This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
At BUILD 2024, we announced several enhancements and innovations designed to help you build and manage your dataarchitecture on your terms. Support for auto-refresh and Iceberg metadata generation is coming soon to Delta Lake Direct. Here’s a closer look.
First, we create an Iceberg table in Snowflake and then insert some data. Then, we add another column called HASHKEY , add more data, and locate the S3 file containing metadata for the iceberg table. In the screenshot below, we can see that the metadata file for the Iceberg table retains the snapshot history.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
In the past decade, the amount of structured data created, captured, copied, and consumed globally has grown from less than 1 ZB in 2011 to nearly 14 ZB in 2020. Impressive, but dwarfed by the amount of unstructureddata, cloud data, and machine data – another 50 ZB.
Strong data governance also lays the foundation for better model performance, cost efficiency, and improved data quality, which directly contributes to regulatory compliance and more secure AI systems. The technology for metadata management, data quality management, etc., No problem! is fairly advanced.
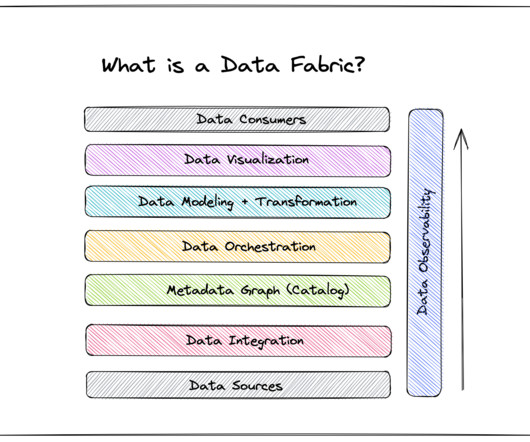
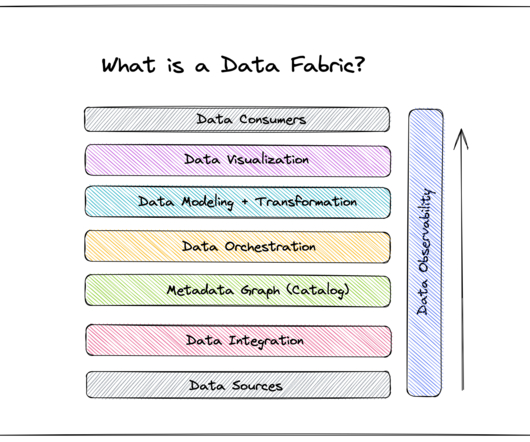
Today, as data sources become increasingly varied, data management becomes more complex, and agility and scalability become essential traits for data leaders, data fabric is quickly becoming the future of dataarchitecture. If data fabric is the future, how can you get your organization up-to-speed?
Today, as data sources become increasingly varied, data management becomes more complex, and agility and scalability become essential traits for data leaders, data fabric is quickly becoming the future of dataarchitecture. If data fabric is the future, how can you get your organization up-to-speed?
And, since historically tools and commercial platforms were often designed to align with one specific architecture pattern, organizations struggled to adapt to changing business needs – which of course has implications on dataarchitecture.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide data lakes versus smaller, typically BU-Specific, “data ponds”.
Grab’s Metasense , Uber’s DataK9 , and Meta’s classification systems use AI to automatically categorize vast data sets, reducing manual efforts and improving accuracy. Beyond classification, organizations now use AI for automated metadata generation and data lineage tracking, creating more intelligent data infrastructures.
This specialist works closely with people on both business and IT sides of a company to understand the current needs of the stakeholders and help them unlock the full potential of data. To get a better understanding of a data architect’s role, let’s clear up what dataarchitecture is.
While Cloudera CDH was already a success story at HBL, in 2022, HBL identified the need to move its customer data centre environment from Cloudera’s CDH to Cloudera Data Platform (CDP) Private Cloud to accommodate growing volumes of data. Smooth, hassle-free deployment in just six weeks.
As the use of ChatGPT becomes more prevalent, I frequently encounter customers and data users citing ChatGPT’s responses in their discussions. I love the enthusiasm surrounding ChatGPT and the eagerness to learn about modern dataarchitectures such as data lakehouses, data meshes, and data fabrics.
Mark: While most discussions of modern data platforms focus on comparing the key components, it is important to understand how they all fit together. The high-level architecture shown below forms the backdrop for the exploration. Luke: Let’s talk about some of the fundamentals of modern dataarchitecture.
