This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datastorage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics.
Concepts, theory, and functionalities of this modern datastorage framework Photo by Nick Fewings on Unsplash Introduction I think it’s now perfectly clear to everybody the value data can have. To use a hyped example, models like ChatGPT could only be built on a huge mountain of data, produced and collected over years.
Grab’s Metasense , Uber’s DataK9 , and Meta’s classification systems use AI to automatically categorize vast data sets, reducing manual efforts and improving accuracy. Beyond classification, organizations now use AI for automated metadata generation and data lineage tracking, creating more intelligent data infrastructures.
As organizations seek greater value from their data, dataarchitectures are evolving to meet the demand — and table formats are no exception. At its core, a table format is a sophisticated metadata layer that defines, organizes, and interprets multiple underlying data files.
A DataOps architecture is the structural foundation that supports the implementation of DataOps principles within an organization. It encompasses the systems, tools, and processes that enable businesses to manage their data more efficiently and effectively. As a result, they can be slow, inefficient, and prone to errors.
They’re betting their business on it and that the data pipelines that run it will continue to work. Context is crucial (and often lacking) A major cause of data quality issues and pipeline failures are transformations within those pipelines. Most dataarchitecture today is opaque—you can’t tell what’s happening inside.
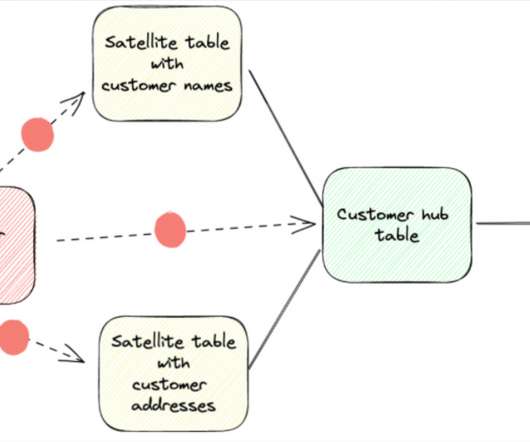
Over the past several years, data warehouses have evolved dramatically, but that doesn’t mean the fundamentals underpinning sound dataarchitecture needs to be thrown out the window. Data vault collects and organizes raw data as underlying structure to act as the source to feed Kimball or Inmon dimensional models.
link] Lak Lakshmanan: What goes into bronze, silver, and gold layers of a medallion dataarchitecture? If I understand correctly, the gist of the article is where you position the common data model/ metrics that can be used across the organization. I think these layers are a guiding principle instead of a strict framework.
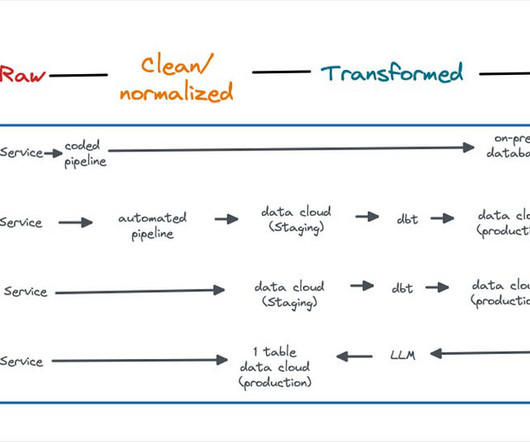
Data engineer’s integral task is building and maintaining data infrastructure — the system managing the flow of data from its source to destination. This typically includes setting up two processes: an ETL pipeline , which moves data, and a datastorage (typically, a data warehouse ), where it’s kept.
In 2010, a transformative concept took root in the realm of datastorage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data.
At the moment, this tight integration is possible because most zero-ETL architectures require both the transactional database and data warehouse to be from the same cloud provider. No duplicate datastorage. Cons : Less ability to customize how the data is treated during the ingestion phase. Pros : Reduced latency.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both data lakes and data warehouses and this post will explain this all. What is a data lakehouse? Another type of datastorage — a data lake — tried to address these and other issues.
Big Query Google’s cloud data warehouse. DataArchitectureDataarchitecture is a composition of models, rules, and standards for all data systems and interactions between them. Data Catalog An organized inventory of data assets relying on metadata to help with data management.
For example, developers can use Twitter API to access and collect public tweets, user profiles, and other data from the Twitter platform. Data ingestion tools are software applications or services designed to collect, import, and process data from various sources into a central datastorage system or repository.
Traditionally, the dimensional data modeling approach is used to build complex data warehouses, while Data Vaults are used in data warehouses to offer long-term historical datastorage while modeling. Why is data modeling important for a data warehouse?
