This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data quality can be influenced by various factors, such as data collection methods, data entry processes, data storage, and dataintegration. Maintaining high data quality is crucial for organizations to gain valuable insights, make informed decisions, and achieve their goals.
Data Accuracy vs DataIntegrity: Similarities and Differences Eric Jones August 30, 2023 What Is Data Accuracy? Data accuracy refers to the degree to which data is correct, precise, and free from errors. In other words, it measures the closeness of a piece of data to its true value.
And yet less than half (46%) rate their ability to trust data for decision-making as “high” or “very high.” Accurate, confident decision-making requires trusted data. And trusted data needs dataintegrity – maximum accuracy, consistency, and context. That’s where the Precisely DataIntegrity Suite comes in.
Read Turning Raw Data into Meaningful Insights Even though organizations value data-driven decision-making more than ever before, data quality remains a major barrier across industries. So how does the data validation process help on the journey to better data quality and ultimately, dataintegrity?
However, the data is not valid because the height information is incorrect – penguins have the height data for giraffes, and vice versa. The data doesn’t accurately represent the real heights of the animals, so it lacks validity. What is DataIntegrity? How Do You Maintain DataIntegrity?
The distance between the owner and the domain that generated the data is key to expedite further analytical development. Discoverability : A shared data platform provides a catalog of operational datasets in the form of source-aligned data products that helped me to understand the status and nature of the data exposed.
AI-driven data quality workflows deploy machine learning to automate datacleansing, detect anomalies, and validate data. Integrating AI into data workflows ensures reliable data and enables smarter business decisions. Data quality is the backbone of successful data engineering projects.
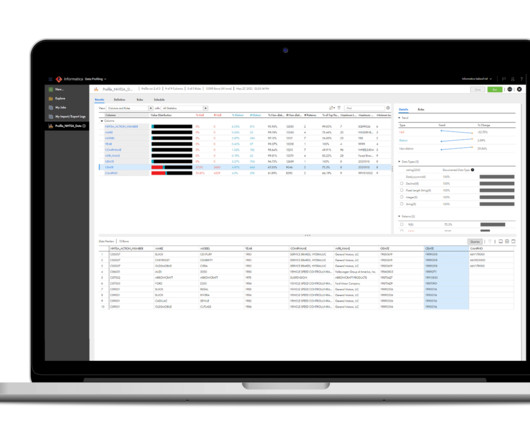
Data profiling tools: Profiling plays a crucial role in understanding your dataset’s structure and content. This is part of a series of articles about data quality. In this article: Why Are Data Testing Tools Important?
Validity: Adherence to predefined formats, rules, or standards for each attribute within a dataset. Uniqueness: Ensuring that no duplicate records exist within a dataset. Integrity: Maintaining referential relationships between datasets without any broken links.
Consider exploring relevant Big Data Certification to deepen your knowledge and skills. What is Big Data? Big Data is the term used to describe extraordinarily massive and complicated datasets that are difficult to manage, handle, or analyze using conventional data processing methods.
As you now know the key characteristics, it gets clear that not all data can be referred to as Big Data. What is Big Data analytics? Big Data analytics is the process of finding patterns, trends, and relationships in massive datasets that can’t be discovered with traditional data management techniques and tools.
Data Landscape Design Goals At the project inception stage, we defined a set of design goals to help guide the architecture and development work for data lineage to deliver a complete, accurate, reliable and scalable lineage system mapping Netflix’s diverse data landscape.
This includes defining roles and responsibilities related to managing datasets and setting guidelines for metadata management. Data profiling: Regularly analyze dataset content to identify inconsistencies or errors. Automated profiling tools can quickly detect anomalies or patterns indicating potential datasetintegrity issues.
Let's dive into the top data cleaning techniques and best practices for the future – no mess, no fuss, just pure data goodness! What is Data Cleaning? It involves removing or correcting incorrect, corrupted, improperly formatted, duplicate, or incomplete data. Why Is Data Cleaning So Important?
Data profiling tools: Profiling plays a crucial role in understanding your dataset’s structure and content. This is part of a series of articles about data quality. In this article: Why are data testing tools important?
Over the years, the field of data engineering has seen significant changes and paradigm shifts driven by the phenomenal growth of data and by major technological advances such as cloud computing, data lakes, distributed computing, containerization, serverless computing, machine learning, graph database, etc.
