This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts.
Imagine having a framework capable of handling large amounts of data with reliability, scalability, and cost-effectiveness. That's where Hadoop comes into the picture. Hadoop is a popular open-source framework that stores and processes large datasets in a distributed manner. Why Are Hadoop Projects So Important?
Big data has taken over many aspects of our lives and as it continues to grow and expand, big data is creating the need for better and faster data storage and analysis. These Apache Hadoop projects are mostly into migration, integration, scalability, data analytics, and streaming analysis. Data Migration 2.
This specialist works closely with people on both business and IT sides of a company to understand the current needs of the stakeholders and help them unlock the full potential of data. To get a better understanding of a data architect’s role, let’s clear up what dataarchitecture is.
Data Engineers are engineers responsible for uncovering trends in data sets and building algorithms and data pipelines to make raw data beneficial for the organization. This job requires a handful of skills, starting from a strong foundation of SQL and programming languages like Python , Java , etc.
There is a huge range of online courses available, covering everything from cooking and gardening to languages and computer programming. Harvard University- CS50's Introduction to Computer Science Overview: This course introduces computer science's intellectual activities and the art of programming.
The Kafka Summit Program Committee recently published the schedule for the San Francisco event, and there’s quite a bit to look forward to. She has 15 years of experience working with code and customers to build scalable dataarchitectures, integrating relational and big data technologies.
Understanding the Hadooparchitecture now gets easier! This blog will give you an indepth insight into the architecture of hadoop and its major components- HDFS, YARN, and MapReduce. We will also look at how each component in the Hadoop ecosystem plays a significant role in making Hadoop efficient for big data processing.
This is not a prerequisite for entering the job, but with a growing number of data science education programs, many active data scientists studied…data science. Linear regression, classification, and ranking are also machine learning tasks and are common in operating real-world data. Programming.
Raghu Murthy, founder and CEO of Datacoral built data infrastructures at Yahoo! and Facebook, scaling from terabytes to petabytes of analytic data. He started Datacoral with the goal to make SQL the universal dataprogramming language. Raghu Murthy, founder and CEO of Datacoral built data infrastructures at Yahoo!
Raghu Murthy, founder and CEO of Datacoral built data infrastructures at Yahoo! and Facebook, scaling from terabytes to petabytes of analytic data. He started Datacoral with the goal to make SQL the universal dataprogramming language. Raghu Murthy, founder and CEO of Datacoral built data infrastructures at Yahoo!
To use a hyped example, models like ChatGPT could only be built on a huge mountain of data, produced and collected over years. I would like to emphasize the word “can” because there is a phrase in the world of programming that still holds, and probably ever will: garbage in, garbage out. Governance is needed.
Determining an architecture and a scalable data model to integrate more source systems in the future. The benefits of migrating to Snowflake start with its multi-cluster shared dataarchitecture, which enables scalability and high performance. Features such as auto-suspend and a pay-as-you-go model help you save costs.
The customer team included several Hadoop administrators, a program manager, a database administrator and an enterprise architect. This allowed them to enable a modern dataarchitecture, enhance their streaming capabilities and prepare for the next phase of the CDP Journey.
Through this, the company has gained visibility into fraudulent debit card activity and has executed a prevention program. With the right technology now in place, ATB Financial is landing and curating more data than ever to bring data-driven insights to the business and its customers. Implementing a Modern DataArchitecture.
Big Data Engineer performs a multi-faceted role in an organization by identifying, extracting, and delivering the data sets in useful formats. A Big Data Engineer also constructs, tests, and maintains the Big Dataarchitecture. As a Data Engineer, you will extensively use ETL in maintaining the data pipelines.
Data engineering involves a lot of technical skills like Python, Java, and SQL (Structured Query Language). For a data engineer career, you must have knowledge of data storage and processing technologies like Hadoop, Spark, and NoSQL databases. Understanding of Big Data technologies such as Hadoop, Spark, and Kafka.
Let us understand here the complete big data engineer roadmap to lead a successful Data Engineering Learning Path. Career Learning Path for Data Engineer You must have the right problem-solving and programmingdata engineer skills to establish a successful and rewarding Big Data Engineer learning path.
Datasets: RDDs can contain any type of data and can be created from data stored in local filesystems, HDFS (Hadoop Distributed File System), databases, or data generated through transformations on existing RDDs. Apache Spark architecture in a nutshell.
Typically, data processing is done using frameworks such as Hadoop, Spark, MapReduce, Flink, and Pig, to mention a few. How is Hadoop related to Big Data? Explain the difference between Hadoop and RDBMS. Data Variety Hadoop stores structured, semi-structured and unstructured data.
They’ll come up during your quest for a Data Engineer job, so using them effectively will be quite helpful. Python – The most popular programming language nowadays is Python, which is ranked third among programmers’ favorites. Data Engineers must be proficient in Python to create complicated, scalable algorithms.
4 Purpose Utilize the derived findings and insights to make informed decisions The purpose of AI is to provide software capable enough to reason on the input provided and explain the output 5 Types of Data Different types of data can be used as input for the Data Science lifecycle.
Part of the Data Engineer’s role is to figure out how to best present huge amounts of different data sets in a way that an analyst, scientist, or product manager can analyze. What does a data engineer do? A data engineer is an engineer who creates solutions from raw data.
While working as a big data engineer, there are some roles and responsibilities one has to do: Designing large data systems starts with designing a capable system that can handle large workloads. Develop the algorithms: Once the database is ready, the next thing is to analyze the data to obtain valuable insights.
