This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Nowadays, organizations are looking for multiple solutions to deal with big data and related challenges. If you’re preparing for the Snowflake interview, […] The post A Comprehensive Guide Of Snowflake Interview Questions appeared first on Analytics Vidhya.
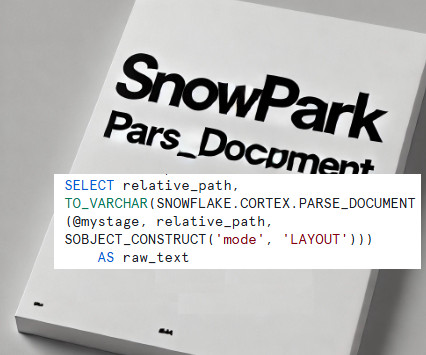
Apply advanced datacleansing and transformation logic using Python. Automate structured data insertion into Snowflake tables for downstream analytics. Use Case: Extracting Insurance Data from PDFs Imagine a scenario where an insurance company receives thousands of policy documents daily.
Here are several reasons data quality is critical for organizations: Informed decision making: Low-quality data can result in incomplete or incorrect information, which negatively affects an organization’s decision-making process. capitalization).
Also, data engineers are well-versed in distributed systems, cloud computing, and data modeling. Most data analysts are educated in mathematics, statistics, or a similar subject. Also, data analysts have a thorough comprehension of statistical ideas and methods.
AI-driven data quality workflows deploy machine learning to automate datacleansing, detect anomalies, and validate data. Integrating AI into data workflows ensures reliable data and enables smarter business decisions. Data quality is the backbone of successful data engineering projects.
In this article, we present six intrinsic data quality techniques that serve as both compass and map in the quest to refine the inner beauty of your data. Data Profiling 2. DataCleansing 3. Data Validation 4. Data Auditing 5. Data Governance 6. Table of Contents 1.
Error prevention: all of these data validation checks above contribute to a more proactive approach that minimizes the chance of downstream errors, and in turn, the effort required for datacleansing and correction later.
Finally, you should continuously monitor and update your data quality rules to ensure they remain relevant and effective in maintaining data quality. DataCleansingDatacleansing, also known as data scrubbing or data cleaning, is the process of identifying and correcting errors, inconsistencies, and inaccuracies in your data.
Data validation helps organizations maintain a high level of data quality by preventing errors and inconsistencies from entering the system. Datacleansing: This involves identifying and correcting errors or inaccuracies in the data.
IBM Databand IBM Databand is a powerful and comprehensive data testing tool that offers a wide range of features and functions. It provides capabilities for data profiling, datacleansing, data validation, and data transformation, as well as data integration, data migration, and data governance.
This not only enhances the accuracy and utility of the data but also significantly reduces the time and effort typically required for datacleansing. DataKitchen’s DataOps Observability stands out by providing: Intelligent Profiling: Automatic in-database profiling that adapts to the data’s unique characteristics.
Data veracity refers to the reliability and accuracy of data, encompassing factors such as data quality, integrity, consistency, and completeness. It involves assessing the quality of the data itself through processes like datacleansing and validation, as well as evaluating the credibility and trustworthiness of data sources.
Data profiling tools should be user-friendly and intuitive, enabling users to quickly and easily gain insights into their data. DataCleansingDatacleansing, also known as data scrubbing or data cleaning, is the process of identifying and correcting or removing errors, inconsistencies, and inaccuracies in data.
If you want to break into the field of data engineering but don't yet have any expertise in the field, compiling a portfolio of data engineering projects may help. Data pipeline best practices should be shown in these initiatives. In addition to this, they make sure that the data is always readily accessible to consumers.
After cleansingdata from all devices, the events can be dynamically routed to new Kafka topics, each of which represents a single device type. That device type may be extracted from a field in the original sensor data. final KStream<String, Event>[] cleansedEvents = events // …some datacleansing….
Data teams can create a job there to extract raw data from operational sources using JDBC connections or APIs. To avoid wasting computational work, and whenever possible, only the updated raw data since the last extraction should be incrementally added to the data product.
