datalake vs data lakehouse: What’s the difference.
Unstructured data , on the other hand, is unpredictable and has no fixed schema, making it more challenging to analyze. Without a fixed schema, the data can vary in structure and organization. There are several widely used unstructured data storage solutions such as datalakes (e.g., Build dataarchitecture.
A DataOps architecture is the structural foundation that supports the implementation of DataOps principles within an organization. It encompasses the systems, tools, and processes that enable businesses to manage their data more efficiently and effectively. As a result, they can be slow, inefficient, and prone to errors.
Generally, data pipelines are created to store data in a data warehouse or datalake or provide information directly to the machine learning model development. Keeping data in data warehouses or datalakes helps companies centralize the data for several data-driven initiatives.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a datalake used to host large amounts of rawdata.
The emergence of cloud data warehouses, offering scalable and cost-effective data storage and processing capabilities, initiated a pivotal shift in data management methodologies. Extract The initial stage of the ELT process is the extraction of data from various source systems. What Is ELT? So, what exactly is ELT?
In the age of self-service business intelligence , nearly every company considers themselves a data-first company, but not every company is treating their dataarchitecture with the level of democratization and scalability it deserves. Your company, for one, views data as a driver of innovation. You will not regret it).
SkyHive platform Challenges with MongoDB for Analytical Queries 16 TB of raw text data from our web crawlers and other data feeds is dumped daily into our S3 datalake. That data was processed and then loaded into our analytics and serving database, MongoDB.
Data pipelines can handle both batch and streaming data, and at a high-level, the methods for measuring data quality for either type of asset are much the same. In many ways, the cloud makes data easier to manage, more accessible to a wider variety of users, and far faster to process.
The modern data stack era , roughly 2017 to present data, saw the widespread adoption of cloud computing and modern data repositories that decoupled storage from compute such as data warehouses, datalakes, and data lakehouses. Zero ETL is a bit of a misnomer.
They simplify data processing for our brains and give readers a quick overview of past, present, and future performance by helping the user to visualize otherwise complex and weighty rawdata. By providing data solutions to departments that need them and to individuals with an insatiable curiosity for data, BI is made scalable.
For today’s Chief Data Officers (CDOs) and data teams, the struggle is real. We’re drowning in data yet thirsting for actionable insights. We need a new approach, a paradigm shift that delivers data with the agility and efficiency of a speedboat – enter Data Products.
[link] Piethein Strengholt: Medallion architecture - best practices for managing Bronze, Silver, and Gold I always find myself very uncomfortable with the naming convention of medallion dataarchitecture. The author writes a few best practices for managing medallion-style architecture.
It enables advanced analytics, makes debugging your marketing automations easier, provides natural audit trails for compliance, and allows for flexible, evolving customer data models. So next time you’re designing your customer dataarchitecture in your CDP, don’t just think about the current state of your customers.
The role of a Power BI developer is extremely imperative as a data professional who uses rawdata and transforms it into invaluable business insights and reports using Microsoft’s Power BI. Develop a long-term vision for Power BI implementation and data analytics. Who is a Power BI Developer?
For example, Snowflake offers data warehouses in different sizes and organizations may have several “data warehouses” to support different data use cases. A data mesh might leverage one or several cloud data warehouses depending on how closely the organization adheres to the dogma.
Data Science- Definition Data Science is an interdisciplinary branch encompassing data engineering and many other fields. Data Science involves applying statistical techniques to rawdata, just like data analysts, with the additional goal of building business solutions.
Aggregator Leaf Tailer (ALT) is the dataarchitecture favored by web-scale companies, like Facebook, LinkedIn, and Google, for its efficiency and scalability. In this blog post, I will describe the Aggregator Leaf Tailer architecture and its advantages for low-latency data processing and analytics.
Testing new functionality on their transactional data store is costly and can impact production. Ad hoc queries to measure the accuracy of the checkout process in real time are not possible with traditional dataarchitectures. When in the experimental phase, quick schema changes are required when analyzing their data.
The practice of designing, building, and maintaining the infrastructure and systems required to collect, process, store, and deliver data to various organizational stakeholders is known as data engineering. You can pace your learning by joining data engineering courses such as the Bootcamp Data Engineer.
Your SQL skills as a data engineer are crucial for data modeling and analytics tasks. Making data accessible for querying is a common task for data engineers. Collecting the rawdata, cleaning it, modeling it, and letting their end users access the clean data are all part of this process.
It also offers a unique architecture that allows users to quickly build tables and begin querying data without administrative or DBA involvement. Snowflake is a cloud-based data platform that provides excellent manageability regarding data warehousing, datalakes, data analytics, etc.
Technical Data Engineer Skills 1.Python Python Python is one of the most looked upon and popular programming languages, using which data engineers can create integrations, data pipelines, integrations, automation, and data cleansing and analysis.
Data engineers and data scientists work very closely together, but there are some differences in their roles and responsibilities. Data Engineer Data scientist The primary role is to design and implement highly maintainable database management systems. It is difficult to query the required unstructured data.
This data can be analysed using big data analytics to maximise revenue and profits. Big data technologies used: Microsoft Azure, Azure Data Factory, Azure Databricks, Spark Big DataArchitecture: This sample Hadoop real-time project starts off by creating a resource group in azure.
Big data operations require specialized tools and techniques since a relational database cannot manage such a large amount of data. Big data enables businesses to gain a deeper understanding of their industry and helps them extract valuable information from the unstructured and rawdata that is regularly collected.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content