This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
At BUILD 2024, we announced several enhancements and innovations designed to help you build and manage your dataarchitecture on your terms. Previously known as Parquet Direct during the private preview stage, this new parameter for COPY and Snowpipe helps you improve performance of legacy datalakes while lowering switching costs.
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a data warehouse The data warehouse (DW) was an approach to dataarchitecture and structured data management that really hit its stride in the early 1990s.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. Each of these architectures has its own unique strengths and tradeoffs.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Data Storage Solutions As we all know, data can be stored in a variety of ways.
Note : Cloud Data warehouses like Snowflake and Big Query already have a default time travel feature. However, this feature becomes an absolute must-have if you are operating your analytics on top of your datalake or lakehouse. It can also be integrated into major data platforms like Snowflake.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
Anyways, I wasn’t paying enough attention during university classes, and today I’ll walk you through data layers using — guess what — an example. Business Scenario & DataArchitecture Imagine this: next year, a new team on the grid, Red Thunder Racing, will call us (yes, me and you) to set up their new data infrastructure.
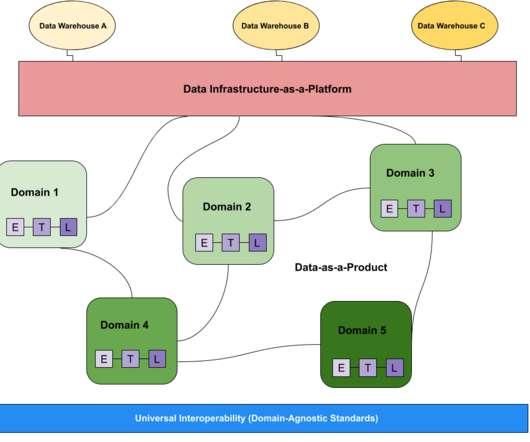
When it comes to the data community, there’s always a debate broiling about something— and right now “data mesh vs datalake” is right at the top of that list. In this post we compare and contrast the data mesh vs datalake to illustrate the benefits of each and help discover what’s right for your data platform.
Over the past few years, datalakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Data discovery tools and platforms can help.
The Rise of Data Observability Data observability has become increasingly critical as companies seek greater visibility into their data processes. This growing demand has found a natural synergy with the rise of the datalake. As a result, monitoring data in real time was often an afterthought.
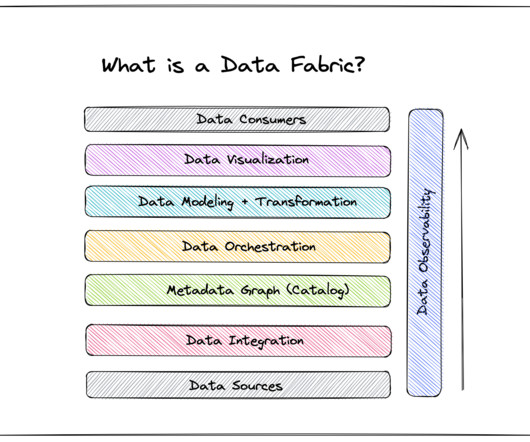
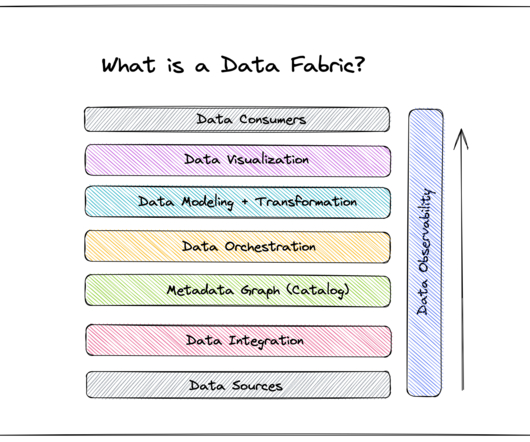
Today, as data sources become increasingly varied, data management becomes more complex, and agility and scalability become essential traits for data leaders, data fabric is quickly becoming the future of dataarchitecture. If data fabric is the future, how can you get your organization up-to-speed?
Today, as data sources become increasingly varied, data management becomes more complex, and agility and scalability become essential traits for data leaders, data fabric is quickly becoming the future of dataarchitecture. If data fabric is the future, how can you get your organization up-to-speed?
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
The Solution: CDP Private Cloud brings a next-generation hybrid architecture with cloud-native benefits to HBL’s data platform. HBL started their data journey in 2019 when datalake initiative was started to consolidate complex data sources and enable the bank to use single version of truth for decision making.
And second, for the data that is used, 80% is semi- or unstructured. Combining and analyzing both structured and unstructureddata is a whole new challenge to come to grips with, let alone doing so across different infrastructures. These answers must be reliable and delivered quickly. Better together.
Strong data governance also lays the foundation for better model performance, cost efficiency, and improved data quality, which directly contributes to regulatory compliance and more secure AI systems.
For the same cost, organizations can now store 50 times as much data as in a Hadoop datalake than in a data warehouse. Datalake is gaining momentum across various organizations and everyone wants to know how to implement a datalake and why.
Data pipelines are the backbone of your business’s dataarchitecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. Understanding the essential components of data pipelines is crucial for designing efficient and effective dataarchitectures.