“According to Statista, the total volume of data was 64.2 ” In this day and age, the importance of good data collection and efficient datacleansing for better analysis has grown to become vital. The reason is straightforward: A data-driven decision is as good as […]
Lets dive into the components of data quality assurance and best practices. Table of Contents What is Data Quality Assurance? Data profiling and auditing Auditing and profiling your data can help your team to identify issues in the data that needs to be addressed, like data thats out-of-date, missing, or simply incorrect in any way.
Data pipelines often involve a series of stages where data is collected, transformed, and stored. This might include processes like data extraction from different sources, datacleansing, data transformation (like aggregation), and loading the data into a database or a data warehouse.
Read our eBook How to Solve the Top 10 Customer Master Data Challenges in SAP Learn more about SAP S/4HANA migration and the benefits of automation with Precisely. Read The Three Stages of SAP S/4HANA Migration Mass data manipulation is a requisite part of a large-scale migration effort. Read our free ebook.
Together, these seven services form one powerful data integrity foundation that accelerates your data integrity journey and provides the confidence you need for fast decision-making.
There are various ways to ensure data accuracy. Data validation involves checking data for errors, inconsistencies, and inaccuracies, often using predefined rules or algorithms. Datacleansing involves identifying and correcting errors, inconsistencies, and inaccuracies in data sets.
Data Processing and Cleaning : Preprocessing and data cleaning are important steps since raw data frequently has errors, duplication, missing information, and inconsistencies. To make sure the data is precise and suitable for analysis, data processing analysts use methods including datacleansing, imputation, and normalisation.
ETL Developer Roles and Responsibilities Below are the roles and responsibilities of an ETL developer: Extracting data from various sources such as databases, flat files, and APIs. Data Warehousing Knowledge of data cubes, dimensional modeling, and data marts is required.
Spark Streaming Kafka Streams 1 Data received from live input data streams is Divided into Micro-batched for processing. processes per data stream(real real-time) 2 A separate processing Cluster is required No separate processing cluster is required. it's better for functions like row parsing, datacleansing, etc.
You are designing a learning system to forecast Service Level Agreement (SLA) violations and would want to factor in all upstream dependencies and corresponding historical states.
In CASE you need more flexibility with your data…. There are numerous uses for it, and now KSQL supports it :yay: CASE: Datacleansing. Imagine you have an inbound stream of data, in which some of the values aren’t in the form that you want them. GitHub issue #620.
Today, no combination of open-source technologies approximate’s CDP’s built-in capabilities for automating tasks like data profiling, datacleansing, and data integration.
Consider taking a certification or advanced degree Being a certified data analyst gives you an edge in grabbing high-paying remote entry level data analyst jobs. It is always better to choose certifications that are globally recognized and build skills like datacleansing, data visualization, and so on.
Data profiling: Regularly analyze dataset content to identify inconsistencies or errors. Datacleansing: Implement corrective measures to address identified issues and improve dataset accuracy levels. Automated cleansing tools can correct common errors, such as duplicates or missing values, without manual intervention.
Let's dive into the top data cleaning techniques and best practices for the future – no mess, no fuss, just pure data goodness! What is Data Cleaning? It involves removing or correcting incorrect, corrupted, improperly formatted, duplicate, or incomplete data. Why Is Data Cleaning So Important?
Datacleansing. Before getting thoroughly analyzed, data ? In a nutshell, the datacleansing process involves scrubbing for any errors, duplications, inconsistencies, redundancies, wrong formats, etc. and as such confirming the usefulness and relevance of data for analytics. whether small or big ?
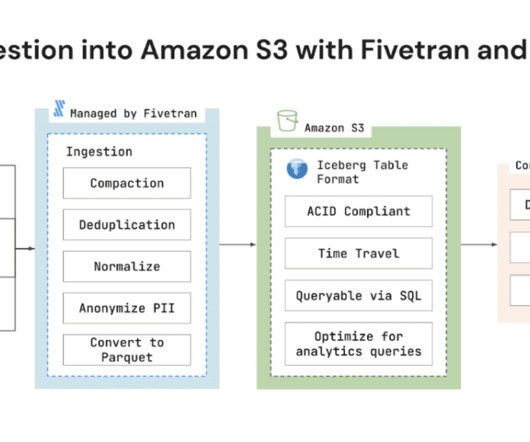
As organizations continue to leverage data lakes to run analytics and extract insights from their data, progressive marketing intelligence teams are demanding more of them, and solutions like Amazon S3 and automated pipeline support are meeting that demand.
