This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A data engineering architecture is the structural framework that determines how data flows through an organization – from collection and storage to processing and analysis. It’s the big blueprint we data engineers follow in order to transform rawdata into valuable insights.
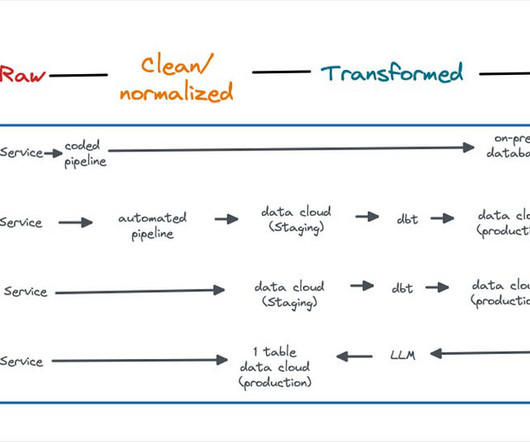
Data pipelines are the backbone of your business’s dataarchitecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. Understanding the essential components of data pipelines is crucial for designing efficient and effective dataarchitectures.
A DataOps architecture is the structural foundation that supports the implementation of DataOps principles within an organization. It encompasses the systems, tools, and processes that enable businesses to manage their data more efficiently and effectively. As a result, they can be slow, inefficient, and prone to errors.
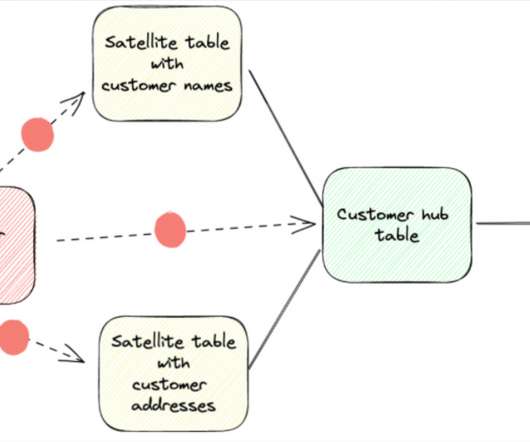
Over the past several years, data warehouses have evolved dramatically, but that doesn’t mean the fundamentals underpinning sound dataarchitecture needs to be thrown out the window. Data vault collects and organizes rawdata as underlying structure to act as the source to feed Kimball or Inmon dimensional models.
A data engineer is an engineer who creates solutions from rawdata. A data engineer develops, constructs, tests, and maintains dataarchitectures. Let’s review some of the big picture concepts as well finer details about being a data engineer. Earlier we mentioned ETL or extract, transform, load.
Businesses benefit at large with these data collection and analysis as they allow organizations to make predictions and give insights about products so that they can make informed decisions, backed by inferences from existing data, which, in turn, helps in huge profit returns to such businesses. What is the role of a Data Engineer?
In 2010, a transformative concept took root in the realm of datastorage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. Rawdata store section.
The emergence of cloud data warehouses, offering scalable and cost-effective datastorage and processing capabilities, initiated a pivotal shift in data management methodologies. Extract The initial stage of the ELT process is the extraction of data from various source systems. What Is ELT? So, what exactly is ELT?
For example, developers can use Twitter API to access and collect public tweets, user profiles, and other data from the Twitter platform. Data ingestion tools are software applications or services designed to collect, import, and process data from various sources into a central datastorage system or repository.
The role can also be defined as someone who has the knowledge and skills to generate findings and insights from available rawdata. Data Engineer A professional who has expertise in data engineering and programming to collect and covert rawdata and build systems that can be usable by the business.
Data Science is also concerned with analyzing, exploring, and visualizing data, thereby assisting the company's growth. As they say, data is the new wave of the 21st century. This increased the data generation and the need for proper datastorage requirements.
Big Data Engineer performs a multi-faceted role in an organization by identifying, extracting, and delivering the data sets in useful formats. A Big Data Engineer also constructs, tests, and maintains the Big Dataarchitecture. The following table illustrates the key differences between these roles.
You feel like the world is your oyster and the possibilities for how your data team can add value to the business is virtually infinite. That’s the beauty of Monte Carlo because it allows us to see who is using data and where it is being consumed. He said: First, get all of your data in one place with the highest fidelity.
Data Science- Definition Data Science is an interdisciplinary branch encompassing data engineering and many other fields. Data Science involves applying statistical techniques to rawdata, just like data analysts, with the additional goal of building business solutions.
