This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Raw data, however, is frequently disorganised, unstructured, and challenging to work with directly. Dataprocessing analysts can be useful in this situation. Let’s take a deep dive into the subject and look at what we’re about to study in this blog: Table of Contents What Is DataProcessing Analysis?
AI-driven data quality workflows deploy machine learning to automate datacleansing, detect anomalies, and validate data. Integrating AI into data workflows ensures reliable data and enables smarter business decisions. Data quality is the backbone of successful data engineering projects.
Finally, you should continuously monitor and update your data quality rules to ensure they remain relevant and effective in maintaining data quality. DataCleansingDatacleansing, also known as data scrubbing or data cleaning, is the process of identifying and correcting errors, inconsistencies, and inaccuracies in your data.
What is Big Data? Big Data is the term used to describe extraordinarily massive and complicated datasets that are difficult to manage, handle, or analyze using conventional dataprocessing methods. The real-time or near-real-time nature of Big Data poses challenges in capturing and processingdata rapidly.
ETL developer is a software developer who uses various tools and technologies to design and implement dataintegrationprocesses across an organization. The role of an ETL developer is to extract data from multiple sources, transform it into a usable format and load it into a data warehouse or any other destination database.
DataOps , short for data operations, is an emerging discipline that focuses on improving the collaboration, integration, and automation of dataprocesses across an organization. Each type of tool plays a specific role in the DataOps process, helping organizations manage and optimize their data pipelines more effectively.
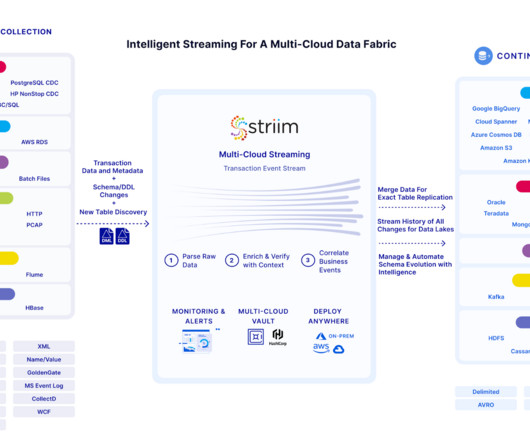
Data Fabric is a comprehensive data management approach that goes beyond traditional methods , offering a framework for seamless integration across diverse sources. The 4 Key Pillars of Data Fabric DataIntegration: Breaking Down Silos At the core of Data Fabric is the imperative need for seamless dataintegration.
Transformation: Shaping Data for the Future: LLMs facilitate standardizing date formats with precision and translation of complex organizational structures into logical database designs, streamline the definition of business rules, automate datacleansing, and propose the inclusion of external data for a more complete analytical view.
Challenges of Legacy Data Architectures Some of the main challenges associated with legacy data architectures include: Lack of flexibility: Traditional data architectures are often rigid and inflexible, making it difficult to adapt to changing business needs and incorporate new data sources or technologies.
There are also client layers where all data management activities happen. When data is in place, it needs to be converted into the most digestible forms to get actionable results on analytical queries. For that purpose, different dataprocessing options exist. This, in turn, makes it possible to processdata in parallel.
The emergence of cloud data warehouses, offering scalable and cost-effective data storage and processing capabilities, initiated a pivotal shift in data management methodologies. This approach ensures that only processed and refined data is housed in the data warehouse, leaving the raw data outside of it.
A Beginner’s Guide [SQ] Niv Sluzki July 19, 2023 ELT is a dataprocessing method that involves extracting data from its source, loading it into a database or data warehouse, and then later transforming it into a format that suits business needs. The extraction process requires careful planning to ensure dataintegrity.
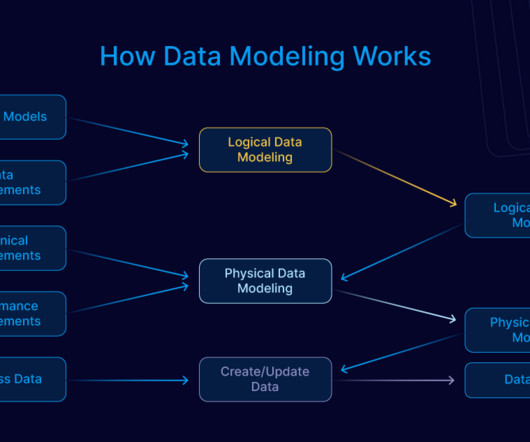
Data modeling for AI involves making a structured framework that helps AI systems efficiently process, analyze, and understand data to make smart decisions: The 5 Funda mentals: DataCleansing and Validation : Provide data accuracy and consistency by addressing errors, missing values, and inconsistencies.
Let's dive into the top data cleaning techniques and best practices for the future – no mess, no fuss, just pure data goodness! What is Data Cleaning? It involves removing or correcting incorrect, corrupted, improperly formatted, duplicate, or incomplete data. Why Is Data Cleaning So Important?
These experts will need to combine their expertise in dataprocessing, storage, transformation, modeling, visualization, and machine learning algorithms, working together on a unified platform or toolset.
The significance of data engineering in AI becomes evident through several key examples: Enabling Advanced AI Models with Clean Data The first step in enabling AI is the provision of high-quality, structured data. ChatGPT screenshot of AI-generated Python code and an explanation of what it means.
Photo by Markus Spiske on Unsplash Introduction Senior data engineers and data scientists are increasingly incorporating artificial intelligence (AI) and machine learning (ML) into data validation procedures to increase the quality, efficiency, and scalability of data transformations and conversions.
For instance, automating data cleaning and transformation can save time and reduce errors in the dataprocessing stage. Together, automation and DataOps are transforming the way businesses approach data analytics, making it faster, more accurate, and more efficient.
Integratingdata from numerous, disjointed sources and processing it to provide context provides both opportunities and challenges. One of the ways to overcome challenges and gain more opportunities in terms of dataintegration is to build an ELT (Extract, Load, Transform) pipeline. What is ELT? Aggregation.
Data usability ensures that data is available in a structured format that is compatible with traditional business tools and software. Dataintegrity is about maintaining the quality of data as it is stored, converted, transmitted, and displayed. Learn more about dataintegrity in our dedicated article.
This project is an opportunity for data enthusiasts to engage in the information produced and used by the New York City government. to accumulate data over a given period for better analysis. There are many more aspects to it and one can learn them better if they work on a sample data aggregation project.
First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based data warehouse. Central Source of Truth for Analytics A Cloud Data Warehouse (CDW) is a type of database that provides analytical dataprocessing and storage capabilities within a cloud-based infrastructure.
Data Storage: The next step after data ingestion is to store it in HDFS or a NoSQL database such as HBase. HBase storage is ideal for random read/write operations, whereas HDFS is designed for sequential processes. DataProcessing: This is the final step in deploying a big data model. How to avoid the same.
DataIntegration at Scale Most data architectures rely on a single source of truth. Having multiple dataintegration routes helps optimize the operational as well as analytical use of data. Data Volumes and Veracity Data volume and quality decide how fast the AI System is ready to scale.
Efficient data pipelines are necessary for AI systems to perform well since AI models need clean and organized as well as fresh datasets in order to learn and predict accurately. Au tomation in modern data engineering has a new dimension. It ensures a seamless flow of data within the pipelines with minimum human contact.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content