This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A data engineering architecture is the structural framework that determines how data flows through an organization – from collection and storage to processing and analysis. It’s the big blueprint we data engineers follow in order to transform raw data into valuable insights.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics.
Striim offers an out-of-the-box adapter for Snowflake to stream real-time data from enterprise databases (using low-impact change data capture ), log files from security devices and other systems, IoT sensors and devices, messaging systems, and Hadoop solutions, and provide in-flight transformation capabilities.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. DataStorage Solutions As we all know, data can be stored in a variety of ways.
Imagine having a framework capable of handling large amounts of data with reliability, scalability, and cost-effectiveness. That's where Hadoop comes into the picture. Hadoop is a popular open-source framework that stores and processes large datasets in a distributed manner. Why Are Hadoop Projects So Important?
Big data has taken over many aspects of our lives and as it continues to grow and expand, big data is creating the need for better and faster datastorage and analysis. These Apache Hadoop projects are mostly into migration, integration, scalability, data analytics, and streaming analysis. Data Migration 2.
Concepts, theory, and functionalities of this modern datastorage framework Photo by Nick Fewings on Unsplash Introduction I think it’s now perfectly clear to everybody the value data can have. To use a hyped example, models like ChatGPT could only be built on a huge mountain of data, produced and collected over years.
Modern, real-time businesses require accelerated cycles of innovation that are expensive and difficult to maintain with legacy data platforms. The hybrid cloud’s premise—two dataarchitectures fused together—gives companies options to leverage those solutions and to address decision-making criteria, on a case-by-case basis. .
Understanding the Hadooparchitecture now gets easier! This blog will give you an indepth insight into the architecture of hadoop and its major components- HDFS, YARN, and MapReduce. We will also look at how each component in the Hadoop ecosystem plays a significant role in making Hadoop efficient for big data processing.
Data engineer’s integral task is building and maintaining data infrastructure — the system managing the flow of data from its source to destination. This typically includes setting up two processes: an ETL pipeline , which moves data, and a datastorage (typically, a data warehouse ), where it’s kept.
Most of the Data engineers working in the field enroll themselves in several other training programs to learn an outside skill, such as Hadoop or Big Data querying, alongside their Master's degree and PhDs. Hadoop Platform Hadoop is an open-source software library created by the Apache Software Foundation.
Without a fixed schema, the data can vary in structure and organization. File systems, data lakes, and Big Data processing frameworks like Hadoop and Spark are often utilized for managing and analyzing unstructured data. You can’t just keep it in SQL databases, unlike structured data.
As organizations seek greater value from their data, dataarchitectures are evolving to meet the demand — and table formats are no exception. The “legacy” table formats The data landscape has evolved so quickly that table formats pioneered within the last 25 years are already achieving “legacy” status.
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining data processing systems using Microsoft Azure technologies. As a certified Azure Data Engineer, you have the skills and expertise to design, implement and manage complex datastorage and processing solutions on the Azure cloud platform.
There are three steps involved in the deployment of a big data model: Data Ingestion: This is the first step in deploying a big data model - Data ingestion, i.e., extracting data from multiple data sources. How is Hadoop related to Big Data? Explain the difference between Hadoop and RDBMS.
Because of this, all businesses—from global leaders like Apple to sole proprietorships—need Data Engineers proficient in SQL. NoSQL – This alternative kind of datastorage and processing is gaining popularity. They’ll come up during your quest for a Data Engineer job, so using them effectively will be quite helpful.
Data engineering involves a lot of technical skills like Python, Java, and SQL (Structured Query Language). For a data engineer career, you must have knowledge of datastorage and processing technologies like Hadoop, Spark, and NoSQL databases. Knowledge of Hadoop, Spark, and Kafka.
While working as a big data engineer, there are some roles and responsibilities one has to do: Designing large data systems starts with designing a capable system that can handle large workloads. Develop the algorithms: Once the database is ready, the next thing is to analyze the data to obtain valuable insights.
While working as a big data engineer, there are some roles and responsibilities one has to do: Designing large data systems starts with designing a capable system that can handle large workloads. Develop the algorithms: Once the database is ready, the next thing is to analyze the data to obtain valuable insights.
Big Data Processing In order to extract value or insights out of big data, one must first process it using big data processing software or frameworks, such as Hadoop. Big Query Google’s cloud data warehouse. Data Catalog An organized inventory of data assets relying on metadata to help with data management.
Go for the best courses for Data Engineering and polish your big data engineer skills to take up the following responsibilities: You should have a systematic approach to creating and working on various dataarchitectures necessary for storing, processing, and analyzing large amounts of data. What is Data Modeling?
You must be able to create ETL pipelines using tools like Azure Data Factory and write custom code to extract and transform data if you want to succeed as an Azure Data Engineer. Big Data Technologies You must explore big data technologies such as Apache Spark, Hadoop, and related Azure services like Azure HDInsight.
Part of the Data Engineer’s role is to figure out how to best present huge amounts of different data sets in a way that an analyst, scientist, or product manager can analyze. What does a data engineer do? A data engineer is an engineer who creates solutions from raw data.
Datasets: RDDs can contain any type of data and can be created from data stored in local filesystems, HDFS (Hadoop Distributed File System), databases, or data generated through transformations on existing RDDs. In scenarios where these conditions are met, Spark can significantly outperform Hadoop MapReduce.
