This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data storage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structureddata and transactional workloads but struggled with performance at scale as data volumes grew.
We live in a hybrid data world. In the past decade, the amount of structureddata created, captured, copied, and consumed globally has grown from less than 1 ZB in 2011 to nearly 14 ZB in 2020. Impressive, but dwarfed by the amount of unstructured data, cloud data, and machine data – another 50 ZB.
And, since historically tools and commercial platforms were often designed to align with one specific architecture pattern, organizations struggled to adapt to changing business needs – which of course has implications on dataarchitecture. The schema of semi-structureddata tends to evolve over time.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structureddata) then enterprise-wide data lakes versus smaller, typically BU-Specific, “data ponds”.
In this context, data management in an organization is a key point for the success of its projects involving data. One of the main aspects of correct data management is the definition of a dataarchitecture. show() The history object is a Spark Data Frame. delta_table.history().select("version",
Read More: AI Data Platform: Key Requirements for Fueling AI Initiatives How Data Engineering Enables AI Data engineering is the backbone of AI’s potential to transform industries , offering the essential infrastructure that powers AI algorithms.
Data Catalogs Can Drown in a Data Lake Although exceptionally flexible and scalable, data lakes lack the organization necessary to facilitate proper metadata management and data governance. Data discovery tools and platforms can help. Interested in learning how to scale data discovery across your data lake?
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both data lakes and data warehouses and this post will explain this all. What is a data lakehouse? Traditional data warehouse platform architecture. Unstructured and streaming data support.
What is unstructured data? Definition and examples Unstructured data , in its simplest form, refers to any data that does not have a pre-defined structure or organization. It can come in different forms, such as text documents, emails, images, videos, social media posts, sensor data, etc.
Instead of relying on traditional hierarchical structures and predefined schemas, as in the case of data warehouses, a data lake utilizes a flat architecture. This structure is made efficient by data engineering practices that include object storage. Watch our video explaining how data engineering works.
Big Query Google’s cloud data warehouse. DataArchitectureDataarchitecture is a composition of models, rules, and standards for all data systems and interactions between them. Data Catalog An organized inventory of data assets relying on metadata to help with data management.
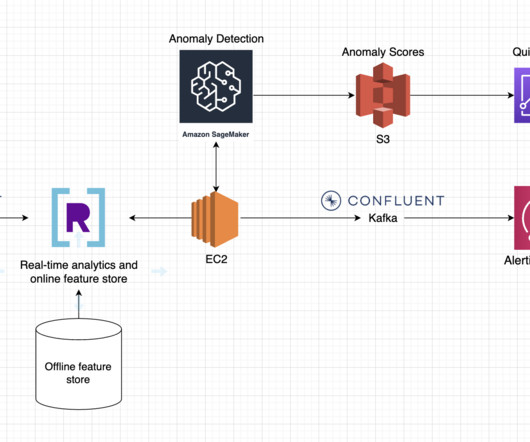
We’ve noticed many common patterns across streaming dataarchitectures and we’ll be sharing a blueprint for three of the most popular: anomaly detection, IoT, and recommendations. This will simplify your architecture considerably, deliver low-latency recommendation results, and enable metadata filtering.
The steps Windward takes to create proprietary data and AI insights As Windward operated in a batch-based data stack, they stored raw data in S3. They used MongoDB as their metadata store to capture vessel and company data.
Snowflake in Action at Western Union Snowflake's multi-cluster shared dataarchitecture expanded instantaneously to serve Western Union's data, users, and workloads without causing resource conflict. Snowflake saves and manages data on the cloud using a shared-disk approach, making data management simple.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structureddata, and a data lake used to host large amounts of raw data.
Aside from video data from each camera-equipped store, Standard deals with other data sets such as transactional data, store inventory data that arrive in different formats from different retailers, and metadata derived from the extensive video captured by their cameras.
Data modeling involves creating a conceptual representation of data objects and their relationships to each other, as well as the rules governing those relationships. To design an effective data governance program, it’s crucial to choose an operational model that fits your business size and structure.
Data Variety Hadoop stores structured, semi-structured and unstructured data. RDBMS stores structureddata. Data storage Hadoop stores large data sets. RDBMS stores the average amount of data. Works with only structureddata. Hardware Hadoop uses commodity hardware.
In the dynamic world of data, many professionals are still fixated on traditional patterns of data warehousing and ETL, even while their organizations are migrating to the cloud and adopting cloud-native data services. Central to this transformation are two shifts.
Spark SQL brings native support for SQL to Spark and streamlines the process of querying semistructured and structureddata. When transformations are applied to RDDs, Spark records the metadata to build up a DAG, which reflects the sequence of computations performed during the execution of the Spark job.
What data mesh is and is not. What data mesh IS. Data mesh is a set of principles for designing a modern distributed dataarchitecture that focuses on business domains, not the technology used, and treats data as a product. For example, your organization has an HR platform that produces employee data.
Data observability platforms reduce your data downtime up to 80% and make your data engineers 30% more time efficient by replacing static, cumbersome data testing with machine learning models that can help detect, resolve, and prevent data issues. Let the data drive the data pipeline architecture.
Demands on the cloud data warehouse are also evolving to require it to become more of an all-in-one platform for an organization’s analytics needs. Enter Snowflake The Snowflake Data Cloud is one of the most popular and powerful CDW providers.
Data Integration at Scale Most dataarchitectures rely on a single source of truth. Having multiple data integration routes helps optimize the operational as well as analytical use of data. A feature store is a modern, elegant solution to leverage data prep work from previous runs or other teams as well.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content