This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Data Storage Solutions As we all know, data can be stored in a variety of ways.
Over the course of this journey, HomeToGo’s data needs have evolved considerably. It also came with other advantages such as independence of cloud infrastructure providers, data recovery features such as Time Travel , and zero copy cloning which made setting up several environments — such as dev, stage or production — way more efficient.
Data organizations often have a mix of centralized and decentralized activity. DataOps concerns itself with the complex flow of data across teams, data centers and organizational boundaries. It expands beyond tools and dataarchitecture and views the data organization from the perspective of its processes and workflows.
Key Takeaways Data Fabric is a modern dataarchitecture that facilitates seamless data access, sharing, and management across an organization. Data management recommendations and data products emerge dynamically from the fabric through automation, activation, and AI/ML analysis of metadata.
It’s our goal at Monte Carlo to provide data observability and quality across the enterprise by monitoring every system vital in the delivery of data from source to consumption. We started with popular modern datawarehouses and quickly expanded our support as data lakes became data lakehouses.
During this transformation, Airbnb experienced the typical growth challenges that most companies do, including those that affect the datawarehouse. In the first post of this series, we shared an overview of how we evolved our organization and technology standards to address the dataquality challenges faced during hyper growth.
Understanding the “rise of data downtime” With a greater focus on monetizing data coupled with the ever present desire to increase data accuracy, we need to better understand some of the factors that can lead to data downtime. We’ll take a closer look at variables that can impact your data next.
They need high-qualitydata in an answer-ready format to address many scenarios with minimal keyboarding. What they are getting from IT and other data sources is, in reality, poor-qualitydata in a format that requires manual customization. DataOps Process Hub.
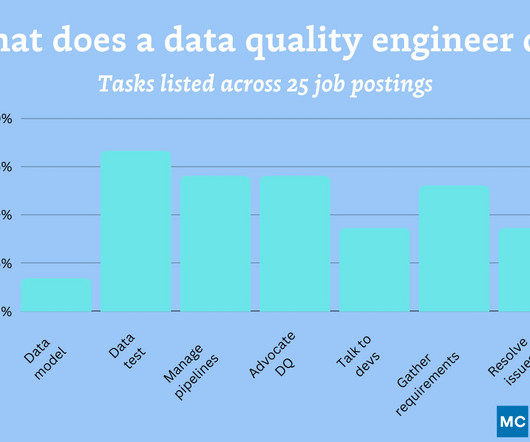
These specialists are also commonly referred to as data reliability engineers. To be successful in their role, dataquality engineers will need to gather dataquality requirements (mentioned in 65% of job postings) from relevant stakeholders.
This year data observability skyrocketed to the top of the Gartner’s Hype Cycles. According to Gartner, 50% of enterprise companies implementing distributed dataarchitectures will have adopted data observability tools by 2026 – up from just ~20% in 2024. Image courtesy of Gartner.
While data engineering and Artificial Intelligence (AI) may seem like distinct fields at first glance, their symbiosis is undeniable. The foundation of any AI system is high-qualitydata. Here lies the critical role of data engineering: preparing and managing data to feed AI models.
If you actually try to look at [schema changes or anomalies] manually in your entire datawarehouse, that’s what takes so much effort to actually capture. Monte Carlo helped the Checkout.com data team combat those challenges. “ML-based anomaly detection beats manual threshold basically any day of the week,” says Martynas. “If
For example, when you think about a datawarehouse , it’s really just a codebase—primarily composed of SQL—that’s serving internal customers like other analysts, data scientists, and product managers who are using that data to go and make business decisions. If data is your product, then it needs to be highquality.
Supporting all of this requires a modern infrastructure and dataarchitecture with appropriate governance. DataOps helps ensure organizations make decisions based on sound data. Enter DataOps. In doing so, it allows teams to identify problems faster and, therefore, deliver solutions faster. Who’s Involved in a DataOps Team?
Their artificial intelligence data-driven platform relies on high-qualitydata to make coverage recommendations for customers. While a lot has changed in five years, one thing has always remained the same: the company’s commitment to building an insights-driven culture based on accurate and reliable data.
DataWarehouse (Or Lakehouse) Migration 34. Integrate Data Stacks Post Merger 35. Know When To Fix Vs. Refactor Data Pipelines Improve DataOps Processes 37. “We Another common breaking schema change scenario is when data teams sync their production database with their datawarehouse as is the case with Freshly.
Datawarehouse (or Lakehouse) migration 34. Integrate Data Stacks Post Merger 35. Know When To Fix Vs. Refactor Data Pipelines Improve DataOps Processes 37. “We Another common breaking schema change scenario is when data teams sync their production database with their datawarehouse as is the case with Freshly.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content