This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A comparative overview of datawarehouses, data lakes, and data marts to help you make informed decisions on data storage solutions for your dataarchitecture.
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to dataarchitecture and structured data management that really hit its stride in the early 1990s.
More than 50% of data leaders recently surveyed by BCG said the complexity of their dataarchitecture is a significant pain point in their enterprise. As a result,” says BCG, “many companies find themselves at a tipping point, at risk of drowning in a deluge of data, overburdened with complexity and costs.”
It’s not enough for businesses to implement and maintain a dataarchitecture. The unpredictability of market shifts and the evolving use of new technologies means businesses need more data they can trust than ever to stay agile and make the right decisions.
What used to be bespoke and complex enterprise data integration has evolved into a modern dataarchitecture that orchestrates all the disparate data sources intelligently and securely, even in a self-service manner: a data fabric. Cloudera data fabric and analyst acclaim. Next steps.
Summary Datawarehouses have gone through many transformations, from standard relational databases on powerful hardware, to column oriented storage engines, to the current generation of cloud-native analytical engines. If you are evaluating your options for building or migrating a data platform, then this is definitely worth a listen.
Summary Managing a datawarehouse can be challenging, especially when trying to maintain a common set of patterns. We have partnered with organizations such as O’Reilly Media, Dataversity, Corinium Global Intelligence, Alluxio, and Data Council.
Rethinking data warehousing: Why redefinition is necessary even beyond Modern DataWarehouse (MDW) and Lakehouse Models Continue reading on Towards Data Science »
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. Each of these architectures has its own unique strengths and tradeoffs. Want to see these features in action?
Summary The market for datawarehouse platforms is large and varied, with options for every use case. We have partnered with organizations such as O’Reilly Media, Dataversity, and the Open Data Science Conference. Coming up this fall is the combined events of Graphorum and the DataArchitecture Summit.
A fundamental challenge with today’s “data explosion” is finding the best answer to the question, “So where do I put my data?” while avoiding the longer-term problem of datawarehouses, […].
Data storage has been evolving, from databases to datawarehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Modern dataarchitectures. To eliminate or integrate these silos, the public sector needs to adopt robust data management solutions that support modern dataarchitectures (MDAs). Deploying modern dataarchitectures. Lack of sharing hinders the elimination of fraud, waste, and abuse. Forrester ).
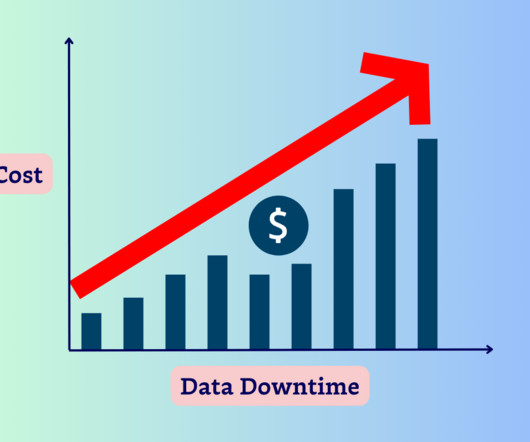
Our calculator estimates the cost of this poor data quality would be: 400 data incidents per year 2400 data downtime hours per year $156,587 in resource cost $2,671,232 in efficiency cost The Data Quality Calculator provides the estimated cost of bad data by leveraging data from hundreds of datawarehouses and millions of tables.
Nowadays, when it comes to data management, every business has to make one critical decision: whether to use a Data Mesh or a DataWarehouse. Both are strong data management architectures, but they are designed to support different needs and various organizational structures.
However, this is still not common in the DataWarehouse (DWH) field. In my recent blog, I researched OLAP technologies, for this post I chose some open-source technologies and used them together to build a full dataarchitecture for a DataWarehouse system. These days, everyone talks about open-source.
Each of these trends claim to be complete models for their dataarchitectures to solve the “everything everywhere all at once” problem. Data teams are confused as to whether they should get on the bandwagon of just one of these trends or pick a combination. First, we describe how data mesh and data fabric could be related.
With instant elasticity, high-performance, and secure data sharing across multiple clouds , Snowflake has become highly in-demand for its cloud-based datawarehouse offering. As organizations adopt Snowflake for business-critical workloads, they also need to look for a modern data integration approach.
CDC tools fuel analytical apps and mission-critical data feeds in banking and regulated industries, with use cases ranging from data synchronization, managing risk, and preventing fraud to driving personalization. This approach simplifies dataarchitecture and enhances performance by reducing data movement and latency.
