This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
The thought of learning Scala fills many with fear, its very name often causes feelings of terror. The truth is Scala can be used for many things; from a simple web application to complex ML (Machine Learning). The name Scala stands for “scalable language.” So what companies are actually using Scala?
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts.
The data mesh design pattern breaks giant, monolithic enterprise dataarchitectures into subsystems or domains, each managed by a dedicated team. Skill-based roles cannot rapidly respond to customer requests – Imagine a project where different parts are written in Java, Scala, and Python. Introduction to Data Mesh.
To expand the capabilities of the Snowflake engine beyond SQL-based workloads, Snowflake launched Snowpark , which added support for Python, Java and Scala inside virtual warehouse compute.
This specialist works closely with people on both business and IT sides of a company to understand the current needs of the stakeholders and help them unlock the full potential of data. To get a better understanding of a data architect’s role, let’s clear up what dataarchitecture is.
We have partnered with organizations such as O’Reilly Media, Dataversity, and the Open Data Science Conference. Coming up this fall is the combined events of Graphorum and the DataArchitecture Summit. We have partnered with organizations such as O’Reilly Media, Dataversity, and the Open Data Science Conference.
We have partnered with organizations such as O’Reilly Media, Dataversity, Corinium Global Intelligence, Alluxio, and Data Council. Upcoming events include the combined events of the DataArchitecture Summit and Graphorum, the Data Orchestration Summit, and Data Council in NYC.
A new breed of ‘Fast Data’ architectures has evolved to be stream-oriented, where data is processed as it arrives, providing businesses with a competitive advantage. Dean Wampler (Renowned author of many big data technology-related books) Dean Wampler makes an important point in one of his webinars.
And, since historically tools and commercial platforms were often designed to align with one specific architecture pattern, organizations struggled to adapt to changing business needs – which of course has implications on dataarchitecture.
Authorized users can share notebooks, libraries, queries, ML experiments, data visualizations , and other objects across the organization in a secure manner, enhancing collaboration. Moreover, the platform supports four languages — SQL, R, Python , and Scala — and allows you to switch between them and use them all in the same script.
To ensure that we continue to meet these expectations, it was apparent that we needed to make sizable investments in our data. These investments centered around addressing areas related to ownership, dataarchitecture, and governance. Testing Another area we needed to improve was our data pipeline testing.
You ought to be able to create a data model that is performance- and scalability-optimized. Programming and Scripting Skills Building data processing pipelines requires knowledge of and experience with coding in programming languages like Python, Scala, or Java.
Depending on the project, data engineers can have a wider or narrow set of responsibilities, so their skillset may vary as well. An overview of data engineer skills. Data engineers are well-versed in Java, Scala, and C++, since these languages are often used in dataarchitecture frameworks such as Hadoop, Apache Spark, and Kafka.
To run a diverse set of workloads with minimal operational burden, Snowflake built an intelligent engine that plans and optimizes the execution of concurrent workloads using a multi-clustered, shared dataarchitecture. It also features logically integrated but physically separated storage and compute.
Python is ubiquitous, which you can use in the backends, streamline data processing, learn how to build effective dataarchitectures, and maintain large data systems. Kafka Kafka is one of the most desired open-source messaging and streaming systems that allows you to publish, distribute, and consume data streams.
It has in-memory computing capabilities to deliver speed, a generalized execution model to support various applications, and Java, Scala, Python, and R APIs. Despite these nuances, Spark’s high-speed processing capabilities make it an attractive choice for big data processing tasks.
Projects: Engage in projects with a component that involves data collection, processing, and analysis. Learn Key Technologies Programming Languages: Language skills, either in Python, Java, or Scala. Data Warehousing: Experience in using tools like Amazon Redshift, Google BigQuery, or Snowflake.
Here are some role-specific skills you should consider to become an Azure data engineer- Most data storage and processing systems use programming languages. Data engineers must thoroughly understand programming languages such as Python, Java, or Scala. What is the most popular Azure Certification?
Language Compatibility: Databricks provides extensive language compatibility, catering to data professionals with diverse skill sets. Some of the prominent languages supported include: Scala: Ideal for developers who want to leverage the full power of Apache Spark.
Once running, all Hadoop jobs (Spark/Scala, PySpark, SparkSQL, MapReduce) read and write S3 data via the S3A implementation of the Hadoop filesystem API. Figure 3 illustrates the resulting overall FGAC Big Dataarchitecture. CVS formed the cornerstone of our approach to extending Monarch with FGAC capabilities.
Go for the best courses for Data Engineering and polish your big data engineer skills to take up the following responsibilities: You should have a systematic approach to creating and working on various dataarchitectures necessary for storing, processing, and analyzing large amounts of data.
