This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
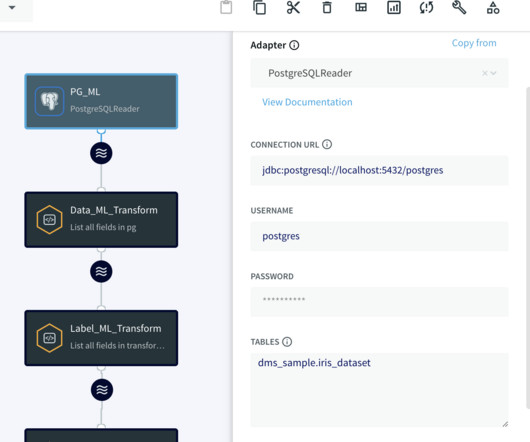
Datapipelines are the backbone of your business’s dataarchitecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. We’ll answer the question, “What are datapipelines?” Table of Contents What are DataPipelines?
DataPipeline Observability: A Model For Data Engineers Eitan Chazbani June 29, 2023 Datapipeline observability is your ability to monitor and understand the state of a datapipeline at any time. We believe the world’s datapipelines need better data observability.
Today’s post follows the same philosophy: fitting local and cloud pieces together to build a datapipeline. And, when it comes to data engineering solutions, it’s no different: They have databases, ETL tools, streaming platforms, and so on — a set of tools that makes our life easier (as long as you pay for them). not sponsored.
AI data engineers are data engineers that are responsible for developing and managing datapipelines that support AI and GenAI data products. Essential Skills for AI Data Engineers Expertise in DataPipelines and ETL Processes A foundational skill for data engineers?
Data organizations often have a mix of centralized and decentralized activity. DataOps concerns itself with the complex flow of data across teams, data centers and organizational boundaries. It expands beyond tools and dataarchitecture and views the data organization from the perspective of its processes and workflows.
When implemented effectively, smart datapipelines seamlessly integrate data from diverse sources, enabling swift analysis and actionable insights. They empower data analysts and business users alike by providing critical information while protecting sensitive production systems. What is a Smart DataPipeline?
The Race For Data Quality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. It sounds great, but how do you prove the data is correct at each layer? How do you ensure data quality in every layer
In this three-part blog post series, we introduce you to Psyberg , our incremental dataprocessing framework designed to tackle such challenges! We’ll discuss batch dataprocessing, the limitations we faced, and how Psyberg emerged as a solution. Let’s dive in!
Datapipelines are integral to business operations, regardless of whether they are meticulously built in-house or assembled using various tools. As companies become more data-driven, the scope and complexity of datapipelines inevitably expand. Ready to fortify your data management practice?
Datapipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. Table of Contents What is a DataPipeline? The Importance of a DataPipeline What is an ETL DataPipeline?
In this post, we will help you quickly level up your overall knowledge of datapipelinearchitecture by reviewing: Table of Contents What is datapipelinearchitecture? Why is datapipelinearchitecture important? What is datapipelinearchitecture?
Anyways, I wasn’t paying enough attention during university classes, and today I’ll walk you through data layers using — guess what — an example. Business Scenario & DataArchitecture Imagine this: next year, a new team on the grid, Red Thunder Racing, will call us (yes, me and you) to set up their new data infrastructure.
The Rise of Data Observability Data observability has become increasingly critical as companies seek greater visibility into their dataprocesses. This growing demand has found a natural synergy with the rise of the data lake. However, as with any advanced tool, data observability comes with costs and complexities.
Its multi-cluster shared dataarchitecture is one of its primary features. Additionally, Fabric has deep integrations with Power BI for visualization and Microsoft Purview for governance, resulting in a smooth experience for both business users and data professionals.
Striim serves as a real-time data integration platform that seamlessly and continuously moves data from diverse data sources to destinations such as cloud databases, messaging systems, and data warehouses, making it a vital component in modern dataarchitectures.
Seeing the future in a modern dataarchitecture The key to successfully navigating these challenges lies in the adoption of a modern dataarchitecture. This results in enhanced efficiency in compliance processes.
On-prem data warehouses can provide lower latency solutions for critical applications that require high performance and low latency. Many companies may choose an on-prem data warehousing solution for quicker dataprocessing to enable business decisions. Data integrations and pipelines can also impact latency.
CRN’s The 10 Hottest Data Science & Machine Learning Startups of 2020 (So Far). In June of 2020, CRN featured DataKitchen’s DataOps Platform for its ability to manage the datapipeline end-to-end combining concepts from Agile development, DevOps, and statistical process control: DataKitchen.
While navigating so many simultaneous data-dependent transformations, they must balance the need to level up their data management practices—accelerating the rate at which they ingest, manage, prepare, and analyze data—with that of governing this data.
Organizations increasingly rely on streaming data sources not only to bring data into the enterprise but also to perform streaming analytics that accelerate the process of being able to get value from the data early in its lifecycle.
Its flexibility allows it to operate on single-node machines and large clusters, serving as a multi-language platform for executing data engineering , data science , and machine learning tasks. Before diving into the world of Spark, we suggest you get acquainted with data engineering in general. Big dataprocessing.
The technological linchpin of its digital transformation has been its Enterprise DataArchitecture & Governance platform. It hosts over 150 big data analytics sandboxes across the region with over 200 users utilizing the sandbox for data discovery.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide data lakes versus smaller, typically BU-Specific, “data ponds”.
