This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a data warehouse The data warehouse (DW) was an approach to dataarchitecture and structureddata management that really hit its stride in the early 1990s.
Summary The process of exposing your data through a SQL interface has many possible pathways, each with their own complications and tradeoffs. One of the recent options is Rockset, a serverless platform for fast SQL analytics on semi-structured and structureddata.
Data storage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structureddata and transactional workloads but struggled with performance at scale as data volumes grew.
The alternative, however, provides more multi-cloud flexibility and strong performance on structureddata. Its multi-cluster shared dataarchitecture is one of its primary features. Ideal for: Fabric makes the administration of data lakes much simpler; Snowflake provides flexible options for using external lakes.
Once the data is in the warehouse, we are leveraging Snowflake’s data warehousing features to handle it. Something that is especially handy is Snowflake’s support for semi-structureddata.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts.
When I heard the words ‘decentralised dataarchitecture’, I was left utterly confused at first! In my then limited experience as a Data Engineer, I had only come across centralised dataarchitectures and they seemed to be working very well. So what was missing?
To attain that level of data quality, a majority of business and IT leaders have opted to take a hybrid approach to data management, moving data between cloud, on-premises -or a combination of the two – to where they can best use it for analytics or feeding AI models. What do we mean by ‘true’ hybrid? Let’s dive deeper.
We live in a hybrid data world. In the past decade, the amount of structureddata created, captured, copied, and consumed globally has grown from less than 1 ZB in 2011 to nearly 14 ZB in 2020. Impressive, but dwarfed by the amount of unstructured data, cloud data, and machine data – another 50 ZB.
And, since historically tools and commercial platforms were often designed to align with one specific architecture pattern, organizations struggled to adapt to changing business needs – which of course has implications on dataarchitecture. The schema of semi-structureddata tends to evolve over time.
Data pipelines are the backbone of your business’s dataarchitecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. Understanding the essential components of data pipelines is crucial for designing efficient and effective dataarchitectures.
First, organizations have a tough time getting their arms around their data. More data is generated in ever wider varieties and in ever more locations. Organizations don’t know what they have anymore and so can’t fully capitalize on it — the majority of data generated goes unused in decision making. Unified data fabric.
In this context, data management in an organization is a key point for the success of its projects involving data. One of the main aspects of correct data management is the definition of a dataarchitecture. The proposal is simple — “Trow everything you have here inside and worry later”.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structureddata) then enterprise-wide data lakes versus smaller, typically BU-Specific, “data ponds”.
Meanwhile, the visualization tool offers wide-ranging data connectors—from Azure SQL and SharePoint to Salesforce and Google Analytics—enabling quick access to structured and semi-structureddata. However, it leans more toward transforming and presenting cleaned data rather than processing raw datasets.
What is unstructured data? Definition and examples Unstructured data , in its simplest form, refers to any data that does not have a pre-defined structure or organization. It can come in different forms, such as text documents, emails, images, videos, social media posts, sensor data, etc.
At ProjectPro we had the pleasure to invite Abed Ajraou , the Director of the BI & Big Data in Solocal Group (Yellow Pages in France) to speak about the digital transformation from BI to Big Data. The goal of BI is to create intelligence through Data. The goal of BI is to create intelligence through Data.
It leverages a Massively Parallel Processing (MPP) architecture, which is optimized for executing complex analytical queries on large datasets efficiently. This makes it an excellent choice for organizations that need to analyze large volumes of structured and semi-structureddata quickly and effectively.
Unstructured data is problematic as it relates to data catalogs because it’s not organized, and if it is, it’s often not declared as organized. While modern dataarchitectures, including data lakes, are often distributed, data catalogs are usually not, treating data like a one-dimensional entity.
As a result, most companies are transforming into data-driven organizations harnessing the power of big data. Here Data Science becomes relevant as it deals with converting unstructured and messy data into structureddata sets for actionable business insights.
Data Transformation and ETL: Handle more complex data transformation and ETL (Extract, Transform, Load) processes, including handling data from multiple sources and dealing with complex datastructures. Ensure compliance with data protection regulations. Define dataarchitecture standards and best practices.
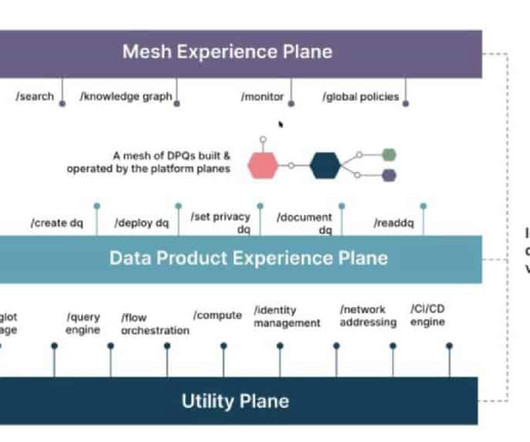
If you work with data, you’ll have come across the term data mesh by now. This decentralized but interconnected approach to structuringdata has become increasingly popular since the term was coined by Zhamak Dehghani 4 years ago. Essentially, you’re risking scaling up your problems along with your dataarchitecture.