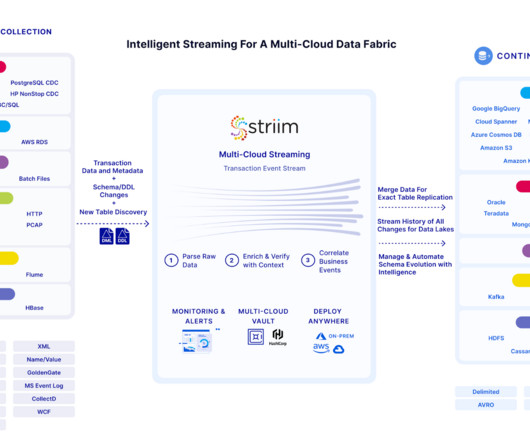
Data Fabric is a comprehensive data management approach that goes beyond traditional methods , offering a framework for seamless integration across diverse sources. The 4 Key Pillars of Data Fabric DataIntegration: Breaking Down Silos At the core of Data Fabric is the imperative need for seamless dataintegration.
Data Processing and Cleaning : Preprocessing and data cleaning are important steps since raw data frequently has errors, duplication, missing information, and inconsistencies. To make sure the data is precise and suitable for analysis, data processing analysts use methods including datacleansing, imputation, and normalisation.
This data and reports are generated and developed by Power BI developers. A Power BI developer is a business intelligence personnel who thoroughly understands business intelligence, dataintegration, data warehousing, modeling, database administration, and technical aspects of BI systems.
Whether it's aggregating customer interactions, analyzing historical sales trends, or processing real-time sensor data, data extraction initiates the process. What is the purpose of extracting data? The purpose of data extraction is to transform large, unwieldy datasets into a usable and actionable format.
More importantly, we will contextualize ELT in the current scenario, where data is perpetually in motion, and the boundaries of innovation are constantly being redrawn. For example: Aggregating Data: This includes summing up numerical values and applying mathematical functions to create summarized insights from the raw data.
Photo by Markus Spiske on Unsplash Introduction Senior data engineers and data scientists are increasingly incorporating artificial intelligence (AI) and machine learning (ML) into data validation procedures to increase the quality, efficiency, and scalability of data transformations and conversions.
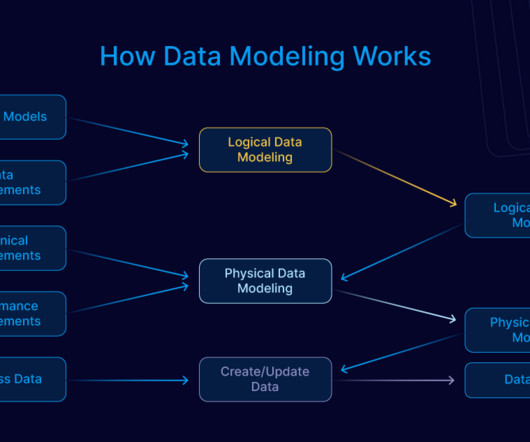
Data modeling for AI involves making a structured framework that helps AI systems efficiently process, analyze, and understand data to make smart decisions: The 5 Funda mentals: DataCleansing and Validation : Provide data accuracy and consistency by addressing errors, missing values, and inconsistencies.
When crucial information is omitted or unavailable, the analysis or conclusions drawn from the data may be flawed or misleading. Inconsistent data: Inconsistencies within a dataset can indicate inaccuracies. This can include contradictory information or data points that do not align with established patterns or trends.
The significance of data engineering in AI becomes evident through several key examples: Enabling Advanced AI Models with Clean Data The first step in enabling AI is the provision of high-quality, structured data. ChatGPT screenshot showing the schema of a dataset and the documentation for it.
It effectively works with Tableau Desktop and Tableau Server to allow users to publish bookmarked, cleaned-up data sources that can be accessed by other personnel within the same organization. This capability underpins sustainable, chattel datacleansing practices requisite to data governance.
And if you are aspiring to become a data engineer, you must focus on these skills and practice at least one project around each of them to stand out from other candidates. Explore different types of Data Formats: A data engineer works with various dataset formats like.csv,josn,xlx, etc.
However, managing complex data networks and ensuring data quality and security across different systems can be a daunting challenge. Hence, companies must prioritize interconnectivity and invest in robust dataintegration and management solutions that handle the increasing volume and complexity of data.
To do this the data driven approach that today’s company’s employ must be more adaptable and susceptible to change because if the EDW/BI systems fails to provide this, how will the change in information be addressed.? DaaS involves supplying data from a wide variety of sources through API and on demand designed for simplifying data access.
MapReduce is a Hadoop framework used for processing large datasets. Another name for it is a programming model that enables us to process big datasets across computer clusters. This program allows for distributed data storage, simplifying complex processing and vast amounts of data. What is MapReduce in Hadoop?
This complexity often necessitates the involvement of numerous experts who specialize in these individual systems to effectively extract the data. Enter Fivetran Fivetran automates the dataintegration process, helping reduce the overall effort required to manage data movement from different sources into your data warehouse.
DataIntegration at Scale Most data architectures rely on a single source of truth. Having multiple dataintegration routes helps optimize the operational as well as analytical use of data. Data Volumes and Veracity Data volume and quality decide how fast the AI System is ready to scale.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content