As organizations seek greater value from their data, dataarchitectures are evolving to meet the demand — and table formats are no exception. But while the modern data stack , and how it’s structured, may be evolving, the need for reliable data is not — and that also has some real implications for your data platform.
This capability is useful for businesses, as it provides a clear and comprehensive view of their data’s history and transformations. Data lineage tools are not a new concept. In this article: Why Are Data Lineage Tools Important? It provides context for data, making it easier to understand and manage.
Data Catalogs Can Drown in a Data Lake Although exceptionally flexible and scalable, data lakes lack the organization necessary to facilitate proper metadata management and data governance. Data discovery tools and platforms can help. Interested in learning how to scale data discovery across your data lake?
Big Data Large volumes of structured or unstructureddata. Big Data Processing In order to extract value or insights out of big data, one must first process it using big data processing software or frameworks, such as Hadoop. Big Query Google’s cloud data warehouse.
requires multiple categories of data, from time series and transactional data to structured and unstructureddata. initiatives, such as improving efficiency and reducing downtime by including broader data sets (both internal and external), offers businesses even greater value and precision in the results.
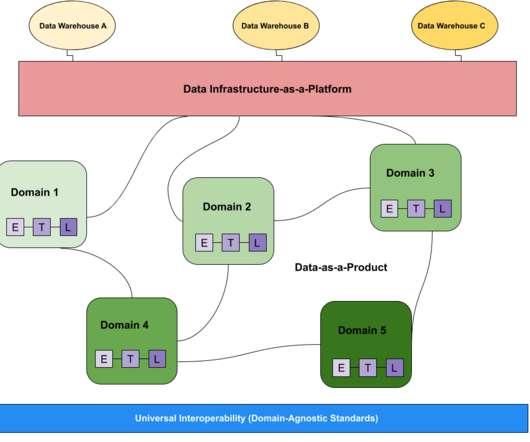
But while most every company would consider themselves a “data-first” organization, not every dataarchitecture is treated to the same level of democratization and scalability. In this post we’ll look at the dizzyingly buzzy data mesh and how it stacks up to the more traditional aggregated architectural approach of a data lake.
With Snowflake’s support for multiple data models such as dimensional data modeling and Data Vault, as well as support for a variety of data types including semi-structured and unstructureddata, organizations can accommodate a variety of sources to support their different business use cases.
Instead of relying on traditional hierarchical structures and predefined schemas, as in the case of data warehouses, a data lake utilizes a flat architecture. This structure is made efficient by data engineering practices that include object storage. Watch our video explaining how data engineering works.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both data lakes and data warehouses and this post will explain this all. What is a data lakehouse? Traditional data warehouse platform architecture. Metadata layer. Metadata layer.
Becoming a Big Data Engineer - The Next Steps Big Data Engineer - The Market Demand An organization’s data science capabilities require data warehousing and mining, modeling, data infrastructure, and metadata management. Most of these are performed by Data Engineers.
The Azure Data Engineer Certification test evaluates one's capacity for organizing and putting into practice data processing, security, and storage, as well as their capacity for keeping track of and maximizing data processing and storage. They control and safeguard the flow of organized and unstructureddata from many sources.
Amazon S3 – An object storage service for structured and unstructureddata, S3 gives you the compute resources to build a data lake from scratch. Data catalog Some organizations choose to implement data catalog solutions for data governance and compliance use cases. Now Go Build Some Data Pipelines!
Big data enables businesses to get valuable insights into their products or services. Almost every company employs data models and big data technologies to improve its techniques and marketing campaigns. Most leading companies use big data analytical tools to enhance business decisions and increase revenues.
With a plethora of new technology tools on the market, data engineers should update their skill set with continuous learning and data engineer certification programs. What do Data Engineers Do? Technical Data Engineer Skills 1.Python Knowing how to work with key-value pairs and object formats is still necessary.
In the dynamic world of data, many professionals are still fixated on traditional patterns of data warehousing and ETL, even while their organizations are migrating to the cloud and adopting cloud-native data services. Central to this transformation are two shifts.
This way, Delta Lake brings warehouse features to cloud object storage — an architecture for handling large amounts of unstructureddata in the cloud. Besides that, it’s fully compatible with various data ingestion and ETL tools. Databricks focuses on data engineering and data science.
Data Integration at Scale Most dataarchitectures rely on a single source of truth. Having multiple data integration routes helps optimize the operational as well as analytical use of data. A feature store is a modern, elegant solution to leverage data prep work from previous runs or other teams as well.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content