This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data storage has been evolving, from databases to datawarehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. Each of these architectures has its own unique strengths and tradeoffs.
Summary Managing a datawarehouse can be challenging, especially when trying to maintain a common set of patterns. We have partnered with organizations such as O’Reilly Media, Dataversity, Corinium Global Intelligence, Alluxio, and Data Council.
Modern dataarchitectures. To eliminate or integrate these silos, the public sector needs to adopt robust data management solutions that support modern dataarchitectures (MDAs). Deploying modern dataarchitectures. Lack of sharing hinders the elimination of fraud, waste, and abuse. Forrester ).
First, we create an Iceberg table in Snowflake and then insert some data. Then, we add another column called HASHKEY , add more data, and locate the S3 file containing metadata for the iceberg table. In the screenshot below, we can see that the metadata file for the Iceberg table retains the snapshot history.
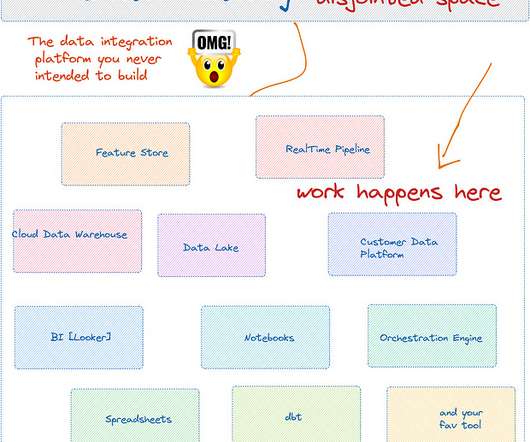
Each of these trends claim to be complete models for their dataarchitectures to solve the “everything everywhere all at once” problem. Data teams are confused as to whether they should get on the bandwagon of just one of these trends or pick a combination. First, we describe how data mesh and data fabric could be related.
Sign up free at dataengineeringpodcast.com/rudderstack - Your host is Tobias Macey and today I'm interviewing Satish Jayanthi about the practice and promise of building a column-aware dataarchitecture through intentional modeling Interview Introduction How did you get involved in the area of data management?
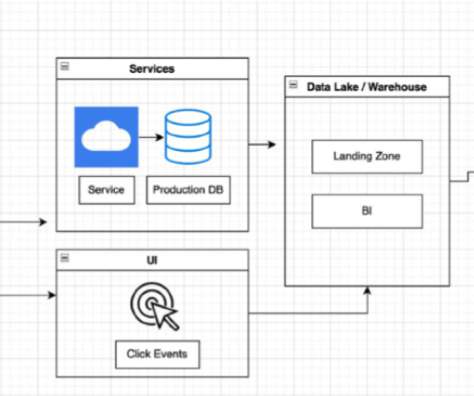
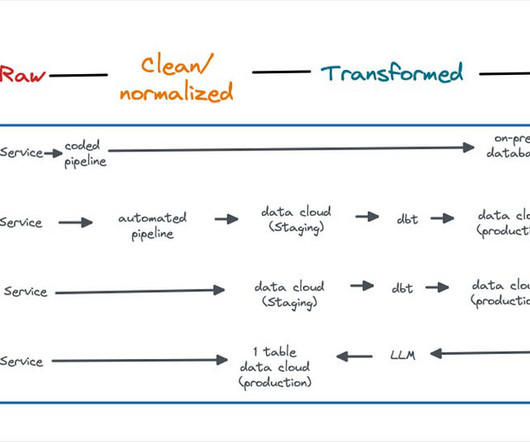
This includes modeling the lifecycle of your information as a pipeline from the raw, messy, loosely structured records in your data lake, through a series of transformations and ultimately to your datawarehouse. Can you walk through the stages of an ideal lifecycle for data within the context of an organizations uses for it?
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their data pipelines and analytical code.
The datawarehouse is the foundation of the modern data stack, so it caught our attention when we saw Convoy head of data Chad Sanderson declare, “ the datawarehouse is broken ” on LinkedIn. Treating data like an API. Immutable datawarehouses have challenges too.
The data mesh design pattern breaks giant, monolithic enterprise dataarchitectures into subsystems or domains, each managed by a dedicated team. The past decades of enterprise data platform architectures can be summarized in 69 words. Introduction to Data Mesh. Source: Thoughtworks.
With Cloudera’s vision of hybrid data , enterprises adopting an open data lakehouse can easily get application interoperability and portability to and from on premises environments and any public cloud without worrying about data scaling. Why integrate Apache Iceberg with Cloudera Data Platform?