As we move firmly into the data cloud era, data leaders need metrics for the robustness and reliability of the machine–the data pipelines, systems, and engineers–just as much as the final (data) product it spits out.
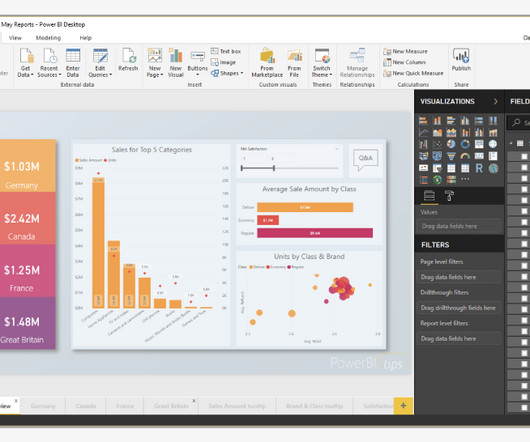
Tableau is mostly used to create data visualizations while Power BI is used for reporting. Does not offer any datacleansing solution and assumes that the data provided is of high quality. What are the disadvantages of Power BI? It is more useful to the Microsoft Excel users.
They will be able to further tune them for their own bespoke needs, with vast amounts of their own proprietary Snowflake-stored data, and data from Snowflake Marketplace and Data Cloud—all within their Snowflake accounts. They can also be fused directly into applications through Snowflake Native Applications and Streamlit.
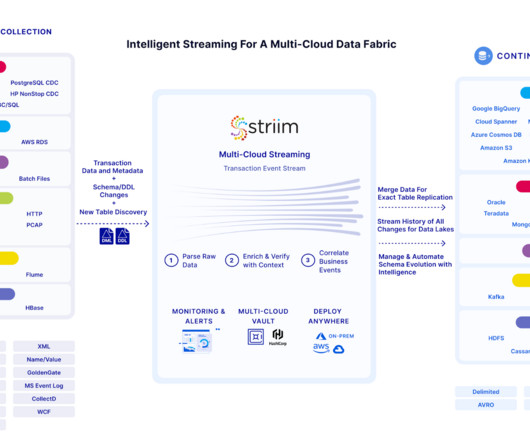
Enhanced Data Quality Striim incorporates robust data quality measures such as validation rules and datacleansing processes. By enforcing data quality standards throughout the integration pipeline, Striim ensures the integrity and accuracy of data.
Data quality Microsoft Power BI does not provide any datacleansing solution. Meaning it assumes that the data you are pulling has been cleaned up well in advance, and is of high quality. So, in case you need datacleansing aptitude, you might need to look for an alternate solution to cleanse your data.
AI can help improve prediction accuracy by analyzing large data sets and identifying patterns humans may miss. In addition to these two examples, AI can also help to improve the efficiency of other data management activities such as datacleansing, classification, and security.
This field uses several scientific procedures to understand structured, semi-structured, and unstructured data. It entails using various technologies, including data mining, data transformation, and datacleansing, to examine and analyze that data.
Data Governance Examples Here are some examples of data governance in practice: Data quality control: Data governance involves implementing processes for ensuring that data is accurate, complete, and consistent. This may involve data validation, datacleansing, and data enrichment activities.
This is again identified and fixed during datacleansing in data science before using it for our analysis or other purposes. Benefits of Data Cleaning in Data Scienece Your analysis will be reliable and free of bias if you have a clean and correct data collection.
As a data analyst , I would retrain the model as quick as possible to adjust with the changing behaviour of customers or change in market conditions. 5) What is datacleansing? Mention few best practices that you have followed while datacleansing. How to run a basic RNN model using Pytorch?
Poor data quality can lead to incorrect or misleading insights, which can have significant consequences for an organization. DataOps tools help ensure data quality by providing features like data profiling, data validation, and datacleansing.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content