This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A new breed of ‘Fast Data’ architectures has evolved to be stream-oriented, where data is processed as it arrives, providing businesses with a competitive advantage. Dean Wampler (Renowned author of many big data technology-related books) Dean Wampler makes an important point in one of his webinars.
Organizations increasingly rely on streaming data sources not only to bring data into the enterprise but also to perform streaming analytics that accelerate the process of being able to get value from the data early in its lifecycle.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide data lakes versus smaller, typically BU-Specific, “data ponds”.
Its multi-cluster shared dataarchitecture is one of its primary features. Additionally, Fabric has deep integrations with Power BI for visualization and Microsoft Purview for governance, resulting in a smooth experience for both business users and data professionals.
Distributed transactions are very hard to implement successfully, which is why we’ll introduce a log-inspired system such as Apache Kafka ®. Building an indexing pipeline at scale with Kafka Connect. Moving data into Apache Kafka with the JDBC connector. Setting up the connector.
The Current State of the DataArchitecture S3 intelligent tiered storage provides a fine balance between the cost and the duration of the data retention. However, the real-time insight on accessing the recent data remains a big challenge. The combination of stream processing + OLAP storage like Pinot. What is Next?
Anyways, I wasn’t paying enough attention during university classes, and today I’ll walk you through data layers using — guess what — an example. Business Scenario & DataArchitecture Imagine this: next year, a new team on the grid, Red Thunder Racing, will call us (yes, me and you) to set up their new data infrastructure.
This episode promises invaluable insights into the shift from batch to real-time dataprocessing, and the practical applications across multiple industries that make this transition not just beneficial but necessary. Explore the intricate challenges and groundbreaking innovations in data storage and streaming.
This module can ingest live data streams from multiple sources, including Apache Kafka , Apache Flume , Amazon Kinesis , or Twitter, splitting them into discrete micro-batches. Netflix leverages Spark Streaming and Kafka for near real-time movie recommendations. Big dataprocessing.
2: The majority of Flink shops are in earlier phases of maturity We talked to numerous developer teams who had migrated workloads from legacy ETL tools, Kafka streams, Spark streaming, or other tools for the efficiency and speed of Flink. Organizations are moving beyond a Kafka-is-everything mentality when it comes to streaming.
This specialist works closely with people on both business and IT sides of a company to understand the current needs of the stakeholders and help them unlock the full potential of data. To get a better understanding of a data architect’s role, let’s clear up what dataarchitecture is.
The technological linchpin of its digital transformation has been its Enterprise DataArchitecture & Governance platform. It hosts over 150 big data analytics sandboxes across the region with over 200 users utilizing the sandbox for data discovery.
In this context, managing the data, especially when it arrives late, can present a substantial challenge! In this three-part blog post series, we introduce you to Psyberg , our incremental dataprocessing framework designed to tackle such challenges! Let’s dive in! To solve these problems, we came up with Psyberg!
We have partnered with organizations such as O’Reilly Media, Dataversity, Corinium Global Intelligence, Alluxio, and Data Council. Upcoming events include the combined events of the DataArchitecture Summit and Graphorum, the Data Orchestration Summit, and Data Council in NYC.
My challenge with Samza during my time at Slack is the decision to co-locate Samza's state in Kafka. At that time, operating Kafka comes with its challenges. Samza’s stream-stream join relies on Kafka’s key partition to shift the streaming operation burden to Kafka.
😄🎢🚀 High Scalability: Lessons Learned Running Presto At Meta Scale Presto, potentially ranking as one of the most influential open-source initiatives of the past ten years, stands shoulder to shoulder with the likes of Apache Kafka. DuckDB brings an exciting dataarchitecture challenge to the industry.
Can you talk about some of the technology that helps make managing live streaming data possible? Cloudera DataFlow offers the capability for Edge to cloud streaming dataprocessing. This type of end-to-end dataprocessing that starts at the Edge and ends in the cloud is made possible by using Apache NiFi.
Other popular software/frameworks written Scala include Kafka, akka and play. A great quote I read, though somewhat dramatic, articulates this nicely: “ Scala has taken over the world of ‘Fast’ Data ”. An example of how popular Scala based Software can be used within your dataarchitecture is illustrated below.
The Battle for Catalog Supremacy 2024 witnessed intense competition in the catalog space, highlighting the strategic importance of metadata management in modern dataarchitectures. This evolution reflects a broader shift toward scalability, agility, and enhanced governance across data ecosystems.
They are also accountable for communicating data trends. Let us now look at the three major roles of data engineers. Generalists They are typically responsible for every step of the dataprocessing, starting from managing and making analysis and are usually part of small data-focused teams or small companies.
Part of the Data Engineer’s role is to figure out how to best present huge amounts of different data sets in a way that an analyst, scientist, or product manager can analyze. What does a data engineer do? A data engineer is an engineer who creates solutions from raw data.
Introduction Let’s get this out of the way at the beginning: understanding effective streaming dataarchitectures is hard, and understanding how to make use of streaming data for analytics is really hard. Kafka or Kinesis ? Stream processing or an OLAP database? Open source or fully managed?
But with the start of the 21st century, when data started to become big and create vast opportunities for business discoveries, statisticians were rightfully renamed into data scientists. Data scientists today are business-oriented analysts who know how to shape data into answers, often building complex machine learning models.