These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise datawarehouses. In recent years, the term “data lakehouse” was coined to describe this architectural pattern of tabular analytics over data in the data lake.
Data Catalog as a passive web portal to display metadata requires significant rethinking to adopt modern data workflow, not just adding “modern” in its prefix. I know that is an expensive statement to make😊 To be fair, I’m a big fan of data catalogs, or metadata management , to be precise.
In this context, data management in an organization is a key point for the success of its projects involving data. One of the main aspects of correct data management is the definition of a dataarchitecture. The Lakehouse architecture was one of them. show() The history object is a Spark Data Frame.
This specialist works closely with people on both business and IT sides of a company to understand the current needs of the stakeholders and help them unlock the full potential of data. To get a better understanding of a data architect’s role, let’s clear up what dataarchitecture is.
But it isn’t just aggregating data for models. Data needs to be prepared and analyzed. Different data types need different types of analytics – real-time, streaming, operational, datawarehouses. And that data is likely in clouds, in data centers and at the edge.
As part of this movement, Fivetran and dbt fundamentally altered the data pipeline from ETL to ELT. Hightouch interrupted SaaS eating the world in an attempt to shift the center of gravity to the datawarehouse. Other common light transformations done within the ingestion phase are data formatting and deduplication.
Key Takeaways Data Fabric is a modern dataarchitecture that facilitates seamless data access, sharing, and management across an organization. Data management recommendations and data products emerge dynamically from the fabric through automation, activation, and AI/ML analysis of metadata.
The consumption of the data should be supported through an elastic delivery layer that aligns with demand, but also provides the flexibility to present the data in a physical format that aligns with the analytic application, ranging from the more traditional datawarehouse view to a graph view in support of relationship analysis.
As organizations seek greater value from their data, dataarchitectures are evolving to meet the demand — and table formats are no exception. At its core, a table format is a sophisticated metadata layer that defines, organizes, and interprets multiple underlying data files.
This might include processes like data extraction from different sources, data cleansing, data transformation (like aggregation), and loading the data into a database or a datawarehouse. They’re betting their business on it and that the data pipelines that run it will continue to work.
Data engineer’s integral task is building and maintaining data infrastructure — the system managing the flow of data from its source to destination. This typically includes setting up two processes: an ETL pipeline , which moves data, and a data storage (typically, a datawarehouse ), where it’s kept.
As the use of ChatGPT becomes more prevalent, I frequently encounter customers and data users citing ChatGPT’s responses in their discussions. I love the enthusiasm surrounding ChatGPT and the eagerness to learn about modern dataarchitectures such as data lakehouses, data meshes, and data fabrics.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both data lakes and datawarehouses and this post will explain this all. What is a data lakehouse? Datawarehouse vs data lake vs data lakehouse: What’s the difference.
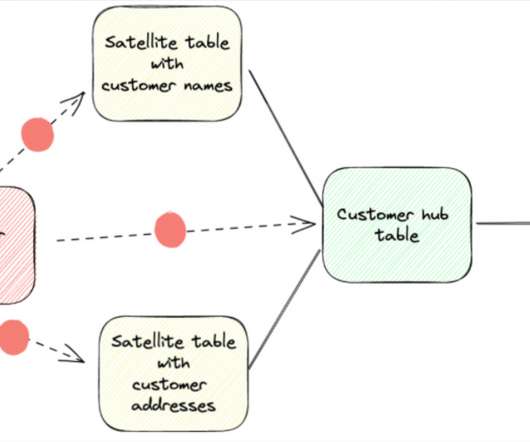
Over the past several years, datawarehouses have evolved dramatically, but that doesn’t mean the fundamentals underpinning sound dataarchitecture needs to be thrown out the window. What is a Data Vault model? Pie Insurance , a leading small business insurtech, leverages a data vault 2.0
Two different data modeling approaches—dimensional data modeling and Data Vault—each have their own pros and cons. Modernizing a datawarehouse with Snowflake Data Cloud is a smart investment that can provide significant benefits to businesses of all sizes, today more than ever as data models become ever more complex.
Although the program is technically in its seventh year, as the first joint awards program, this year’s Data Impact Awards will span even more use cases, covering even more advances in IoT, datawarehouse, machine learning, and more. DATA SECURITY AND GOVERNANCE.
is whether to choose a datawarehouse or lake to power storage and compute for their analytics. While datawarehouses provide structure that makes it easy for data teams to efficiently operationalize data (i.e., Data discovery tools and platforms can help. Image courtesy of Adrian on Unsplash.
