This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. DataStorage Solutions As we all know, data can be stored in a variety of ways.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics.
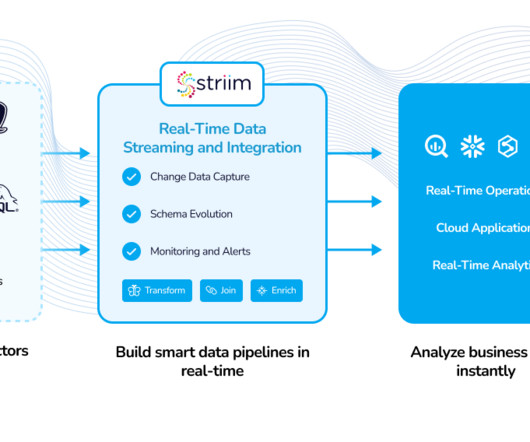
In addition to log files, sensors, and messaging systems, Striim continuously ingests real-time data from cloud-based or on-premises data warehouses and databases such as Oracle, Oracle Exadata, Teradata, Netezza, Amazon Redshift, SQL Server, HPE NonStop, MongoDB, and MySQL.
Data pipelines are the backbone of your business’s dataarchitecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. Understanding the essential components of data pipelines is crucial for designing efficient and effective dataarchitectures.
Concepts, theory, and functionalities of this modern datastorage framework Photo by Nick Fewings on Unsplash Introduction I think it’s now perfectly clear to everybody the value data can have. To use a hyped example, models like ChatGPT could only be built on a huge mountain of data, produced and collected over years.
Data engineer’s integral task is building and maintaining data infrastructure — the system managing the flow of data from its source to destination. This typically includes setting up two processes: an ETL pipeline , which moves data, and a datastorage (typically, a data warehouse ), where it’s kept.
Job Role 1: Azure Data Engineer Azure Data Engineers develop, deploy, and manage data solutions with Microsoft Azure data services. They use many datastorage, computation, and analytics technologies to develop scalable and robust data pipelines.
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining data processing systems using Microsoft Azure technologies. As a certified Azure Data Engineer, you have the skills and expertise to design, implement and manage complex datastorage and processing solutions on the Azure cloud platform.
Organizations across industries moved beyond experimental phases to implement production-ready GenAI solutions within their data infrastructure. Natural Language Interfaces Companies like Uber, Pinterest, and Intuit adopted sophisticated text-to-SQL interfaces, democratizing data access across their organizations.
Here is a step-by-step guide on how to become an Azure Data Engineer: 1. Understanding SQL You must be able to write and optimize SQL queries because you will be dealing with enormous datasets as an Azure Data Engineer. You should possess a strong understanding of data structures and algorithms.
SQL for data migration 2. The role can also be defined as someone who has the knowledge and skills to generate findings and insights from available raw data. The skills that will be necessarily required here is to have a good foundation in programming languages such as SQL, SAS, Python, R.
Microsoft Azure's Azure Synapse, formerly known as Azure SQLData Warehouse, is a complete analytics offering. Designed to tackle the challenges of modern data management and analytics, Azure Synapse brings together the worlds of big data and data warehousing into a unified and seamlessly integrated platform.
link] Grab: Leveraging RAG-powered LLMs for Analytical Tasks Grab writes about Data-Arks, an internal platform that houses frequently used SQL queries and Python functions. link] Lak Lakshmanan: What goes into bronze, silver, and gold layers of a medallion dataarchitecture?
Here are some role-specific skills you should consider to become an Azure data engineer- Most datastorage and processing systems use programming languages. Data engineers must thoroughly understand programming languages such as Python, Java, or Scala. Who should take the certification exam?
A data engineer develops, constructs, tests, and maintains dataarchitectures. Let’s review some of the big picture concepts as well finer details about being a data engineer. What does a data engineer do – the big picture Data engineers will often be dealing with raw data.
