This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It’s not enough for businesses to implement and maintain a dataarchitecture. The unpredictability of market shifts and the evolving use of new technologies means businesses need more data they can trust than ever to stay agile and make the right decisions.
Data organizations often have a mix of centralized and decentralized activity. DataOps concerns itself with the complex flow of data across teams, data centers and organizational boundaries. It expands beyond tools and dataarchitecture and views the data organization from the perspective of its processes and workflows.
The way to achieve this balance is by moving to a modern dataarchitecture (MDA) that makes it easier to manage, integrate, and govern large volumes of distributed data. When you deploy a platform that supports MDA you can consolidate other systems, like legacy data mediation and disparate data storage solutions.
The introduction of these faster, more powerful networks has triggered an explosion of data, which needs to be processed in real time to meet customer demands. Traditional dataarchitectures struggle to handle these workloads, and without a robust, scalable hybrid data platform, the risk of falling behind is real.
Attendees will discover how to accelerate their critical business workflows with the right data, technology and ecosystem access. Explore AI and unstructured dataprocessing use cases with proven ROI: This year, retailers and brands will face intense pressure to demonstrate tangible returns on their AI investments.
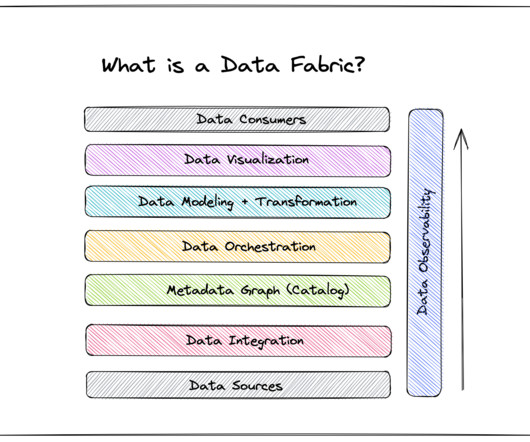
Today, as data sources become increasingly varied, data management becomes more complex, and agility and scalability become essential traits for data leaders, data fabric is quickly becoming the future of dataarchitecture. If data fabric is the future, how can you get your organization up-to-speed?
Today, as data sources become increasingly varied, data management becomes more complex, and agility and scalability become essential traits for data leaders, data fabric is quickly becoming the future of dataarchitecture. If data fabric is the future, how can you get your organization up-to-speed?
Data and AI architecture matter “Before focusing on AI/ML use cases such as hyper personalization and fraud prevention, it is important that the data and dataarchitecture are organized and structured in a way which meets the requirements and standards of the local regulators around the world.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts.
After four months of testing, du Toit and his team had moved one of its databases to Snowflake for bulk dataprocessing. Ramp fetches and delivers data into S3 buckets as well as uses dbt to transform data at each stage. “Snowflake quickly beat the other vendors we were looking at in terms of price and features.”
Additionally, the optimized query execution and data pruning features reduce the compute cost associated with querying large datasets. Scaling data infrastructure while maintaining efficiency is one of the primary challenges of modern dataarchitecture.
Its multi-cluster shared dataarchitecture is one of its primary features. Additionally, Fabric has deep integrations with Power BI for visualization and Microsoft Purview for governance, resulting in a smooth experience for both business users and data professionals.
Striim serves as a real-time data integration platform that seamlessly and continuously moves data from diverse data sources to destinations such as cloud databases, messaging systems, and data warehouses, making it a vital component in modern dataarchitectures.
It allows data scientists to analyze large datasets and interactively run jobs on them from the R shell. Big dataprocessing. Despite these nuances, Spark’s high-speed processing capabilities make it an attractive choice for big dataprocessing tasks. Here are some of the possible use cases.
The Race For Data Quality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. It sounds great, but how do you prove the data is correct at each layer? How do you ensure data quality in every layer
Before loading the data to Snowflake with sub-second latency, Striim allows users to perform in-line transformations, including denormalization, filtering, enrichment and masking, using a SQL-based language. In-flight dataprocessing reduces the time needed for data preparation as it delivers the data in a consumable form.
Anyways, I wasn’t paying enough attention during university classes, and today I’ll walk you through data layers using — guess what — an example. Business Scenario & DataArchitecture Imagine this: next year, a new team on the grid, Red Thunder Racing, will call us (yes, me and you) to set up their new data infrastructure.
The Current State of the DataArchitecture S3 intelligent tiered storage provides a fine balance between the cost and the duration of the data retention. However, the real-time insight on accessing the recent data remains a big challenge. The combination of stream processing + OLAP storage like Pinot. What is Next?
While navigating so many simultaneous data-dependent transformations, they must balance the need to level up their data management practices—accelerating the rate at which they ingest, manage, prepare, and analyze data—with that of governing this data.
Data pipelines are the backbone of your business’s dataarchitecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. Understanding the essential components of data pipelines is crucial for designing efficient and effective dataarchitectures.
On-prem data warehouses can provide lower latency solutions for critical applications that require high performance and low latency. Many companies may choose an on-prem data warehousing solution for quicker dataprocessing to enable business decisions. Data integrations and pipelines can also impact latency.
In this context, managing the data, especially when it arrives late, can present a substantial challenge! In this three-part blog post series, we introduce you to Psyberg , our incremental dataprocessing framework designed to tackle such challenges! Let’s dive in! To solve these problems, we came up with Psyberg!
