This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a data warehouse The data warehouse (DW) was an approach to dataarchitecture and structured datamanagement that really hit its stride in the early 1990s.
If you need to work with data in your cloud data lake, your on-premise database, or a collection of flat files, then give this episode a listen and then try out Presto today. If you hand a book to a new data engineer, what wisdom would you add to it? If you hand a book to a new data engineer, what wisdom would you add to it?
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts.
News on Hadoop-January 2017 Big Data In Gambling: How A 360-Degree View Of Customers Helps Spot Gambling Addiction. The largest gaming agency in Finland, Veikkaus is using big data to build a 360 degree picture of its customers. Source : [link] How Hadoop helps Experian crunch credit reports. Forbes.com, January 5, 2017.
Summary Managing big data projects at scale is a perennial problem, with a wide variety of solutions that have evolved over the past 20 years. One of the early entrants that predates Hadoop and has since been open sourced is the HPCC (High Performance Computing Cluster) system.
Track data files within the table along with their column statistics. Open table formats enable efficient datamanagement and retrieval by storing these files chronologically, with a history of DDL and DML actions and an index of data file locations. Log all Inserts, Updates, and Deletes (DML) applied to the table.
Imagine having a framework capable of handling large amounts of data with reliability, scalability, and cost-effectiveness. That's where Hadoop comes into the picture. Hadoop is a popular open-source framework that stores and processes large datasets in a distributed manner. Why Are Hadoop Projects So Important?
Big data has taken over many aspects of our lives and as it continues to grow and expand, big data is creating the need for better and faster data storage and analysis. These Apache Hadoop projects are mostly into migration, integration, scalability, data analytics, and streaming analysis. Data Migration 2.
The result is a multi-tenant Data Engineering platform, allowing users and services access to only the data they require for their work. In this post, we focus on how we enhanced and extended Monarch , Pinterest’s Hadoop based batch processing system, with FGAC capabilities. QueryBook uses OAuth to authenticate users.
Summary The current trend in datamanagement is to centralize the responsibilities of storing and curating the organization’s information to a data engineering team. This organizational pattern is reinforced by the architectural pattern of data lakes as a solution for managing storage and access.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Summary With the constant evolution of technology for datamanagement it can seem impossible to make an informed decision about whether to build a data warehouse, or a data lake, or just leave your data wherever it currently rests. What do you have planned for the future of the platform and business?
This was an eye opening conversation about how stateful computation of data streams from edge devices can reduce cost and complexity as compared to batch oriented workflows. We have partnered with organizations such as O’Reilly Media, Dataversity, Corinium Global Intelligence, and Data Council.
To get a better understanding of a data architect’s role, let’s clear up what dataarchitecture is. Dataarchitecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. Sample of a high-level dataarchitecture blueprint for Azure BI programs.
It was interesting to learn about some of the custom data types and performance optimizations that are included. We have partnered with organizations such as O’Reilly Media, Dataversity, and the Open Data Science Conference. Coming up this fall is the combined events of Graphorum and the DataArchitecture Summit.
This conversation was useful for getting a better idea of the challenges that exist in large scale data analytics, and the current state of the tradeoffs between data lakes and data warehouses in the cloud. We have partnered with organizations such as O’Reilly Media, Dataversity, and the Open Data Science Conference.
Data by itself has no value, it needs to be organized, standardized, and clean. In this context, datamanagement in an organization is a key point for the success of its projects involving data. One of the main aspects of correct datamanagement is the definition of a dataarchitecture.
They grabbed data from wherever they could get it – in some cases over the top from smartphones and digital channels – using for example the location of the GPS sensor in the mobile phone rather than the network location functions. The Well-Governed Hybrid Data Cloud: 2018-today.
Most of the Data engineers working in the field enroll themselves in several other training programs to learn an outside skill, such as Hadoop or Big Data querying, alongside their Master's degree and PhDs. Hadoop Platform Hadoop is an open-source software library created by the Apache Software Foundation.
ML models are designed by data scientists, but data engineers deploy those into production. They set up resources required by the model, create pipelines to connect them with data, manage computer resources, and monitor and configure the model’s performance. Managingdata and metadata. Data warehousing.
As such, ATB Financial realized the need to build an enterprise data delivery platform that would enable transparent data ownership for trusted, structured, organized and centralized data operations. Implementing a Modern DataArchitecture.
Data Engineer Bootcamp : The Data Engineer Bootcamp course is designed to give students the skills and knowledge they need to become successful data engineers. The course covers the basics of data engineering, including dataarchitecture, data modeling, and datamanagement.
As organizations seek greater value from their data, dataarchitectures are evolving to meet the demand — and table formats are no exception. The “legacy” table formats The data landscape has evolved so quickly that table formats pioneered within the last 25 years are already achieving “legacy” status.
Data engineering involves a lot of technical skills like Python, Java, and SQL (Structured Query Language). For a data engineer career, you must have knowledge of data storage and processing technologies like Hadoop, Spark, and NoSQL databases. Understanding of Big Data technologies such as Hadoop, Spark, and Kafka.