Big Data Engineer performs a multi-faceted role in an organization by identifying, extracting, and delivering the data sets in useful formats. A Big Data Engineer also constructs, tests, and maintains the Big Dataarchitecture. You will get to learn about datastorage and management with lessons on Big Data tools.
Technical Data Engineer Skills 1.Python Python Python is one of the most looked upon and popular programming languages, using which data engineers can create integrations, data pipelines, integrations, automation, and data cleansing and analysis. Knowledge of requirements and knowledge of machine learning libraries.
Big Data Boom: Fast forward to the 2000s, and Big Data crashed onto the scene. Hadoop and Spark: The cavalry arrived in the form of Hadoop and Spark, revolutionizing how we process and analyze large datasets. Suddenly, we were dealing with massive amounts of information, and traditional tools struggled to keep up.
Job Role 1: Azure Data Engineer Azure Data Engineers develop, deploy, and manage data solutions with Microsoft Azure data services. They use many datastorage, computation, and analytics technologies to develop scalable and robust data pipelines.
This increased the data generation and the need for proper datastorage requirements. A data architect is concerned with designing, creating, deploying, and managing a business entity's dataarchitecture. Due to the post-covid effect, most businesses switched their operations to online mode.
Here are some role-specific skills you should consider to become an Azure data engineer- Most datastorage and processing systems use programming languages. Data engineers must thoroughly understand programming languages such as Python, Java, or Scala. Who should take the certification exam?
This is particularly valuable in today's data landscape, where information comes in various shapes and sizes. Effective DataStorage: Azure Synapse offers robust datastorage solutions that cater to the needs of modern data-driven organizations.
ML engineers work in close collaboration with the Data scientists throughout the Data Science pipeline. An ML engineer would require to have robust data modeling and dataarchitecture skills along with programming experience in Python and R.
Key Benefits and Takeaways: Understand data intake strategies and data transformation procedures by learning data engineering principles with Python. Investigate alternative datastorage solutions, such as databases and data lakes. Key Benefits and Takeaways: Learn the core concepts of big data systems.
is required to become a Data Science expert. Expert-level knowledge of programming, Big Dataarchitecture, etc., is essential to becoming a Data Engineering professional. Data Engineer vs. Data Scientist A LinkedIn report in 2021 shows data science and data engineering are among the top 15 in-demand jobs.
In 2010, a transformative concept took root in the realm of datastorage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. Transformation section.
Knowledge of the definition and architecture of AWS Big Data services and their function in the data engineering lifecycle, including data collection and ingestion, data analytics, datastorage, data warehousing, data processing, and data visualization.
Below are some big data interview questions for data engineers based on the fundamental concepts of big data, such as data modeling, data analysis , data migration, data processing architecture, datastorage, big data analytics, etc. Briefly define COSHH.
In this post, we will help you quickly level up your overall knowledge of data pipeline architecture by reviewing: Table of Contents What is data pipeline architecture? Why is data pipeline architecture important? Now Go Build Some Data Pipelines! Schedule a time to talk to us using the form below!
By combining data from various structured and unstructured data systems into structures, Microsoft Azure Data Engineers will be able to create analytics solutions. Why Should You Get an Azure Data Engineer Certification? There are numerous more simple-to-examine programs available, such as Hadoop, Xcode, and Eclipse.
Snowflake provides data warehousing, processing, and analytical solutions that are significantly quicker, simpler to use, and more adaptable than traditional systems. Snowflake is not based on existing database systems or big data software platforms like Hadoop. Let us now understand the Snowflake datastorage layer in detail.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both data lakes and data warehouses and this post will explain this all. What is a data lakehouse? Another type of datastorage — a data lake — tried to address these and other issues.
Develop your dataarchitecture: They design, develop, and manage data structures systematically, even while maintaining them in line with business needs. Automate Workflows: Data Engineers go into the data to identify processes that may be automated to remove manual involvement.
Data Description: You will use the Covid-19 dataset(COVID-19 Cases.csv) from data.world , for this project, which contains a few of the following attributes: people_positive_cases_count county_name case_type data_source Language Used: Python 3.7 Big Data Project using Hadoop with Source Code for Web Server Log Processing 5.
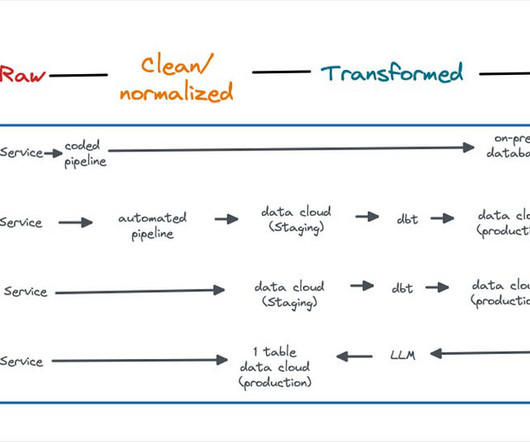
And so it almost seems unfair that new ideas are already springing up to disrupt the disruptors: Zero-ETL has data ingestion in its sights AI and Large Language Models could transform transformation Data product containers are eyeing the table’s thrown as the core building block of data Are we going to have to rebuild everything (again)?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content