We’ll take a closer look at variables that can impact your data next. Migration to the cloud Twenty years ago, your data warehouse (a place to transform and store structureddata) probably would have lived in an office basement, not on AWS or Azure. What is a decentralized dataarchitecture?
Big Data Processing In order to extract value or insights out of big data, one must first process it using big data processing software or frameworks, such as Hadoop. Big Query Google’s cloud data warehouse. Data Catalog An organized inventory of data assets relying on metadata to help with data management.
Read More: AI Data Platform: Key Requirements for Fueling AI Initiatives How Data Engineering Enables AI Data engineering is the backbone of AI’s potential to transform industries , offering the essential infrastructure that powers AI algorithms.
Binarized Search Trees: Simple dataarchitectures are grid search trees. They enable numerous solutions for a certain issue, letting the user choose the optimal datastructure to address the issue. The Benefits Of DataStructures. Utilizing a datastructure makes retrieving data from a storage source easier.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structureddata, and a data lake used to host large amounts of raw data.
The vessel positions data which in nature is a time series geospatial data set, was stored in both PostgreSQL and Cassandra to be able to support different use cases. Furthermore, as Windward introduced new use cases they started to hit limitations with their data stack.
Also, data lakes support ELT (Extract, Load, Transform) processes, in which transformation can happen after the data is loaded in a centralized store. A data lakehouse may be an option if you want the best of both worlds. Data sources can be broadly classified into three categories. Structureddata sources.
4 Purpose Utilize the derived findings and insights to make informed decisions The purpose of AI is to provide software capable enough to reason on the input provided and explain the output 5 Types of Data Different types of data can be used as input for the Data Science lifecycle.
The data goes through various stages, such as cleansing, processing, warehousing, and some other processes, before the data scientists start analyzing the data they have garnered. The data analysis stage is important as the data scientists extract value and knowledge from the processed, structureddata.
The emergence of cloud data warehouses, offering scalable and cost-effective data storage and processing capabilities, initiated a pivotal shift in data management methodologies. Extract The initial stage of the ELT process is the extraction of data from various source systems.
But a lot of data (by different estimations, 70 or 80 percent of all clinical data) remains unstructured , kept in textual reports, clinical notes, observations, and other narrative text. Unstructured data is unavoidable, yet extremely valuable. However useful, CDSSs are mostly limited to processing only structureddata.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both data lakes and data warehouses and this post will explain this all. What is a data lakehouse? Traditional data warehouse platform architecture. Unstructured and streaming data support.
Testing new functionality on their transactional data store is costly and can impact production. Ad hoc queries to measure the accuracy of the checkout process in real time are not possible with traditional dataarchitectures. Standard productionizes several endpoints a day using this methodology.
Data modeling involves creating a conceptual representation of data objects and their relationships to each other, as well as the rules governing those relationships. To design an effective data governance program, it’s crucial to choose an operational model that fits your business size and structure.
By letting you query data directly in the lake without the need for movement, Synapse cuts down the storage costs and eliminates data duplication. This capability fosters a more flexible dataarchitecture where data can be processed and analyzed in its raw form.
What data mesh is and is not. What data mesh IS. Data mesh is a set of principles for designing a modern distributed dataarchitecture that focuses on business domains, not the technology used, and treats data as a product. For example, your organization has an HR platform that produces employee data.
The SQL-on-Hadoop platform combines the Hadoop dataarchitecture with traditional SQL-style structureddata querying to create a specific analytical application tool. Data engineers can extract data from the Hadoop system using Hive and Impala , which offer an SQL-like interface.
Snowflake in Action at Western Union Snowflake's multi-cluster shared dataarchitecture expanded instantaneously to serve Western Union's data, users, and workloads without causing resource conflict. Snowflake saves and manages data on the cloud using a shared-disk approach, making data management simple.
Does data quality need to be high will directionally accurate suffice? Let the data drive the data pipeline architecture. Most data teams will be handling mostly structureddata for analytical purposes making a data warehouse based data pipeline architecture a natural fit.
Introduction Let’s get this out of the way at the beginning: understanding effective streaming dataarchitectures is hard, and understanding how to make use of streaming data for analytics is really hard. Kafka or Kinesis ? Stream processing or an OLAP database? Open source or fully managed?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content