Big Data Engineer performs a multi-faceted role in an organization by identifying, extracting, and delivering the data sets in useful formats. A Big Data Engineer also constructs, tests, and maintains the Big Dataarchitecture. You will get to learn about data storage and management with lessons on Big Data tools.
Unstructured data refers to information that lacks a predefined format or organization. In contrast, big data refers to large volumes of structured and unstructured data that are challenging to process, store, and analyze using traditional datamanagement tools. Hadoop, Apache Spark).
Big Data Processing In order to extract value or insights out of big data, one must first process it using big data processing software or frameworks, such as Hadoop. Big Query Google’s cloud data warehouse. Data Catalog An organized inventory of data assets relying on metadata to help with datamanagement.
To create autonomous data streams, Data Engineering teams use AWS. Therefore you’ll need to be familiar with the creation and implementation of cloud-based dataarchitecture with this platform. Kafka – Kafka is an open-source framework for processing that can handle real-time data flows.
The 21st edition of the newsletter focuses on the recent breakthroughs in metadata management. I believe the next big set of challenges in data engineering is all about efficient datamanagement… Read more 2 years ago · 4 likes · Ananth Packkildurai What changed my thoughts on Data Catalog?
Define Big Data and Explain the Seven Vs of Big Data. Big Data is a collection of large and complex semi-structured and unstructured data sets that have the potential to deliver actionable insights using traditional datamanagement tools. How is Hadoop related to Big Data?
Datasets: RDDs can contain any type of data and can be created from data stored in local filesystems, HDFS (Hadoop Distributed File System), databases, or data generated through transformations on existing RDDs. In scenarios where these conditions are met, Spark can significantly outperform Hadoop MapReduce.
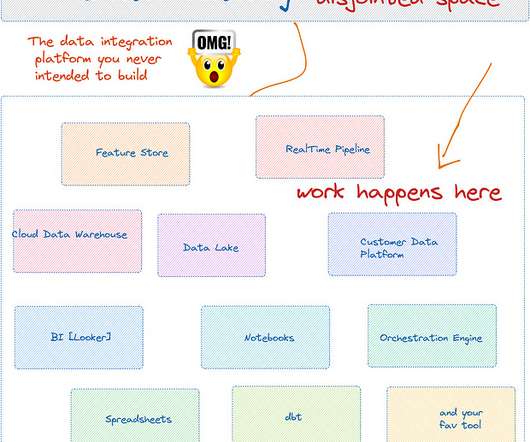
In this post, I’ll explore the origins of the modern data stack, discuss why its promised benefits have proven elusive, and advocate for a post-modern approach to datamanagement that prioritizes productivity and value. Where did the modern data stack come from?
Skills For Azure Data Engineer Resumes Here are examples of popular skills from Azure Data Engineer Hadoop: An open-source software framework called Hadoop is used to store and process large amounts of data on a cluster of inexpensive servers.
A big data engineer is crucial to any company’s datamanagement team. While working as a big data engineer, there are some roles and responsibilities one has to do: Designing large data systems starts with designing a capable system that can handle large workloads.
A big data engineer is crucial to any company’s datamanagement team. While working as a big data engineer, there are some roles and responsibilities one has to do: Designing large data systems starts with designing a capable system that can handle large workloads.
Part of the Data Engineer’s role is to figure out how to best present huge amounts of different data sets in a way that an analyst, scientist, or product manager can analyze. What does a data engineer do? A data engineer is an engineer who creates solutions from raw data.
According to the 8,786 data professionals participating in Stack Overflow's survey, SQL is the most commonly-used language in data science. Despite the buzz surrounding NoSQL , Hadoop , and other big data technologies, SQL remains the most dominant language for data operations among all tech companies.
Computing Revolution: Enter computers, and datamanagement took a leap. Big Data Boom: Fast forward to the 2000s, and Big Data crashed onto the scene. Hadoop and Spark: The cavalry arrived in the form of Hadoop and Spark, revolutionizing how we process and analyze large datasets.
Data Engineer Career: Overview Currently, with the enormous growth in the volume, variety, and veracity of data generated and the will of large firms to store and analyze their data, datamanagement is a critical aspect of data science. That’s where data engineers are on the go.
The data engineers are responsible for creating conversational chatbots with the Azure Bot Service and automating metric calculations using the Azure Metrics Advisor. Data engineers must know datamanagement fundamentals, programming languages like Python and Java, cloud computing and have practical knowledge on data technology.
Big Data Engineer Salary by Experience (Entry-Level, Mid-Level, and Senior) Entry-Level Big Data Engineer Salary An entry-level position does not demand years of experience in Big Data technology. However, one should have an educational background and theoretical knowledge in datamanagement.
As a Data Engineer, you must: Work with the uninterrupted flow of data between your server and your application. Work closely with software engineers and data scientists. Technical Data Engineer Skills 1.Python NoSQL If you think that Hadoop doesn't matter as you have moved to the cloud, you must think again.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, datamanagement , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
is required to become a Data Science expert. Expert-level knowledge of programming, Big Dataarchitecture, etc., is essential to becoming a Data Engineering professional. Data Engineer vs. Data Scientist A LinkedIn report in 2021 shows data science and data engineering are among the top 15 in-demand jobs.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content