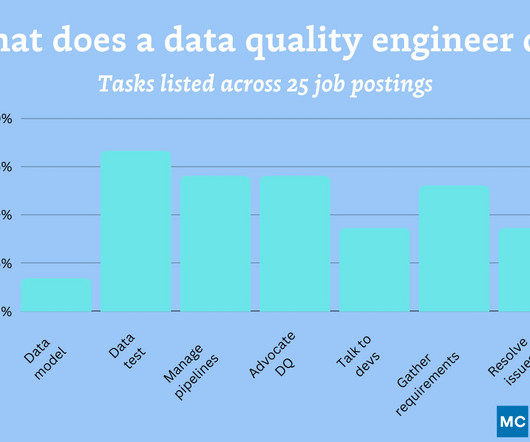
The most common use case data quality engineers support are: Analytical dashboards : Mentioned in 56% of job postings Machine learning or data science teams : Mentioned in 34% of postings Gen AI : Mentioned in one job posting (but really emphatically). About 61% request you also have a formal computer science degree.
Part of the Data Engineer’s role is to figure out how to best present huge amounts of different data sets in a way that an analyst, scientist, or product manager can analyze. What does a data engineer do? A data engineer is an engineer who creates solutions from raw data.
Snowpark under the hood Check out these great in-depth blogs and videos from the Snowpark Engineering team on how Snowpark was built, how it works, and how it makes it easy and secure to process Python/Java/Scala code in Snowflake.
The Base For Data Science Though data scientists come from different backgrounds, have different skills and work experience, most of them should either be strong in it or have a good grip on the four main areas: Business and Management Statistics and Probability. B.Tech(Computer Science) Or DataArchitecture.
Additionally, for a job in data engineering, candidates should have actual experience with distributed systems, data pipelines, and related database concepts.
This exam tests how well you can configure each component of a data processing pipeline and set it up. It necessitates that you possess in-depth understanding of parallel processing, dataarchitecture patterns, and data computation languages (ideally SQL, Python, or Scala).
The platform’s massive parallel processing (MPP) architecture empowers you with high-performance querying of even massive datasets. Polyglot Data Processing Synapse speaks your language! It supports multiple programming languages including T-SQL, Spark SQL, Python, and Scala.
Hadoop can store data and run applications on cost-effective hardware clusters. Its dataarchitecture is flexible, relevant, and schema-free. To learn more about this topic, explore our Big Data and Hadoop course. The dataarchitecture must guarantee data security and enforce access control measures.
By combining data from various structured and unstructured data systems into structures, Microsoft Azure Data Engineers will be able to create analytics solutions. Why Should You Get an Azure Data Engineer Certification?
Azure Data Engineer Associate DP-203 Certification Candidates for this exam must possess a thorough understanding of SQL, Python, and Scala, among other data processing languages. Must be familiar with dataarchitecture, data warehousing, parallel processing concepts, etc.
It plays a key role in streaming in the form of Spark Streaming libraries, interactive analytics in the form of SparkSQL and also provides libraries for machine learning that can be imported using Python or Scala. This data can be analysed using big data analytics to maximise revenue and profits.
Data engineers working on healthcare product development may build data systems to support AI-powered medical image analysis. On the other hand, a data engineer working in a hospital system might design a dataarchitecture that manages and integrates electronic medical records.
According to Salary Expert, the data engineer average salary for a beginner with 1-3 years of experience is approximately $76,537. To earn more, you must invest time in mastering tools such as SQL, Python, ETL procedures, and big dataarchitectures.
They should be familiar with major coding languages like R, Python, Scala, and Java and scientific computing tools like MATLAB. Once you are in the domain, there are many career scopes ahead, including data sciences, data analysis, dataarchitecture, reinforcement learning, deep learning, and a few other related streams.
Write UDFs in Scala and PySpark to meet specific business requirements. Develop JSON scripts for deploying pipelines in Azure Data Factory (ADF) that process data using SQL activities. It helps in the design of efficient, scalable and maintainable databases, data warehouses, and data marts.
A strong foundation of statistics is essential for them, and almost all data science tools are largely useful. They are experts in coding in programming languages like Python, Java, Scala, C++. They also require experience in Hadoop, Spark, Amazon Web services, etc.
Neelesh regularly shares his advice channels, including as a recent guest on Databand’s MAD Data Podcast , where he spoke about how engineering can deliver better value for data science. On LinkedIn, he posts frequently about data engineering, dataarchitecture, interview preparation, and career advice.
Spark Architecture has three major components: API, Data Storage, and Management Framework. Spark provides APIs for the programming languages Java, Scala, and Python. Data Storage: Spark stores data using the HDFS file system. Any Hadoop-compatible data source, such as HDFS, HBase, and Cassandra , etc.,
Snowflake in Action at Western Union Snowflake's multi-cluster shared dataarchitecture expanded instantaneously to serve Western Union's data, users, and workloads without causing resource conflict. The query processing layer is separated from the disk storage layer in the Snowflake dataarchitecture.
He currently runs a YouTube channel, E-Learning Bridge , focused on video tutorials for aspiring data professionals and regularly shares advice on data engineering, developer life, careers, motivations, and interviewing on LinkedIn.
How do you access Azure Data Lake Storage from a Notebook? Walmart Data Engineer Interview Questions Some of the Data Engineer interview questions asked in Walmart are 105. What is a case class in Scala? Elaborate on the Hive architecture. What are the various types of data models?
Given Spark’s origins in the big data community this makes sense. The established toolsets are geared towards Python and Scala developers, people who are very literate in distributed compute for solving complex data problems.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content