This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A data engineering architecture is the structural framework that determines how data flows through an organization – from collection and storage to processing and analysis. It’s the big blueprint we data engineers follow in order to transform raw data into valuable insights.
A headless dataarchitecture separates datastorage, management, optimization, and access from services that write, process, and query it—creating a single point of access control.
A comparative overview of data warehouses, data lakes, and data marts to help you make informed decisions on datastorage solutions for your dataarchitecture.
Datastorage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
In my recent blog, I researched OLAP technologies, for this post I chose some open-source technologies and used them together to build a full dataarchitecture for a Data Warehouse system. I went with Apache Druid for datastorage, Apache Superset for querying and Apache Airflow as a task orchestrator.
The way to achieve this balance is by moving to a modern dataarchitecture (MDA) that makes it easier to manage, integrate, and govern large volumes of distributed data. When you deploy a platform that supports MDA you can consolidate other systems, like legacy data mediation and disparate datastorage solutions.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. DataStorage Solutions As we all know, data can be stored in a variety of ways.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics.
Introduction to DataArchitectureDataarchitecture shows how data is managed, from collection to transformation to distribution and consumption. It tells about how data flows through the datastorage systems. Dataarchitecture is an important piece of data management.
Prior to making a decision, an organization must consider the Total Cost of Ownership (TCO) for each potential data warehousing solution. On the other hand, cloud data warehouses can scale seamlessly. Vertical scaling refers to the increase in capability of existing computational resources, including CPU, RAM, or storage capacity.
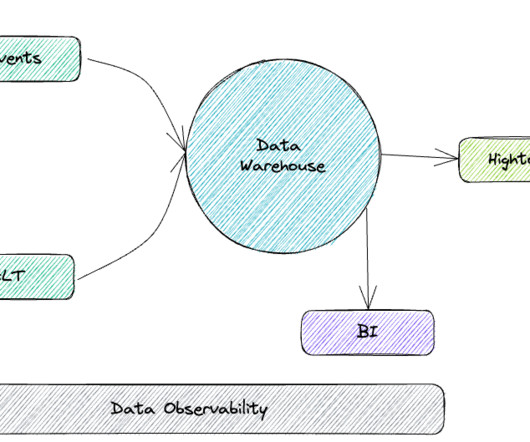
The Current State of the DataArchitecture S3 intelligent tiered storage provides a fine balance between the cost and the duration of the data retention. However, the real-time insight on accessing the recent data remains a big challenge. The combination of stream processing + OLAP storage like Pinot.
Data pipelines are the backbone of your business’s dataarchitecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. Understanding the essential components of data pipelines is crucial for designing efficient and effective dataarchitectures.
Translation: Government agencies — especially those under the Department of Defense (DoD) — have use cases that require datastorage and analytic workloads to be maintained on premises to retain absolute control of data security, privacy, and cost predictability. . It’s here where the private cloud delivers.
I am the first senior machine learning engineer at DataGrail, a company that provides a suite of B2B services helping companies secure and manage their customer data. Data that isn’t interpretable generates little value if any, because you can’t effectively learn from data you don’t understand. Do you keep all data forever?
Concepts, theory, and functionalities of this modern datastorage framework Photo by Nick Fewings on Unsplash Introduction I think it’s now perfectly clear to everybody the value data can have. To use a hyped example, models like ChatGPT could only be built on a huge mountain of data, produced and collected over years.
The Awards showcase IT vendor offerings that provide significant technology advances – and partner growth opportunities – across technology categories including AI and AI infrastructure, cloud management tools, IT infrastructure and monitoring, networking, datastorage, and cybersecurity.
Modern, real-time businesses require accelerated cycles of innovation that are expensive and difficult to maintain with legacy data platforms. The hybrid cloud’s premise—two dataarchitectures fused together—gives companies options to leverage those solutions and to address decision-making criteria, on a case-by-case basis. .
A DataOps architecture is the structural foundation that supports the implementation of DataOps principles within an organization. It encompasses the systems, tools, and processes that enable businesses to manage their data more efficiently and effectively. As a result, they can be slow, inefficient, and prone to errors.
This episode promises invaluable insights into the shift from batch to real-time data processing, and the practical applications across multiple industries that make this transition not just beneficial but necessary. Explore the intricate challenges and groundbreaking innovations in datastorage and streaming.
Additionally, we continue to make product improvements including: Expanding Replication Manager capabilities to cover Apache Ozone object storage, coming later this year, to better support customer disaster recovery requirements around large-scale and dense datastorage.
Empowered by the rise of the modern data stack , leading companies like Warner Music Group , Chime and Petsmart are now turning to the Composable CDP to unlock a modular customer dataarchitecture that centers on the cloud data warehouse. Teams typically turn to dbt for data transformation and modeling needs.
They’re betting their business on it and that the data pipelines that run it will continue to work. Context is crucial (and often lacking) A major cause of data quality issues and pipeline failures are transformations within those pipelines. Most dataarchitecture today is opaque—you can’t tell what’s happening inside.
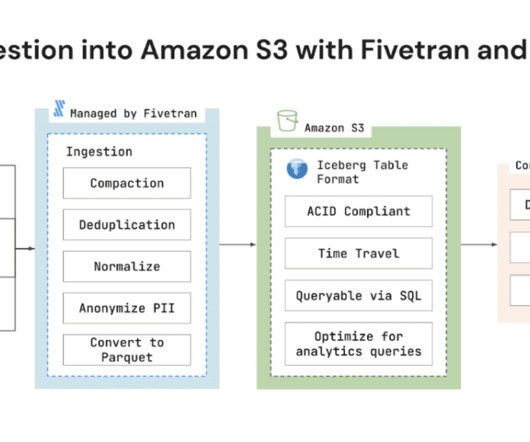
Today we want to introduce Fivetran’s support for Amazon S3 with Apache Iceberg, investigate some of the implications of this feature, and learn how it fits into the modern dataarchitecture as a whole. Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg data lake format.