While working as a big data engineer, there are some roles and responsibilities one has to do: Designing large data systems starts with designing a capable system that can handle large workloads. Develop the algorithms: Once the database is ready, the next thing is to analyze the data to obtain valuable insights.
Data Ingestion and Transformation: Candidates should have experience with data ingestion techniques, such as bulk and incremental loading, as well as experience with data transformation using Azure Data Factory. The MapReduce programming model served as the foundation for its creation by the Apache Software Foundation.
Without a fixed schema, the data can vary in structure and organization. File systems, data lakes, and Big Data processing frameworks like Hadoop and Spark are often utilized for managing and analyzing unstructured data. The process requires extracting data from diverse sources, typically via APIs.
Big Data Processing In order to extract value or insights out of big data, one must first process it using big data processing software or frameworks, such as Hadoop. Big Query Google’s cloud data warehouse. Data Catalog An organized inventory of data assets relying on metadata to help with data management.
The data engineers are responsible for creating conversational chatbots with the Azure Bot Service and automating metric calculations using the Azure Metrics Advisor. Data engineers must know data management fundamentals, programming languages like Python and Java, cloud computing and have practical knowledge on data technology.
Who are Data Engineers? Data Engineers are professionals who bridge the gap between the working capacity of software engineering and programming. They are people equipped with advanced analytical skills, robust programming skills, statistical knowledge, and a clear understanding of big data technologies.
Big Data Engineer Salary by Experience (Entry-Level, Mid-Level, and Senior) Entry-Level Big Data Engineer Salary An entry-level position does not demand years of experience in Big Data technology. However, one should have an educational background and theoretical knowledge in data management. can help better negotiations.
Even Fortune 500 businesses (Facebook, Google, and Amazon) that have created their own high-performance database systems also typically use SQL to query data and conduct analytics. You will discover that more employers seek SQL than any machine learning skills, such as R or Python programming skills, on job portals like LinkedIn.
Business Intelligence (BI) combines human knowledge, technologies like distributed computing, and Artificial Intelligence, and big data analytics to augment business decisions for driving enterprise’s success. It replaced its traditional BI structure by integrating big data and Hadoop."-April So what is BI? So what is BI?
Source: Databricks Delta Lake is an open-source, file-based storage layer that adds reliability and functionality to existing data lakes built on Amazon S3, Google Cloud Storage, Azure Data Lake Storage, Alibaba Cloud, HDFS ( Hadoop distributed file system), and others. Databricks focuses on data engineering and data science.
In the age of big data processing, how to store these terabytes of data surfed over the internet was the key concern of companies until 2010. Now that the issue of storage of big data has been solved successfully by Hadoop and various other frameworks, the concern has shifted to processing these data.
This increased the data generation and the need for proper data storage requirements. A data architect is concerned with designing, creating, deploying, and managing a business entity's dataarchitecture. You must possess top in-demand data science skills that always keep you job-ready.
Implemented and managed data storage solutions using Azure services like Azure SQL Database , Azure Data Lake Storage, and Azure Cosmos DB. Education & Skills Required Proficiency in SQL, Python, or other programming languages. Develop data models, data governance policies, and data integration strategies.
Projects: Engage in projects with a component that involves data collection, processing, and analysis. Learn Key Technologies Programming Languages: Language skills, either in Python, Java, or Scala. Data Warehousing: Experience in using tools like Amazon Redshift, Google BigQuery, or Snowflake. 90,000 – $130,000 per year.
is required to become a Data Science expert. It is not necessary to have expertise in programming. Expert-level knowledge of programming, Big Dataarchitecture, etc., is essential to becoming a Data Engineering professional. Data mining and data management skills are essential for a data engineer.nd
When you build microservices architectures, one of the concerns you need to address is that of communication between the microservices. At first, you may think to use REST APIs—most programming languages have frameworks that make it very easy to implement REST APIs, so this is a common first choice.
Let us look at some of the functions of Data Engineers: They formulate data flows and pipelines Data Engineers create structures and storage databases to store the accumulated data, which requires them to be adept at core technical skills, like design, scripting, automation, programming, big data tools , etc.
It refers to a series of operations to convert raw data into a format suitable for analysis, reporting, and machine learning which you can learn from data engineer books. You can pace your learning by joining data engineering courses such as the Bootcamp Data Engineer. Who are Data Engineers?
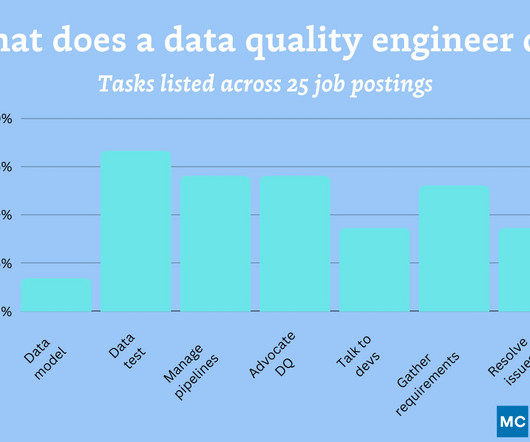
The most common use case data quality engineers support are: Analytical dashboards : Mentioned in 56% of job postings Machine learning or data science teams : Mentioned in 34% of postings Gen AI : Mentioned in one job posting (but really emphatically). About 61% request you also have a formal computer science degree.
Neelesh regularly shares his advice channels, including as a recent guest on Databand’s MAD Data Podcast , where he spoke about how engineering can deliver better value for data science. On LinkedIn, he posts frequently about data engineering, dataarchitecture, interview preparation, and career advice.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content