This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to dataarchitecture and structureddata management that really hit its stride in the early 1990s.
Data storage has been evolving, from databases to datawarehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structureddata and transactional workloads but struggled with performance at scale as data volumes grew.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. Each of these architectures has its own unique strengths and tradeoffs. The schema of semi-structureddata tends to evolve over time.
Summary Datawarehouses have gone through many transformations, from standard relational databases on powerful hardware, to column oriented storage engines, to the current generation of cloud-native analytical engines. If you are evaluating your options for building or migrating a data platform, then this is definitely worth a listen.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Data Storage Solutions As we all know, data can be stored in a variety of ways.
When I heard the words ‘decentralised dataarchitecture’, I was left utterly confused at first! In my then limited experience as a Data Engineer, I had only come across centralised dataarchitectures and they seemed to be working very well. Result: Datawarehouse was born. So what was missing?
It also came with other advantages such as independence of cloud infrastructure providers, data recovery features such as Time Travel , and zero copy cloning which made setting up several environments — such as dev, stage or production — way more efficient.
Data pipelines are the backbone of your business’s dataarchitecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. Understanding the essential components of data pipelines is crucial for designing efficient and effective dataarchitectures.
In this context, data management in an organization is a key point for the success of its projects involving data. One of the main aspects of correct data management is the definition of a dataarchitecture. The Lakehouse architecture was one of them.
First, organizations have a tough time getting their arms around their data. More data is generated in ever wider varieties and in ever more locations. Organizations don’t know what they have anymore and so can’t fully capitalize on it — the majority of data generated goes unused in decision making. Unified data fabric.
Business Intelligence (BI) combines human knowledge, technologies like distributed computing, and Artificial Intelligence, and big data analytics to augment business decisions for driving enterprise’s success. The goal of BI is to create intelligence through Data. But there is also Data Quality. So what is BI?
is whether to choose a datawarehouse or lake to power storage and compute for their analytics. While datawarehouses provide structure that makes it easy for data teams to efficiently operationalize data (i.e., And it’s an increasingly relevant one for modern data teams.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both data lakes and datawarehouses and this post will explain this all. What is a data lakehouse? Datawarehouse vs data lake vs data lakehouse: What’s the difference.
The emergence of cloud datawarehouses, offering scalable and cost-effective data storage and processing capabilities, initiated a pivotal shift in data management methodologies. Extract The initial stage of the ELT process is the extraction of data from various source systems.
As the demand for big data grows, an increasing number of businesses are turning to cloud datawarehouses. The cloud is the only platform to handle today's colossal data volumes because of its flexibility and scalability. Launched in 2014, Snowflake is one of the most popular cloud data solutions on the market.
In the dynamic world of data, many professionals are still fixated on traditional patterns of data warehousing and ETL, even while their organizations are migrating to the cloud and adopting cloud-native data services. Modern platforms like Redshift , Snowflake , and BigQuery have elevated the datawarehouse model.
The term data lake itself is metaphorical, evoking an image of a large body of water fed by multiple streams, each bringing new data to be stored and analyzed. Instead of relying on traditional hierarchical structures and predefined schemas, as in the case of datawarehouses, a data lake utilizes a flat architecture.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a datawarehouse, a centralized repository for structureddata, and a data lake used to host large amounts of raw data.
What is unstructured data? Definition and examples Unstructured data , in its simplest form, refers to any data that does not have a pre-defined structure or organization. It can come in different forms, such as text documents, emails, images, videos, social media posts, sensor data, etc.
Big Data Processing In order to extract value or insights out of big data, one must first process it using big data processing software or frameworks, such as Hadoop. Big Query Google’s cloud datawarehouse. Data Catalog An organized inventory of data assets relying on metadata to help with data management.
As a result, most companies are transforming into data-driven organizations harnessing the power of big data. Here Data Science becomes relevant as it deals with converting unstructured and messy data into structureddata sets for actionable business insights.
Understanding the “rise of data downtime” With a greater focus on monetizing data coupled with the ever present desire to increase data accuracy, we need to better understand some of the factors that can lead to data downtime. We’ll take a closer look at variables that can impact your data next.
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
The modern data stack era , roughly 2017 to present data, saw the widespread adoption of cloud computing and modern data repositories that decoupled storage from compute such as datawarehouses, data lakes, and data lakehouses. They also recently acquired Apache Flink , another streaming solution.
Businesses will be better able to make smart decisions and achieve a competitive advantage if they can successfully integrate data from various sources using SQL. If your database is cloud-based, using SQL to clean data is far more effective than scripting languages. They must load the raw data into a datawarehouse for this analysis.
In broader terms, two types of data -- structured and unstructured data -- flow through a data pipeline. The structureddata comprises data that can be saved and retrieved in a fixed format, like email addresses, locations, or phone numbers. What is a Big Data Pipeline?
By letting you query data directly in the lake without the need for movement, Synapse cuts down the storage costs and eliminates data duplication. This capability fosters a more flexible dataarchitecture where data can be processed and analyzed in its raw form.
Microsoft Azure's Azure Synapse, formerly known as Azure SQL DataWarehouse, is a complete analytics offering. Designed to tackle the challenges of modern data management and analytics, Azure Synapse brings together the worlds of big data and data warehousing into a unified and seamlessly integrated platform.