They provide an AWS-native, serverless, data infrastructure that installs in your VPC. Datacoral helps data engineers build and manage the flow of datapipelines without having to manage any infrastructure. They provide an AWS-native, serverless, data infrastructure that installs in your VPC.
To get a better understanding of a data architect’s role, let’s clear up what dataarchitecture is. Dataarchitecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. What is the main difference between a data architect and a data engineer?
But with the start of the 21st century, when data started to become big and create vast opportunities for business discoveries, statisticians were rightfully renamed into data scientists. Data scientists today are business-oriented analysts who know how to shape data into answers, often building complex machine learning models.
In fact, we recently announced the integration with our cloud ecosystem bringing the benefits of Iceberg to enterprises as they make their journey to the public cloud, and as they adopt more converged architectures like the Lakehouse. Change data capture (CDC). 1: Multi-function analytics . Flexible and open file formats.
Determining an architecture and a scalable data model to integrate more source systems in the future. The benefits of migrating to Snowflake start with its multi-cluster shared dataarchitecture, which enables scalability and high performance. Features such as auto-suspend and a pay-as-you-go model help you save costs.
It encompasses the systems, tools, and processes that enable businesses to manage their data more efficiently and effectively. These systems typically consist of siloed data storage and processing environments, with manual processes and limited collaboration between teams.
This process not only saves time but also ensures a higher level of data integrity compared to traditional manual methods. According to a McKinsey report , AI can reduce dataprocessing errors by up to 50%, highlighting its potential to transform data quality management.
A new breed of ‘Fast Data’ architectures has evolved to be stream-oriented, where data is processed as it arrives, providing businesses with a competitive advantage. Dean Wampler (Renowned author of many big data technology-related books) Dean Wampler makes an important point in one of his webinars. Dataflow 4.
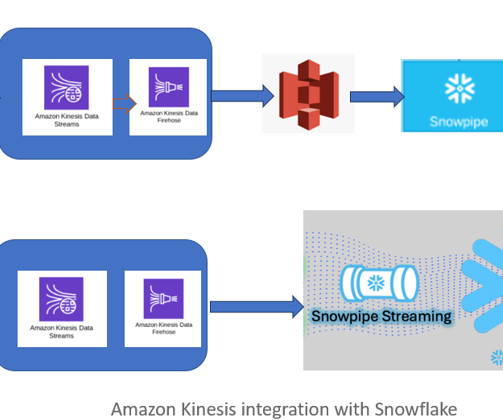
Read Time: 2 Minute, 57 Second Previously, data engineers used Kinesis Firehose to transfer data into blob storage (S3) and then load it into Snowflake using either Snowpipe or batch processing. This introduced latency in the datapipeline for near real-time dataprocessing.
This capability is useful for businesses, as it provides a clear and comprehensive view of their data’s history and transformations. Data lineage tools are not a new concept. In this article: Why Are Data Lineage Tools Important? One of the unique features of Atlan is its human-centric design.
Data Engineering is typically a software engineering role that focuses deeply on data – namely, data workflows, datapipelines, and the ETL (Extract, Transform, Load) process. What is the role of a Data Engineer? They are also accountable for communicating data trends. These are as follows: 1.
[link] Slack: Service Delivery Index: A Driver for Reliability By Data & Data Engineering, we often associate with business operations and product analytics. But the power of the datapipeline to systematically measure things goes beyond business analytics. link] All rights reserved ProtoGrowth Inc, India.
In the dynamic world of data, many professionals are still fixated on traditional patterns of data warehousing and ETL, even while their organizations are migrating to the cloud and adopting cloud-native data services. Central to this transformation are two shifts. Let’s take a closer look.
As organizations seek greater value from their data, dataarchitectures are evolving to meet the demand — and table formats are no exception. Apache ORC (Optimized Row Columnar) : In 2013, ORC was developed for the Hadoop ecosystem to improve the efficiency of data storage and retrieval.
The job description for Azure data engineer that I have elucidated below focuses more on foundational tasks while providing opportunities for learning and growth within the field: Data ingestion: This role involves assisting in the process of collecting and importing data from various sources into Azure storage solutions.
The job description for Azure data engineer that I have elucidated below focuses more on foundational tasks while providing opportunities for learning and growth within the field: Data ingestion: This role involves assisting in the process of collecting and importing data from various sources into Azure storage solutions.
Big Data Large volumes of structured or unstructured data. Big DataProcessing In order to extract value or insights out of big data, one must first process it using big dataprocessing software or frameworks, such as Hadoop. Big Query Google’s cloud data warehouse.
Job Role 1: Azure Data Engineer Azure Data Engineers develop, deploy, and manage data solutions with Microsoft Azure data services. They use many data storage, computation, and analytics technologies to develop scalable and robust datapipelines.
In this article, we will understand the promising data engineer career outlook and what it takes to succeed in this role. What is Data Engineering? Data engineering is the method to collect, process, validate and store data. It involves building and maintaining datapipelines, databases, and data warehouses.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack provides datapipelines that make it easy to collect data from every application, website, and SaaS platform, then activate it in your warehouse and business tools. Data Catalogs - A broken promise I've been a big fan of data catalogs for a long time.
The essential theories, procedures, and equipment for creating trustworthy and effective data systems are covered in this book. It explores subjects including data modeling, datapipelines, data integration, and data quality, offering helpful advice on organizing and implementing reliable data solutions.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content