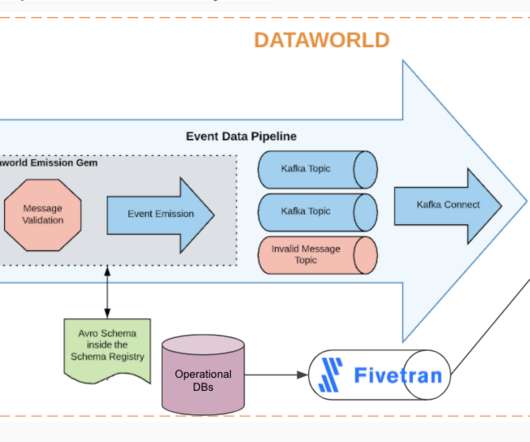
As organizations seek greater value from their data, dataarchitectures are evolving to meet the demand — and table formats are no exception. It was designed to support high-volume data exchange and compatibility across different system versions, which is essential for streaming architectures such as Apache Kafka.
Data Engineers are engineers responsible for uncovering trends in data sets and building algorithms and data pipelines to make raw data beneficial for the organization. This job requires a handful of skills, starting from a strong foundation of SQL and programming languages like Python , Java , etc.
A fixed schema means the structure and organization of the data are predetermined and consistent. It is commonly stored in relational database management systems (DBMSs) such as SQL Server, Oracle, and MySQL, and is managed by data analysts and database administrators. Data durability and availability.
Go for the best courses for Data Engineering and polish your big data engineer skills to take up the following responsibilities: You should have a systematic approach to creating and working on various dataarchitectures necessary for storing, processing, and analyzing large amounts of data.
Skills Required To Be A Data Engineer. SQL – A database may be used to build data warehousing, combine it with other technologies, and analyze the data for commercial reasons with the help of strong SQL abilities. NoSQL – This alternative kind of datastorage and processing is gaining popularity.
Key Benefits and Takeaways: Understand data intake strategies and data transformation procedures by learning data engineering principles with Python. Investigate alternative datastorage solutions, such as databases and data lakes. Key Benefits and Takeaways: Learn the core concepts of big data systems.
Technical Data Engineer Skills 1.Python Python Python is one of the most looked upon and popular programming languages, using which data engineers can create integrations, data pipelines, integrations, automation, and data cleansing and analysis. ETL is central to getting your data where you need it.
Candidates must, however, be proficient in programming concepts and SQL syntax prior to starting the Azure certification training. Additionally, for a job in data engineering, candidates should have actual experience with distributed systems, data pipelines, and related database concepts.
Big Data Engineer performs a multi-faceted role in an organization by identifying, extracting, and delivering the data sets in useful formats. A Big Data Engineer also constructs, tests, and maintains the Big Dataarchitecture. You must have good knowledge of the SQL and NoSQL database systems.
A data warehouse can store vast amounts of data from numerous sources in a single location, run queries and perform analyses to help businesses optimize their operations. Its analytical skills enable companies to gain significant insights from their data and make better decisions.
While working as a big data engineer, there are some roles and responsibilities one has to do: Designing large data systems starts with designing a capable system that can handle large workloads. Develop the algorithms: Once the database is ready, the next thing is to analyze the data to obtain valuable insights.
While working as a big data engineer, there are some roles and responsibilities one has to do: Designing large data systems starts with designing a capable system that can handle large workloads. Develop the algorithms: Once the database is ready, the next thing is to analyze the data to obtain valuable insights.
The primary process comprises gathering data from multiple sources, storing it in a database to handle vast quantities of information, cleaning it for further use and presenting it in a comprehensible manner. Data engineering involves a lot of technical skills like Python, Java, and SQL (Structured Query Language).
This increased the data generation and the need for proper datastorage requirements. A data architect is concerned with designing, creating, deploying, and managing a business entity's dataarchitecture. Due to the post-covid effect, most businesses switched their operations to online mode.
It offers scalable storage, powerful computation, and the ability to handle multiple tasks simultaneously. Hadoop can store data and run applications on cost-effective hardware clusters. Its dataarchitecture is flexible, relevant, and schema-free. To learn more about this topic, explore our Big Data and Hadoop course.