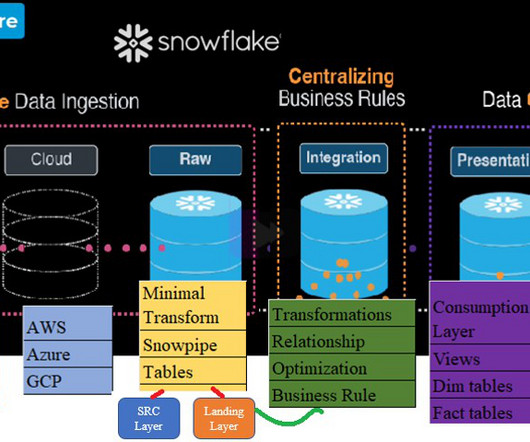
Read Time: 5 Minute, 16 Second As we know Snowflake has introduced latest badge “Data Cloud Deployment Framework” which helps to understand knowledge in designing, deploying, and managing the Snowflake landscape. Leverage the MERGE command to get the latest data in the Business layer.
Instead of relying on traditional hierarchical structures and predefined schemas, as in the case of datawarehouses, a data lake utilizes a flat architecture. This structure is made efficient by data engineering practices that include object storage. Datawarehouse vs. data lake in a nutshell.
This capability is useful for businesses, as it provides a clear and comprehensive view of their data’s history and transformations. Data lineage tools are not a new concept. In this article: Why Are Data Lineage Tools Important? It provides context for data, making it easier to understand and manage.
In the dynamic world of data, many professionals are still fixated on traditional patterns of data warehousing and ETL, even while their organizations are migrating to the cloud and adopting cloud-native data services. Modern platforms like Redshift , Snowflake , and BigQuery have elevated the datawarehouse model.
As the demand for big data grows, an increasing number of businesses are turning to cloud datawarehouses. The cloud is the only platform to handle today's colossal data volumes because of its flexibility and scalability. Launched in 2014, Snowflake is one of the most popular cloud data solutions on the market.
Big Data Processing In order to extract value or insights out of big data, one must first process it using big data processing software or frameworks, such as Hadoop. Big Query Google’s cloud datawarehouse. Data Catalog An organized inventory of data assets relying on metadata to help with data management.
It’s our goal at Monte Carlo to provide data observability and quality across the enterprise by monitoring every system vital in the delivery of data from source to consumption. We started with popular modern datawarehouses and quickly expanded our support as data lakes became data lakehouses.
We have discussed in the past this idea of the lakehouse , the aspirational target of many analytics platforms these days of combining the huge power and potential of data lakes with the rigour, reliability and concurrency of a datawarehouse. Essentially, we store data twice so that we can achieve the best of both worlds.
SiliconANGLE theCUBE: Analyst Predictions 2023 - The Future of Data Management By far one of the best analyses of trends in Data Management. 2023 predictions from the panel are; Unified metadata becomes kingmaker. RudderStack builds your CDP on top of your datawarehouse, giving you a more secure and cost-effective solution.
Enter: data provenance and data lineage. Data lineage is a visual tool that tracks the movement and transformations of data through various systems, processes, and applications. Data provenance is the record of metadata from data’s original sources, providing the historical context and authenticity of data.
Enter: data provenance and data lineage. Data lineage is a visual tool that tracks the movement and transformations of data through various systems, processes, and applications. Data provenance is the record of metadata from data’s original sources, providing the historical context and authenticity of data.
ELT is becoming the default choice for dataarchitectures and yet, many best practices focus primarily on “T”: the transformations. But the extract and load phase is where data quality is determined for transformation and beyond. Source system: Metadata about where the data was extracted from.
This process reduces noise in the data, which is crucial for the effectiveness of AI algorithms, especially in complex predictive models and deep learning applications. Such comprehensive metadata management is crucial in adhering to privacy and compliance standards, safeguarding AI operations against potential legal and ethical pitfalls.
Pro-tip: be sure to check out his talk from IMPACT: The Data Observability Summit. That gives a lot of credence to the idea you can look at Snowflake’s revenues as a proxy for what’s happening in the larger data ecosystem. billion in four years, which underscores the terrific demand there is for cloud datawarehouses.
This year data observability skyrocketed to the top of the Gartner’s Hype Cycles. According to Gartner, 50% of enterprise companies implementing distributed dataarchitectures will have adopted data observability tools by 2026 – up from just ~20% in 2024. Image courtesy of Gartner.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content