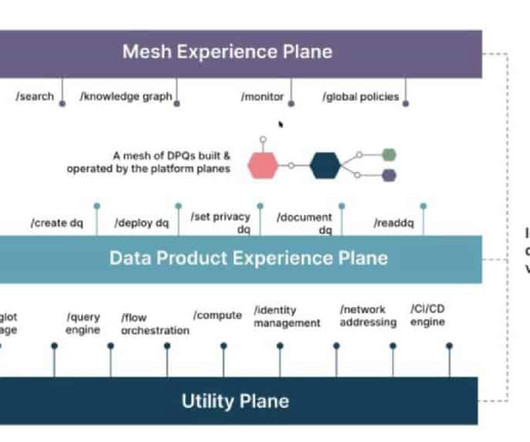
If you work with data, you’ll have come across the term data mesh by now. This decentralized but interconnected approach to structuringdata has become increasingly popular since the term was coined by Zhamak Dehghani 4 years ago. There’s no return to the old days of siloed datawarehouses.
Read More: AI Data Platform: Key Requirements for Fueling AI Initiatives How Data Engineering Enables AI Data engineering is the backbone of AI’s potential to transform industries , offering the essential infrastructure that powers AI algorithms.
Data Transformation and ETL: Handle more complex data transformation and ETL (Extract, Transform, Load) processes, including handling data from multiple sources and dealing with complex datastructures. Ensure compliance with data protection regulations. Define dataarchitecture standards and best practices.
In the last few decades, we’ve seen a lot of architectural approaches to building data pipelines , changing one another and promising better and easier ways of deriving insights from information. There have been relational databases, datawarehouses, data lakes, and even a combination of the latter two.
The vessel positions data which in nature is a time series geospatial data set, was stored in both PostgreSQL and Cassandra to be able to support different use cases. Furthermore, as Windward introduced new use cases they started to hit limitations with their data stack.
Big Data Engineer Salary by Skills The roles and responsibilities of a Big Data Engineer in an organization vary as per the business domain, type of the project, specific big data tools in use, IT infrastructure, technology stack, and a lot more. What does a big data engineer do?
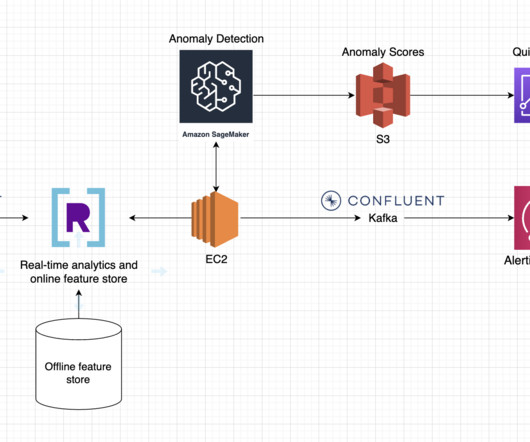
We’ve noticed many common patterns across streaming dataarchitectures and we’ll be sharing a blueprint for three of the most popular: anomaly detection, IoT, and recommendations. Offline feature store : Detecting anomalies requires historical data in order to have a baseline for comparisons. The database has two primary jobs.
Database-centric In bigger organizations, Data engineers mainly focus on data analytics since the data flow in such organizations is huge. Data engineers who focus on databases work with datawarehouses and develop different table schemas. Let us now understand the basic responsibilities of a Data engineer.
A Data Engineer is a professional who deals with data-related tasks such as creating, testing, and maintaining an organization's data infrastructure. Data engineers are professionals who play a consistent role in building datawarehouses to store data and data pipelines to feed data into those structures.
Data engineering is a new and ever-evolving field that can withstand the test of time and computing developments. Companies frequently hire certified Azure Data Engineers to convert unstructured data into useful, structureddata that data analysts and data scientists can use.
The data goes through various stages, such as cleansing, processing, warehousing, and some other processes, before the data scientists start analyzing the data they have garnered. The data analysis stage is important as the data scientists extract value and knowledge from the processed, structureddata.
Relational Database Management Systems (RDBMS) Non-relational Database Management Systems Relational Databases primarily work with structureddata using SQL (Structured Query Language). SQL works on data arranged in a predefined schema. Non-relational databases support dynamic schema for unstructured data.
This data can be analysed using big data analytics to maximise revenue and profits. We need to analyze this data and answer a few queries such as which movies were popular etc. To this group, we add a storage account and move the raw data. Then we create and run an Azure data factory (ADF) pipelines.
Data Variety Hadoop stores structured, semi-structured and unstructured data. RDBMS stores structureddata. Data storage Hadoop stores large data sets. RDBMS stores the average amount of data. Works with only structureddata. Hardware Hadoop uses commodity hardware.
For the same cost, organizations can now store 50 times as much data as in a Hadoop data lake than in a datawarehouse. Data lake is gaining momentum across various organizations and everyone wants to know how to implement a data lake and why.
Data Description: You will use the Covid-19 dataset(COVID-19 Cases.csv) from data.world , for this project, which contains a few of the following attributes: people_positive_cases_count county_name case_type data_source Language Used: Python 3.7 Access Solution to DataWarehouse Design for an E-com Site 4.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content