Here are some role-specific skills you should consider to become an Azure data engineer- Most datastorage and processing systems use programming languages. Data engineers must thoroughly understand programming languages such as Python, Java, or Scala. Who should take the certification exam?
In summary, this model was a tightly-coupled application-to-dataarchitecture, where machine learning algos were mixed with the backend and UI/UX software code stack. It can store and retrieve temporal (timestamp) as well as spatial (coordinates) data.
Job Role 1: Azure Data Engineer Azure Data Engineers develop, deploy, and manage data solutions with Microsoft Azure data services. They use many datastorage, computation, and analytics technologies to develop scalable and robust data pipelines.
This increased the data generation and the need for proper datastorage requirements. A data architect is concerned with designing, creating, deploying, and managing a business entity's dataarchitecture. Due to the post-covid effect, most businesses switched their operations to online mode.
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining data processing systems using Microsoft Azure technologies. As a certified Azure Data Engineer, you have the skills and expertise to design, implement and manage complex datastorage and processing solutions on the Azure cloud platform.
ETL Processes : Knowledge of ETL (Extract, Transform, Load) processes and familiarity with ETL tools like Xplenty, Stitch, and Alooma is essential for efficiently moving and processing data. Data engineers should be proficient in scripting to automate routine data tasks and workflows. The certification cost is $165 USD.
As organizations seek greater value from their data, dataarchitectures are evolving to meet the demand — and table formats are no exception. Apache ORC (Optimized Row Columnar) : In 2013, ORC was developed for the Hadoop ecosystem to improve the efficiency of datastorage and retrieval.
link] Lak Lakshmanan: What goes into bronze, silver, and gold layers of a medallion dataarchitecture? If I understand correctly, the gist of the article is where you position the common data model/ metrics that can be used across the organization. I think these layers are a guiding principle instead of a strict framework.
The migration enhanced data quality, lineage visibility, performance improvements, cost reductions, and better reliability and scalability, setting a robust foundation for future expansions and onboarding.
Data engineer’s integral task is building and maintaining data infrastructure — the system managing the flow of data from its source to destination. This typically includes setting up two processes: an ETL pipeline , which moves data, and a datastorage (typically, a data warehouse ), where it’s kept.
This is particularly valuable in today's data landscape, where information comes in various shapes and sizes. Effective DataStorage: Azure Synapse offers robust datastorage solutions that cater to the needs of modern data-driven organizations.
While working as a big data engineer, there are some roles and responsibilities one has to do: Designing large data systems starts with designing a capable system that can handle large workloads. Develop the algorithms: Once the database is ready, the next thing is to analyze the data to obtain valuable insights.
While working as a big data engineer, there are some roles and responsibilities one has to do: Designing large data systems starts with designing a capable system that can handle large workloads. Develop the algorithms: Once the database is ready, the next thing is to analyze the data to obtain valuable insights.
Part of the Data Engineer’s role is to figure out how to best present huge amounts of different data sets in a way that an analyst, scientist, or product manager can analyze. What does a data engineer do? A data engineer is an engineer who creates solutions from raw data.
Manage datastorage and build dashboards for reporting. Role Level: This role typically falls under the mid-senior to senior level category and requires experience in dataarchitecture principles and cloud technologies. Implement security measures and ensure compliance with regulations.
Here’s how predictive analytics can be effectively integrated into your data strategy: Integrating Predictive Analytics into Your Data Systems Infrastructure Readiness : Ensure your existing dataarchitecture can support the computational demands of AI models.
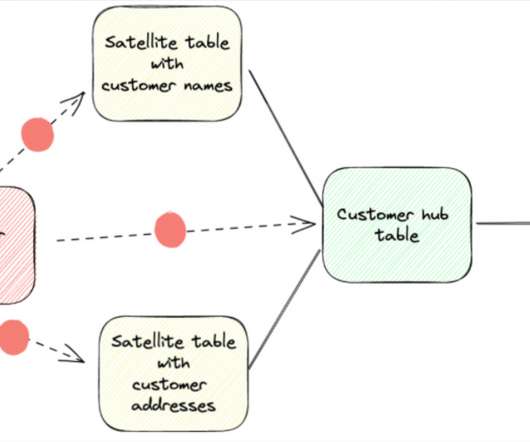
Over the past several years, data warehouses have evolved dramatically, but that doesn’t mean the fundamentals underpinning sound dataarchitecture needs to be thrown out the window. Data vault collects and organizes raw data as underlying structure to act as the source to feed Kimball or Inmon dimensional models.
Let’s understand in detail: Great demand: Azure is one of the most extensively used cloud platforms, and as a result, Azure Data Engineers are in great demand. The demand for talented data professionals who can design, implement, and operate data pipelines and datastorage solutions in the cloud is expanding.
Go for the best courses for Data Engineering and polish your big data engineer skills to take up the following responsibilities: You should have a systematic approach to creating and working on various dataarchitectures necessary for storing, processing, and analyzing large amounts of data.
Big Data Processing In order to extract value or insights out of big data, one must first process it using big data processing software or frameworks, such as Hadoop. Big Query Google’s cloud data warehouse. Data Catalog An organized inventory of data assets relying on metadata to help with data management.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content