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide data lakes versus smaller, typically BU-Specific, “data ponds”.
Organizations increasingly rely on streaming data sources not only to bring data into the enterprise but also to perform streaming analytics that accelerate the process of being able to get value from the data early in its lifecycle.
Data infrastructure should serve the current set of business needs and be able to scale and evolve with change. With Snowflake and Iceberg tables, customers have the ability to adapt to these changes and deploy their choice of dataarchitecture, all while maintaining leading security, performance and simplicity.
In fact, we recently announced the integration with our cloud ecosystem bringing the benefits of Iceberg to enterprises as they make their journey to the public cloud, and as they adopt more converged architectures like the Lakehouse. Change data capture (CDC). 1: Multi-function analytics . Flexible and open file formats.
This specialist works closely with people on both business and IT sides of a company to understand the current needs of the stakeholders and help them unlock the full potential of data. To get a better understanding of a data architect’s role, let’s clear up what dataarchitecture is.
In this context, data management in an organization is a key point for the success of its projects involving data. One of the main aspects of correct data management is the definition of a dataarchitecture. Spark: The definitive guide: Big dataprocessing made simple. O’Reilly Media, Inc.” [2]
The technological linchpin of its digital transformation has been its Enterprise DataArchitecture & Governance platform. It hosts over 150 big data analytics sandboxes across the region with over 200 users utilizing the sandbox for data discovery.
A new breed of ‘Fast Data’ architectures has evolved to be stream-oriented, where data is processed as it arrives, providing businesses with a competitive advantage. Dean Wampler (Renowned author of many big data technology-related books) Dean Wampler makes an important point in one of his webinars. Dataflow 4.
In recent years, the term “data lakehouse” was coined to describe this architectural pattern of tabular analytics over data in the data lake. In a rush to own this term, many vendors have lost sight of the fact that the openness of a dataarchitecture is what guarantees its durability and longevity.
We have partnered with organizations such as O’Reilly Media, Dataversity, Corinium Global Intelligence, Alluxio, and Data Council. Upcoming events include the combined events of the DataArchitecture Summit and Graphorum, the Data Orchestration Summit, and Data Council in NYC.
Out of the box Cloudera Data platform (CDP) performs superbly but over time, if dataarchitecture, data engineering, and DevOps best practices are not maintained, you can get stuck maintaining the wild, wild west. In this six-part series, we’re focused on improving the health of your environment.
A DataOps architecture is the structural foundation that supports the implementation of DataOps principles within an organization. It encompasses the systems, tools, and processes that enable businesses to manage their data more efficiently and effectively. As a result, they can be slow, inefficient, and prone to errors.
From a dataarchitecture point of view, this enables a lot of flexibility in integrating multiple systems. link] Netflix: Diving Deeper into Psyberg: Stateless vs Stateful DataProcessing Netflix wrote a deep-dive article about Psyberg’s incremental dataprocessing pipeline framework.
Determining an architecture and a scalable data model to integrate more source systems in the future. The benefits of migrating to Snowflake start with its multi-cluster shared dataarchitecture, which enables scalability and high performance. Features such as auto-suspend and a pay-as-you-go model help you save costs.
The Rise of Data Observability Data observability has become increasingly critical as companies seek greater visibility into their dataprocesses. This growing demand has found a natural synergy with the rise of the data lake.
Why we are watching them: DataKitchen aims to automate and coordinate people, tools and environments of an entire data analytic organization. The company also works to help organizations on applying Agile, DevOps and Lean principles to their dataprocesses with the DataOps Cookbook and manifesto.
Snowpark Container Services gives developers the ability to bring any containerized workload to their data that is already secure in Snowflake — ReactJS front-ends, open source large language models (LLMs), distributed dataprocessing pipelines, you name it.
eMAG , a Romania-based retailer seen as a pioneer in e-commerce, was struggling to manage the tremendously large amount of data coming in every second. The company needed a modern dataarchitecture to manage the growing traffic effectively. . This creates long delays in dataprocessing, which halts efficient functioning. .
Discover how Alex’s journey from building racing motorcycles and tattoo machines as a child led him to revolutionize stream processing and cloud infrastructure. Explore the intricate challenges and groundbreaking innovations in data storage and streaming.
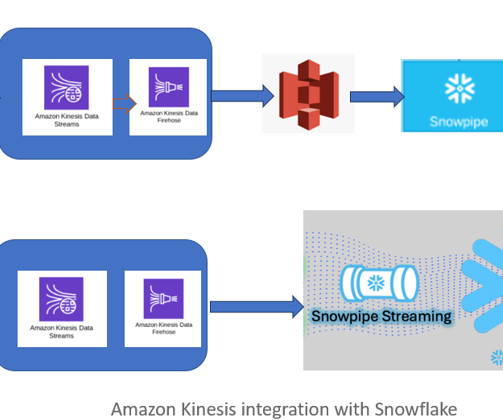
Read Time: 2 Minute, 57 Second Previously, data engineers used Kinesis Firehose to transfer data into blob storage (S3) and then load it into Snowflake using either Snowpipe or batch processing. This introduced latency in the data pipeline for near real-time dataprocessing.
As organizations seek greater value from their data, dataarchitectures are evolving to meet the demand — and table formats are no exception. Apache ORC (Optimized Row Columnar) : In 2013, ORC was developed for the Hadoop ecosystem to improve the efficiency of data storage and retrieval.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content