This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ELT is becoming the default choice for dataarchitectures and yet, many best practices focus primarily on “T”: the transformations. But the extract and load phase is where data quality is determined for transformation and beyond. “Rawdata” sounds clear.
Metadata and evolution support : We’ve added structured-type schema evolution for flexibility as source systems or business reporting needs change. Get better Iceberg ecosystem interoperability with Primary Key information added to Iceberg table metadata.
The fact tables then feed downstream intraday pipelines that process the data hourly. Rawdata for hours 3 and 6 arrive. Hour 6 data flows through the various workflows, while hour 3 triggers a late data audit alert. It leverages Iceberg metadata to facilitate processing incremental and batch-based data pipelines.
Over the past several years, data warehouses have evolved dramatically, but that doesn’t mean the fundamentals underpinning sound dataarchitecture needs to be thrown out the window. Data vault collects and organizes rawdata as underlying structure to act as the source to feed Kimball or Inmon dimensional models.
The data products are packaged around the business needs and in support of the business use cases. This step requires curation, harmonization, and standardization from the rawdata into the products. Luke: Let’s talk about some of the fundamentals of modern dataarchitecture. What is a data fabric?
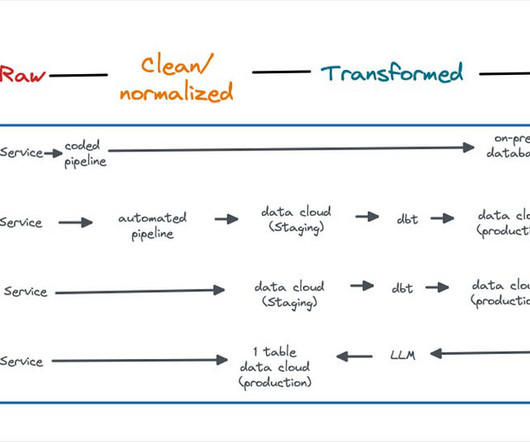
Zero-ETL What it is : A misnomer for one thing; the data pipeline still exists. Today, data is often generated by a service and written into a transactional database. An automatic pipeline is deployed which not only moves the rawdata to the analytical data warehouse, but modifies it slightly along the way.
Read Time: 5 Minute, 16 Second As we know Snowflake has introduced latest badge “Data Cloud Deployment Framework” which helps to understand knowledge in designing, deploying, and managing the Snowflake landscape. Secondly, Define Business Rules : Develop the transformation on RAWdata and include the Business logic.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both data lakes and data warehouses and this post will explain this all. What is a data lakehouse? Another type of data storage — a data lake — tried to address these and other issues. Data lake.
A DataOps architecture is the structural foundation that supports the implementation of DataOps principles within an organization. It encompasses the systems, tools, and processes that enable businesses to manage their data more efficiently and effectively. As a result, they can be slow, inefficient, and prone to errors.
The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. This article explains what a data lake is, its architecture, and diverse use cases. Watch our video explaining how data engineering works.
SiliconANGLE theCUBE: Analyst Predictions 2023 - The Future of Data Management By far one of the best analyses of trends in Data Management. 2023 predictions from the panel are; Unified metadata becomes kingmaker. The author writes a few best practices for managing medallion-style architecture.
Data Catalogs Can Drown in a Data Lake Although exceptionally flexible and scalable, data lakes lack the organization necessary to facilitate proper metadata management and data governance. Data discovery tools and platforms can help. Interested in learning how to scale data discovery across your data lake?
In the dynamic world of data, many professionals are still fixated on traditional patterns of data warehousing and ETL, even while their organizations are migrating to the cloud and adopting cloud-native data services. Their task is straightforward: take the rawdata and transform it into a structured, coherent format.