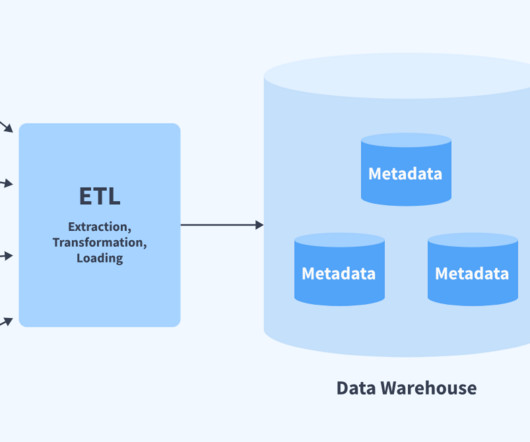
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
When I heard the words ‘decentralised dataarchitecture’, I was left utterly confused at first! In my then limited experience as a Data Engineer, I had only come across centralised dataarchitectures and they seemed to be working very well. Result: Datawarehouse was born. So what was missing?
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Data Storage Solutions As we all know, data can be stored in a variety of ways.
This includes modeling the lifecycle of your information as a pipeline from the raw, messy, loosely structured records in your data lake, through a series of transformations and ultimately to your datawarehouse. Can you walk through the stages of an ideal lifecycle for data within the context of an organizations uses for it?
The datawarehouse is the foundation of the modern data stack, so it caught our attention when we saw Convoy head of data Chad Sanderson declare, “ the datawarehouse is broken ” on LinkedIn. Treating data like an API. Immutable datawarehouses have challenges too.
Sign up free at dataengineeringpodcast.com/rudderstack - Your host is Tobias Macey and today I'm interviewing Satish Jayanthi about the practice and promise of building a column-aware dataarchitecture through intentional modeling Interview Introduction How did you get involved in the area of data management?
Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : Cloud Datawarehouses like Snowflake and Big Query already have a default time travel feature. FAQs What is a Data Lakehouse?
Anyways, I wasn’t paying enough attention during university classes, and today I’ll walk you through data layers using — guess what — an example. Business Scenario & DataArchitecture Imagine this: next year, a new team on the grid, Red Thunder Racing, will call us (yes, me and you) to set up their new data infrastructure.
Over the course of this journey, HomeToGo’s data needs have evolved considerably. It also came with other advantages such as independence of cloud infrastructure providers, data recovery features such as Time Travel , and zero copy cloning which made setting up several environments — such as dev, stage or production — way more efficient.
Summary The flexibility of software oriented data workflows is useful for fulfilling complex requirements, but for simple and repetitious use cases it adds significant complexity. Coalesce is a platform designed to reduce repetitive work for common workflows by adopting a visual pipeline builder to support your datawarehouse transformations.
The data mesh design pattern breaks giant, monolithic enterprise dataarchitectures into subsystems or domains, each managed by a dedicated team. The past decades of enterprise data platform architectures can be summarized in 69 words. Introduction to Data Mesh. Source: Thoughtworks.
Gone are the days of just dumping everything into a single database; modern dataarchitectures typically use a combination of data lakes and warehouses. Think of your data lake as a vast reservoir where you store raw data in its original form—great for when you’re not quite sure how you’ll use it yet.
Data pipelines are the backbone of your business’s dataarchitecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. Understanding the essential components of data pipelines is crucial for designing efficient and effective dataarchitectures.
Organizations have begun to built datawarehouses and lakes to analyze large amounts of data for insights and business reports. Often time they bring data from multiple data silos into their data lake and also have data stored in particular data stores like NoSQL databases to support different use cases.
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise datawarehouses. In recent years, the term “data lakehouse” was coined to describe this architectural pattern of tabular analytics over data in the data lake.
In this Q&A, we hear from Nico Acosta, CEO and Co-Founder of Propel, about how his company is building an API platform to equip developers to build with data, and why dataarchitecture is the most important technical decision a company will make. We fully align with Snowflake’s vision of the Data Cloud.
For the same cost, organizations can now store 50 times as much data as in a Hadoop data lake than in a datawarehouse. Data lake is gaining momentum across various organizations and everyone wants to know how to implement a data lake and why.
This conversation was useful for getting a better idea of the challenges that exist in large scale data analytics, and the current state of the tradeoffs between data lakes and datawarehouses in the cloud. Coming up this fall is the combined events of Graphorum and the DataArchitecture Summit.
In this context, data management in an organization is a key point for the success of its projects involving data. One of the main aspects of correct data management is the definition of a dataarchitecture. The Lakehouse architecture was one of them.
Summary Data lakes have been gaining popularity alongside an increase in their sophistication and usability. Despite improvements in performance and dataarchitecture they still require significant knowledge and experience to deploy and manage. The data you’re looking for is already in your datawarehouse and BI tools.
Datafold also helps automate regression testing of ETL code with its Data Diff feature that instantly shows how a change in ETL or BI code affects the produced data, both on a statistical level and down to individual rows and values. What are the driving factors for building a real-time data platform?
By running datawarehouse and data engineering workloads on Snowflake’s Data Cloud Ramp improves performance and user experience, while delivering powerful insights to customers quickly. How do you scale seamlessly, without worrying about keeping the lights on?
Companies, on the other hand, have continued to demand highly scalable and flexible analytic engines and services on the data lake, without vendor lock-in. Organizations want modern dataarchitectures that evolve at the speed of their business and we are happy to support them with the first open data lakehouse. .
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content