As a data engineer, a strong understanding of programming, databases, and dataprocessing is necessary. Understanding of Big Data technologies such as Hadoop, Spark, and Kafka. Junior data engineering is the best career option for those just starting in the thriving data engineering field.
As organizations seek greater value from their data, dataarchitectures are evolving to meet the demand — and table formats are no exception. It was designed to support high-volume data exchange and compatibility across different system versions, which is essential for streaming architectures such as Apache Kafka.
Data Engineers must be proficient in Python to create complicated, scalable algorithms. This language provides a solid basis for big dataprocessing and is effective, flexible, and ideal for text analytics. Kafka – Kafka is an open-source framework for processing that can handle real-time data flows.
What is a Big Data Pipeline? Data pipelines have evolved to manage big data, just like many other elements of dataarchitecture. Big data pipelines are data pipelines designed to support one or more of the three characteristics of big data (volume, variety, and velocity).
Data-Arks serves as a vital component in integrating Large Language Models (LLMs) into the analytics workflow, streamlining processes like generating regular metric reports and conducting fraud investigations [link]. link] Lak Lakshmanan: What goes into bronze, silver, and gold layers of a medallion dataarchitecture?
Functional Data Engineering - A Blueprint There has been an uptick in discussion about data modeling in recent years. Maxime Beauchemin wrote an influential article, Functional Data Engineering — a modern paradigm for batch dataprocessing.
Big Data Large volumes of structured or unstructured data. Big DataProcessing In order to extract value or insights out of big data, one must first process it using big dataprocessing software or frameworks, such as Hadoop. Big Query Google’s cloud data warehouse.
With major clients including Spotify, Puma, Five Guys, and Icelandair, Bynder uses large amounts of data to provide dashboards and open APIs to its customers, as well as vital operational insights to internal users. But when the company started to experience rapid growth, it noticed performance issues with its dataarchitecture. “
Data engineers design, manage, test, maintain, store, and work on the data infrastructure that allows easy access to structured and unstructured data. Data engineers need to work with large amounts of data and maintain the architectures used in various data science projects.
Aggregator Leaf Tailer (ALT) is the dataarchitecture favored by web-scale companies, like Facebook, LinkedIn, and Google, for its efficiency and scalability. In this blog post, I will describe the Aggregator Leaf Tailer architecture and its advantages for low-latency dataprocessing and analytics.
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining dataprocessing systems using Microsoft Azure technologies. The popular big data and cloud computing tools Apache Spark , Apache Hive, and Apache Storm are among these.
They work together with stakeholders to get business requirements and develop scalable and efficient dataarchitectures. Role Level Advanced Responsibilities Design and architect data solutions on Azure, considering factors like scalability, reliability, security, and performance.
Organisations are constantly looking for robust and effective platforms to manage and derive value from their data in the constantly changing landscape of data analytics and processing. These platforms provide strong capabilities for dataprocessing, storage, and analytics, enabling companies to fully use their data assets.
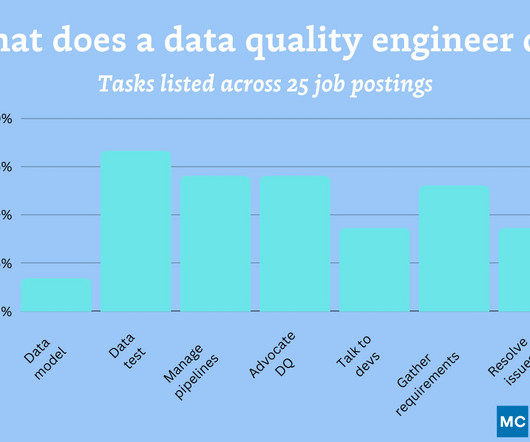
The most common use case data quality engineers support are: Analytical dashboards : Mentioned in 56% of job postings Machine learning or data science teams : Mentioned in 34% of postings Gen AI : Mentioned in one job posting (but really emphatically).
Key Benefits and Takeaways: Understand data intake strategies and data transformation procedures by learning data engineering principles with Python. Investigate alternative data storage solutions, such as databases and data lakes. Key Benefits and Takeaways: Learn the core concepts of big data systems.
Understanding data modeling concepts like entity-relationship diagrams, data normalization, and data integrity is a requirement for an Azure Data Engineer. You ought to be able to create a data model that is performance- and scalability-optimized. The certification cost is $165 USD.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both data lakes and data warehouses and this post will explain this all. What is a data lakehouse? Inability to handle unstructured data such as audio, video, text documents, and social media posts.
5 Data pipeline architecture designs and their evolution The Hadoop era , roughly 2011 to 2017, arguably ushered in big dataprocessing capabilities to mainstream organizations. Data then, and even today for some organizations, was primarily hosted in on-premises databases with non-scalable storage.
Source: The Data Team’s Guide to the Databricks Lakehouse Platform Integrating with Apache Spark and other analytics engines, Delta Lake supports both batch and stream dataprocessing. Besides that, it’s fully compatible with various data ingestion and ETL tools. Databricks focuses on data engineering and data science.
is required to become a Data Science expert. Expert-level knowledge of programming, Big Dataarchitecture, etc., is essential to becoming a Data Engineering professional. Data Engineer vs. Data Scientist A LinkedIn report in 2021 shows data science and data engineering are among the top 15 in-demand jobs.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content