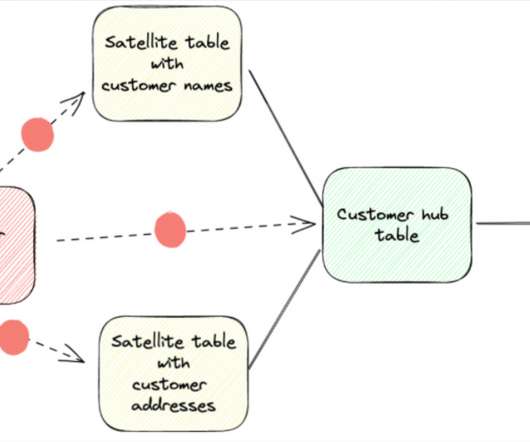
You can see how Data Vault overcomes some limitations of the dimensional model below: Why Data Vault can be a better choice for CQR and management data warehousing In the CQR, data quality and accuracy are critical. Metadata in the Data Vault approach helps to track the origin and processing of data.
Becoming a Big Data Engineer - The Next Steps Big Data Engineer - The Market Demand An organization’s data science capabilities require data warehousing and mining, modeling, data infrastructure, and metadata management. Most of these are performed by Data Engineers.
Data lakes offer a flexible and cost-effective approach for managing and storing unstructured data, ensuring high durability and availability. Last but not least, you may need to leverage data labeling if you train models for custom tasks. Build dataarchitecture. Invest in data governance.
For today’s Chief Data Officers (CDOs) and data teams, the struggle is real. We’re drowning in data yet thirsting for actionable insights. We need a new approach, a paradigm shift that delivers data with the agility and efficiency of a speedboat – enter Data Products.
All of these assessments go back to the AI insights initiative that led Windward to re-examine its data stack. The steps Windward takes to create proprietary data and AI insights As Windward operated in a batch-based data stack, they stored rawdata in S3.
Aside from video data from each camera-equipped store, Standard deals with other data sets such as transactional data, store inventory data that arrive in different formats from different retailers, and metadata derived from the extensive video captured by their cameras.
In the age of self-service business intelligence , nearly every company considers themselves a data-first company, but not every company is treating their dataarchitecture with the level of democratization and scalability it deserves. Your company, for one, views data as a driver of innovation.
It enables advanced analytics, makes debugging your marketing automations easier, provides natural audit trails for compliance, and allows for flexible, evolving customer data models. So next time you’re designing your customer dataarchitecture in your CDP, don’t just think about the current state of your customers.
Big data operations require specialized tools and techniques since a relational database cannot manage such a large amount of data. Big data enables businesses to gain a deeper understanding of their industry and helps them extract valuable information from the unstructured and rawdata that is regularly collected.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of rawdata.
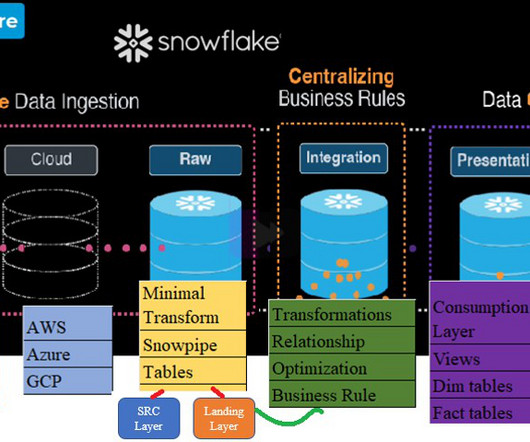
Provides Powerful Computing Resources for Data Processing Before inputting data into advanced machine learning models and deep learning tools, data scientists require sufficient computing resources to analyze and prepare it. The query processing layer is separated from the disk storage layer in the Snowflake dataarchitecture.
Data transformation dbt – Short for data build tool, is the open source leader for transforming data once it’s loaded into your warehouse. Dataform – Now part of the Google Cloud , Dataform allows you to transform rawdata from your warehouse into something usable by BI and analytics tools.
Technical Data Engineer Skills 1.Python Python Python is one of the most looked upon and popular programming languages, using which data engineers can create integrations, data pipelines, integrations, automation, and data cleansing and analysis.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content