Snowflake in Action at Western Union Snowflake's multi-cluster shared dataarchitecture expanded instantaneously to serve Western Union's data, users, and workloads without causing resource conflict. The query processing layer is separated from the disk storage layer in the Snowflake dataarchitecture.
Technical Data Engineer Skills 1.Python Python Python is one of the most looked upon and popular programming languages, using which data engineers can create integrations, data pipelines, integrations, automation, and data cleansing and analysis.
There are three steps involved in the deployment of a big data model: Data Ingestion: This is the first step in deploying a big data model - Data ingestion, i.e., extracting data from multiple data sources. Data Variety Hadoop stores structured, semi-structured and unstructured data.
Becoming a Big Data Engineer - The Next Steps Big Data Engineer - The Market Demand An organization’s data science capabilities require data warehousing and mining, modeling, data infrastructure, and metadata management. Most of these are performed by Data Engineers.
This may involve assigning data stewards and data custodians and implementing data governance committees. Dataarchitecture and metadata management: It involves establishing a framework for data management, including dataarchitecture and metadata management.
In the age of self-service business intelligence , nearly every company considers themselves a data-first company, but not every company is treating their dataarchitecture with the level of democratization and scalability it deserves. Your company, for one, views data as a driver of innovation.
Role of the most recent component- Hadoop Ozone in Hadoop Application Architecture Implementation Hadoop Big DataArchitecture Design – Best Practices to Follow Latest Version of Hadoop Architecture (Version 3.3.3) Case Studies of Hadoop Architecture Facebook Hadoop Architecture Yahoo Hadoop Architecture Last.FM
However, decentralized models may result in inconsistent and duplicate master data. There’s a centralized structure that provides a framework, which is then used by autonomous departments that own their data and metadata. A Data Architect typically focuses on creating and building data infrastructures inside an organization.
In this post, we will help you quickly level up your overall knowledge of data pipeline architecture by reviewing: Table of Contents What is data pipeline architecture? Why is data pipeline architecture important? Think of an automatically updating encyclopedia for your data platform.
By combining data from various structured and unstructured data systems into structures, Microsoft Azure Data Engineers will be able to create analytics solutions. Why Should You Get an Azure Data Engineer Certification? Data Scientist: To extract value from data, data scientists execute sophisticated analytics.
This approach provides rich context that enables rapid triage and troubleshooting and effective communication with stakeholders impacted by data reliability issues. Datastorage, orchestration, transformation, and BI tiers. Book a time to speak with us using the form below.
When transformations are applied to RDDs, Spark records the metadata to build up a DAG, which reflects the sequence of computations performed during the execution of the Spark job. Apache Mesos : A robust option that manages resources across entire data centers, making it suitable for large-scale, diverse workloads.
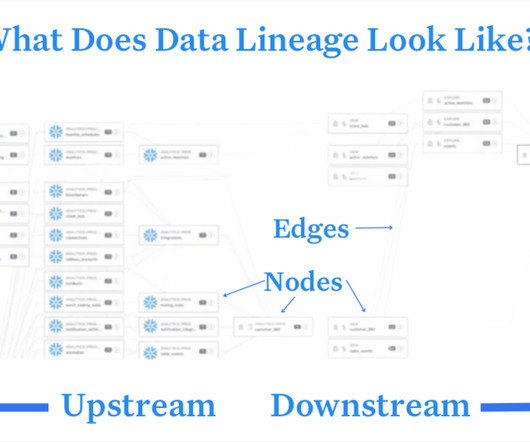
I can surface ownership metadata and alert the relevant owners to make sure the appropriate changes are made so these breakages never happen. Data System Modernization And Team Reorganization The only constant in data engineering is change. This is where data lineage can help you scope and plan your migration waves.
It enables advanced analytics, makes debugging your marketing automations easier, provides natural audit trails for compliance, and allows for flexible, evolving customer data models. So next time you’re designing your customer dataarchitecture in your CDP, don’t just think about the current state of your customers.
Zero Copy Cloning: Create multiple ‘copies’ of tables, schemas, or databases without actually copying the data. This noticeably saves time on copying and drastically reduces datastorage costs. The Solution phData recognized the imperative to enhance both the technical and people aspects of the data platform.
Data lineage is what’s in your database – which is not everything. Data lineage primarily focuses on tracking the movement and transformation of data within the database or datastorage systems. Data lineage is static and often lags by weeks or months. Are problems with data tests? Did it fail?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content