As the use of ChatGPT becomes more prevalent, I frequently encounter customers and data users citing ChatGPT’s responses in their discussions. I love the enthusiasm surrounding ChatGPT and the eagerness to learn about modern dataarchitectures such as data lakehouses, data meshes, and data fabrics.
Mark: While most discussions of modern data platforms focus on comparing the key components, it is important to understand how they all fit together. The high-level architecture shown below forms the backdrop for the exploration. Luke: Let’s talk about some of the fundamentals of modern dataarchitecture.
Evolution of DataLake Technologies The datalake ecosystem has matured significantly in 2024, particularly in table formats and storage technologies. S3 Tables and Cloud Integration AWS’s introduction of S3 Tables marked a pivotal shift, enabling faster queries and easier management.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide datalakes versus smaller, typically BU-Specific, “data ponds”.
The migration enhanced data quality, lineage visibility, performance improvements, cost reductions, and better reliability and scalability, setting a robust foundation for future expansions and onboarding.
To get a better understanding of a data architect’s role, let’s clear up what dataarchitecture is. Dataarchitecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. Sample of a high-level dataarchitecture blueprint for Azure BI programs.
As organizations seek greater value from their data, dataarchitectures are evolving to meet the demand — and table formats are no exception. But while the modern data stack , and how it’s structured, may be evolving, the need for reliable data is not — and that also has some real implications for your data platform.
The modern data stack era , roughly 2017 to present data, saw the widespread adoption of cloud computing and modern data repositories that decoupled storage from compute such as data warehouses, datalakes, and data lakehouses. Zero ETL is a bit of a misnomer.
Data pipelines can handle both batch and streaming data, and at a high-level, the methods for measuring data quality for either type of asset are much the same. In many ways, the cloud makes data easier to manage, more accessible to a wider variety of users, and far faster to process.
Organizations can harness the power of the cloud, easily scaling resources up or down to meet their evolving data processing demands. Supports Structured and UnstructuredData: One of Azure Synapse's standout features is its versatility in handling a wide array of data types.
In the dynamic world of data, many professionals are still fixated on traditional patterns of data warehousing and ETL, even while their organizations are migrating to the cloud and adopting cloud-native data services. Central to this transformation are two shifts.
Big Data Large volumes of structured or unstructureddata. Big Data Processing In order to extract value or insights out of big data, one must first process it using big data processing software or frameworks, such as Hadoop. Big Query Google’s cloud data warehouse.
Role Level Intermediate Responsibilities Design and develop data pipelines to ingest, process, and transform data. Implemented and managed data storage solutions using Azure services like Azure SQL Database , Azure DataLake Storage, and Azure Cosmos DB.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both datalakes and data warehouses and this post will explain this all. What is a data lakehouse? Data warehouse vs datalake vs data lakehouse: What’s the difference.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a datalake used to host large amounts of raw data.
Data Factory, Data Activator, Power BI, Synapse Real-Time Analytics, Synapse Data Engineering, Synapse Data Science, and Synapse Data Warehouse are some of them. With One Lake serving as a primary multi-cloud repository, Fabric is designed with an open, lake-centric architecture.
In broader terms, two types of data -- structured and unstructureddata -- flow through a data pipeline. The structured data comprises data that can be saved and retrieved in a fixed format, like email addresses, locations, or phone numbers. What is a Big Data Pipeline?
Data engineering is a new and ever-evolving field that can withstand the test of time and computing developments. Companies frequently hire certified Azure Data Engineers to convert unstructureddata into useful, structured data that data analysts and data scientists can use.
It will also discuss about how enterprises have setup datalakes to bring in information from diverse sources but are facing totally new set of challenges as users are not completely able to make use of the data because of slow query response times and data complexity.
Some of the top skills to include are: Experience with Azure data storage solutions: Azure Data Engineers should have hands-on experience with various Azure data storage solutions such as Azure Cosmos DB, Azure DataLake Storage, and Azure Blob Storage.
Let's take a look at all the fuss about data science , its courses, and the path to the future. What is Data Science? In order to discover insights and then analyze multiple structured and unstructureddata, Data Science requires the use of different instruments, algorithms and principles.
Azure Synapse offers a second layer of encryption for data at rest using customer-managed keys stored in Azure Key Vault, providing enhanced data security and control over key management. Cost-Effective DataLake Integration Azure Synapse lets you ditch the traditional separation between SQL and Spark for datalake exploration.
The Azure Data Engineer Certification test evaluates one's capacity for organizing and putting into practice data processing, security, and storage, as well as their capacity for keeping track of and maximizing data processing and storage. You can browse the datalake files with the interactive training material.
Relational Database Management Systems (RDBMS) Non-relational Database Management Systems Relational Databases primarily work with structured data using SQL (Structured Query Language). SQL works on data arranged in a predefined schema. Non-relational databases support dynamic schema for unstructureddata.
The emergence of cloud data warehouses, offering scalable and cost-effective data storage and processing capabilities, initiated a pivotal shift in data management methodologies. Extract The initial stage of the ELT process is the extraction of data from various source systems.
With a plethora of new technology tools on the market, data engineers should update their skill set with continuous learning and data engineer certification programs. What do Data Engineers Do? Technical Data Engineer Skills 1.Python Knowing how to work with key-value pairs and object formats is still necessary.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content