Today, when a data professional uses the term “data warehouse” they are likely referring to these cloud solutions that feature architectures with separate compute query engine and datastorage. Data observability eliminates data downtime by applying best practices learned from DevOps to data pipeline observability.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both data lakes and data warehouses and this post will explain this all. What is a data lakehouse? Another type of datastorage — a data lake — tried to address these and other issues.
The practice of designing, building, and maintaining the infrastructure and systems required to collect, process, store, and deliver data to various organizational stakeholders is known as data engineering. You can pace your learning by joining data engineering courses such as the Bootcamp Data Engineer.
Technical Data Engineer Skills 1.Python Python Python is one of the most looked upon and popular programming languages, using which data engineers can create integrations, data pipelines, integrations, automation, and data cleansing and analysis.
In the age of self-service business intelligence , nearly every company considers themselves a data-first company, but not every company is treating their dataarchitecture with the level of democratization and scalability it deserves. Your company, for one, views data as a driver of innovation.
Traditionally, the dimensional data modeling approach is used to build complex data warehouses, while Data Vaults are used in data warehouses to offer long-term historical datastorage while modeling. Why is data modeling important for a data warehouse?
In this post, we will help you quickly level up your overall knowledge of data pipeline architecture by reviewing: Table of Contents What is data pipeline architecture? Why is data pipeline architecture important? Now Go Build Some Data Pipelines! Schedule a time to talk to us using the form below!
Provides Powerful Computing Resources for Data Processing Before inputting data into advanced machine learning models and deep learning tools, data scientists require sufficient computing resources to analyze and prepare it. The query processing layer is separated from the disk storage layer in the Snowflake dataarchitecture.
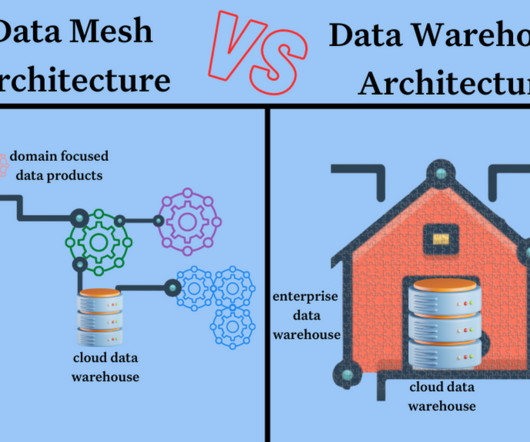
Data pipelines can handle both batch and streaming data, and at a high-level, the methods for measuring data quality for either type of asset are much the same. What is a decentralized dataarchitecture?
Big data operations require specialized tools and techniques since a relational database cannot manage such a large amount of data. Big data enables businesses to gain a deeper understanding of their industry and helps them extract valuable information from the unstructured and rawdata that is regularly collected.
Big data has taken over many aspects of our lives and as it continues to grow and expand, big data is creating the need for better and faster datastorage and analysis. These Apache Hadoop projects are mostly into migration, integration, scalability, data analytics, and streaming analysis.
Below are some big data interview questions for data engineers based on the fundamental concepts of big data, such as data modeling, data analysis , data migration, data processing architecture, datastorage, big data analytics, etc.
It enables advanced analytics, makes debugging your marketing automations easier, provides natural audit trails for compliance, and allows for flexible, evolving customer data models. So next time you’re designing your customer dataarchitecture in your CDP, don’t just think about the current state of your customers.
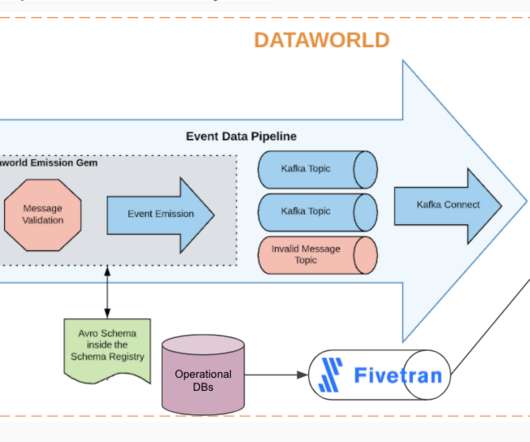
Zero-ETL What it is : A misnomer for one thing; the data pipeline still exists. Today, data is often generated by a service and written into a transactional database. An automatic pipeline is deployed which not only moves the rawdata to the analytical data warehouse, but modifies it slightly along the way.
To build a big data project, you should always adhere to a clearly defined workflow. Before starting any big data project, it is essential to become familiar with the fundamental processes and steps involved, from gathering rawdata to creating a machine learning model to its effective implementation.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content