DataArchitecture and Design: These experts excel in creating effective data structures that meet scalability requirements, ensure optimal datastorage, processing, and retrieval, and correspond with business demands. Azure Data Factory stands at the forefront, orchestrating data workflows.
They highlight competence in data management, a pivotal requirement in today's business landscape, making certified individuals a sought-after asset for employers aiming to efficiently handle, safeguard, and optimize data operations. Skills acquired : Core data concepts. Datastorage options.
There are three steps involved in the deployment of a big data model: Data Ingestion: This is the first step in deploying a big data model - Data ingestion, i.e., extracting data from multiple data sources. Data Variety Hadoop stores structured, semi-structured and unstructured data.
Spark SQL brings native support for SQL to Spark and streamlines the process of querying semistructured and structured data. Besides SQL syntax, it supports Hive Query Language, which enables interaction with Hive tables. Data analysis. It works with various formats, including Avro, Parquet, ORC, and JSON.
Big Data Processing In order to extract value or insights out of big data, one must first process it using big data processing software or frameworks, such as Hadoop. Big Query Google’s cloud data warehouse. Data Catalog An organized inventory of data assets relying on metadata to help with data management.
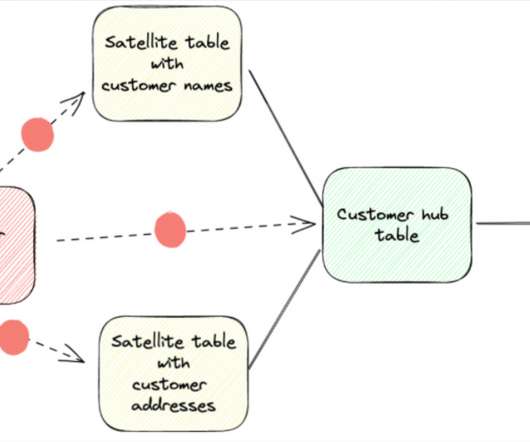
Over the past several years, data warehouses have evolved dramatically, but that doesn’t mean the fundamentals underpinning sound dataarchitecture needs to be thrown out the window. Data vault collects and organizes raw data as underlying structure to act as the source to feed Kimball or Inmon dimensional models.
In 2010, a transformative concept took root in the realm of datastorage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. Semi-structured data sources.
An Azure Data Engineer is a professional specializing in designing, implementing, and managing data solutions on the Microsoft Azure cloud platform. They possess expertise in various aspects of data engineering. As an Azure data engineer myself, I was responsible for managing datastorage, processing, and analytics.
An Azure Data Engineer is a professional specializing in designing, implementing, and managing data solutions on the Microsoft Azure cloud platform. They possess expertise in various aspects of data engineering. As an Azure data engineer myself, I was responsible for managing datastorage, processing, and analytics.
In this post, we will help you quickly level up your overall knowledge of data pipeline architecture by reviewing: Table of Contents What is data pipeline architecture? Why is data pipeline architecture important? Now Go Build Some Data Pipelines! Schedule a time to talk to us using the form below!
Manage datastorage and build dashboards for reporting. Role Level: This role typically falls under the mid-senior to senior level category and requires experience in dataarchitecture principles and cloud technologies. You should also be proficient in SQL and scripting languages like Python or R.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both data lakes and data warehouses and this post will explain this all. What is a data lakehouse? Data warehouse vs data lake vs data lakehouse: What’s the difference. Data lake.
Data consistency is ensured through uniform definitions and governance requirements across the organization, and a comprehensive communication layer allows other teams to discover the data they need. To address this problem, using a data mesh and tangential Data Mesh dataarchitectures are rising in popularity.
You feel like the world is your oyster and the possibilities for how your data team can add value to the business is virtually infinite. For example, one healthcare company we work with was ingesting hundreds of files from healthcare providers a day and their.net applications on their SQL server couldn’t handle the compute for critical tasks.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content