This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
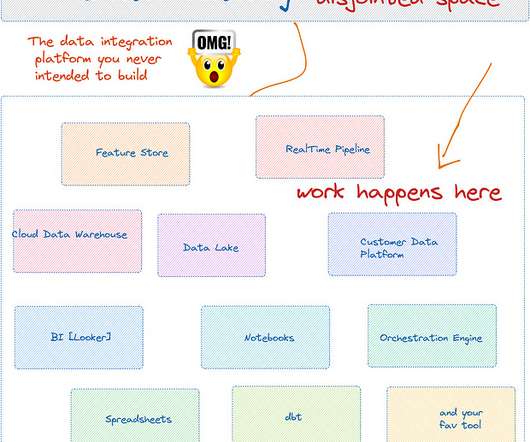
era of Data Catalog Let’s call the pre-modern era; as the state of DataWarehouses before the explosion of big data and subsequent cloud datawarehouse adoption. Applications deployed in a large monolithic web server with all the datawarehouse changes go through a central dataarchitecture team.
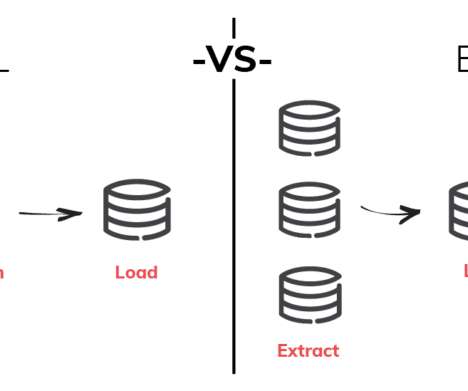
The last three years have seen a remarkable change in data infrastructure. ETL changed towards ELT. Now, data teams are embracing a new approach: reverse ETL. Cloud datawarehouses, such as Snowflake and BigQuery, have made it simpler than ever to combine all of your data into one location.
Data engineer’s integral task is building and maintaining data infrastructure — the system managing the flow of data from its source to destination. This typically includes setting up two processes: an ETL pipeline , which moves data, and a data storage (typically, a datawarehouse ), where it’s kept.
In the dynamic world of data, many professionals are still fixated on traditional patterns of data warehousing and ETL, even while their organizations are migrating to the cloud and adopting cloud-native data services. Modern platforms like Redshift , Snowflake , and BigQuery have elevated the datawarehouse model.
They work together with stakeholders to get business requirements and develop scalable and efficient dataarchitectures. Role Level Advanced Responsibilities Design and architect data solutions on Azure, considering factors like scalability, reliability, security, and performance.
2: The majority of Flink shops are in earlier phases of maturity We talked to numerous developer teams who had migrated workloads from legacy ETLtools, Kafka streams, Spark streaming, or other tools for the efficiency and speed of Flink. For now, Flink plus Iceberg is the compute plus storage solution for streaming data.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a datawarehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
By letting you query data directly in the lake without the need for movement, Synapse cuts down the storage costs and eliminates data duplication. This capability fosters a more flexible dataarchitecture where data can be processed and analyzed in its raw form. Is Azure Synapse an ETLtool?
Database Knowledge Data warehousing ideas like the star and snowflake schema, as well as how to design and develop a datawarehouse, should be well understood by you. This involves knowing how to manage data partitions, load data into a datawarehouse, and speed up query execution.
For small companies, the data engineer holds a generalist position where he basically does all it. In big organizations, they would focus on pipeline building or play a DataWarehouse Manager. Why Choose Data Engineering as a Career? Big Data Technologies: Aware of Hadoop, Spark, and other platforms for big data.
While working as a big data engineer, there are some roles and responsibilities one has to do: Designing large data systems starts with designing a capable system that can handle large workloads. Develop the algorithms: Once the database is ready, the next thing is to analyze the data to obtain valuable insights.
While working as a big data engineer, there are some roles and responsibilities one has to do: Designing large data systems starts with designing a capable system that can handle large workloads. Develop the algorithms: Once the database is ready, the next thing is to analyze the data to obtain valuable insights.
The term data lake itself is metaphorical, evoking an image of a large body of water fed by multiple streams, each bringing new data to be stored and analyzed. Instead of relying on traditional hierarchical structures and predefined schemas, as in the case of datawarehouses, a data lake utilizes a flat architecture.
Technical Data Engineer Skills 1.Python Python Python is one of the most looked upon and popular programming languages, using which data engineers can create integrations, data pipelines, integrations, automation, and data cleansing and analysis. Data mining tools are based on advanced statistical modeling techniques.
Additionally, for a job in data engineering, candidates should have actual experience with distributed systems, data pipelines, and related database concepts. Students have the chance to put Azure data solutions into practice with the Microsoft Azure DP-203 certification training.
Generally, data pipelines are created to store data in a datawarehouse or data lake or provide information directly to the machine learning model development. Keeping data in datawarehouses or data lakes helps companies centralize the data for several data-driven initiatives.
Big Data Engineer performs a multi-faceted role in an organization by identifying, extracting, and delivering the data sets in useful formats. A Big Data Engineer also constructs, tests, and maintains the Big Dataarchitecture. Your organization will use internal and external sources to port the data.
But if the right tools and services are employed, a lot of time is saved and the process is made easy. Indeed, one of the solutions that has evolved into a best practice for organizations actively seeking a way to update the organization’s dataarchitecture is the AWS Database Migration Service, or AWS DMS abbreviation.
ETL (extract, transform, and load) techniques move data from databases and other systems into a single hub, such as a datawarehouse. Get familiar with popular ETLtools like Xplenty, Stitch, Alooma, etc. Different methods are used to store different types of data.
The process of data modeling begins with stakeholders providing business requirements to the data engineering team. Prepare for Your Next Big Data Job Interview with Kafka Interview Questions and Answers How is a datawarehouse different from an operational database? Data is regularly updated.
It enables advanced analytics, makes debugging your marketing automations easier, provides natural audit trails for compliance, and allows for flexible, evolving customer data models. So next time you’re designing your customer dataarchitecture in your CDP, don’t just think about the current state of your customers.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content