This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data Landscape Design Goals At the project inception stage, we defined a set of design goals to help guide the architecture and development work for data lineage to deliver a complete, accurate, reliable and scalable lineage system mapping Netflix’s diverse data landscape. push or pull.
Sales Orders DP exposing sales_orders_dataset (image by the author) The data pipeline in charge of maintaining the data product could be defined like this: Data pipeline steps (image by the author) Data extraction The first step to building source-aligned data products is to extract the data we want to expose from operational sources.
Finally, you should continuously monitor and update your data quality rules to ensure they remain relevant and effective in maintaining data quality. DataCleansingDatacleansing, also known as data scrubbing or data cleaning, is the process of identifying and correcting errors, inconsistencies, and inaccuracies in your data.
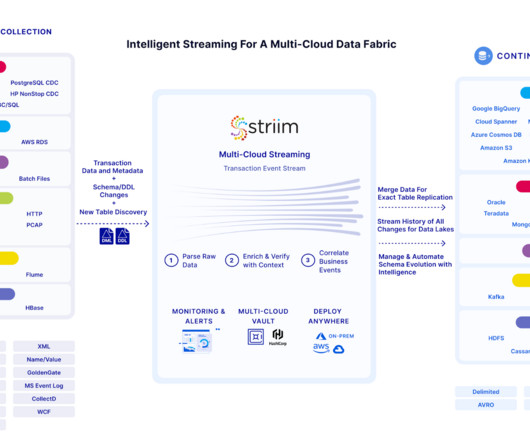
Data Fabric is a comprehensive data management approach that goes beyond traditional methods , offering a framework for seamless integration across diverse sources. The 4 Key Pillars of Data Fabric DataIntegration: Breaking Down Silos At the core of Data Fabric is the imperative need for seamless dataintegration.
Transformation: Shaping Data for the Future: LLMs facilitate standardizing date formats with precision and translation of complex organizational structures into logical database designs, streamline the definition of business rules, automate datacleansing, and propose the inclusion of external data for a more complete analytical view.
This includes defining roles and responsibilities related to managing datasets and setting guidelines for metadata management. Data profiling: Regularly analyze dataset content to identify inconsistencies or errors. Automated profiling tools can quickly detect anomalies or patterns indicating potential dataset integrity issues.
By using DataOps tools, organizations can break down silos, reduce time-to-insight, and improve the overall quality of their data analytics processes. DataOps tools can be categorized into several types, including dataintegration tools, data quality tools, data catalog tools, data orchestration tools, and data monitoring tools.
The significance of data engineering in AI becomes evident through several key examples: Enabling Advanced AI Models with Clean Data The first step in enabling AI is the provision of high-quality, structured data.
Data Governance Examples Here are some examples of data governance in practice: Data quality control: Data governance involves implementing processes for ensuring that data is accurate, complete, and consistent. This may involve data validation, datacleansing, and data enrichment activities.
In a DataOps architecture, it’s crucial to have an efficient and scalable data ingestion process that can handle data from diverse sources and formats. This requires implementing robust dataintegration tools and practices, such as data validation, datacleansing, and metadata management.
Integrating these principles with data operation-specific requirements creates a more agile atmosphere that supports faster development cycles while maintaining high quality standards. This demands the implementation of advanced dataintegration techniques, such as real-time streaming ingestion, batch processing, and API-based access.
System or technical errors: Errors within the data storage, retrieval, or analysis systems can introduce inaccuracies. This can include software bugs, hardware malfunctions, or dataintegration issues that lead to incorrect calculations, transformations, or aggregations. is the gas station actually where the map says it is?).
Integratingdata from numerous, disjointed sources and processing it to provide context provides both opportunities and challenges. One of the ways to overcome challenges and gain more opportunities in terms of dataintegration is to build an ELT (Extract, Load, Transform) pipeline. What is ELT? Aggregation. Enrichment.
Data usability ensures that data is available in a structured format that is compatible with traditional business tools and software. Dataintegrity is about maintaining the quality of data as it is stored, converted, transmitted, and displayed. Learn more about dataintegrity in our dedicated article.
This project is an opportunity for data enthusiasts to engage in the information produced and used by the New York City government. You will explore various Azure apps like Azure Logic Apps, Azure Storage Account, Azure Data Factory, and Azure SQL Databases and work on the dataset of a hospital that has information for 30 different variables.
Why is HDFS only suitable for large data sets and not the correct tool for many small files? NameNode is often given a large space to contain metadata for large-scale files. The metadata should come from a single file for optimal space use and economic benefit. And storing these metadata in RAM will become problematic.
This complexity often necessitates the involvement of numerous experts who specialize in these individual systems to effectively extract the data. Enter Fivetran Fivetran automates the dataintegration process, helping reduce the overall effort required to manage data movement from different sources into your data warehouse.
DataIntegration at Scale Most data architectures rely on a single source of truth. Having multiple dataintegration routes helps optimize the operational as well as analytical use of data. Data Volumes and Veracity Data volume and quality decide how fast the AI System is ready to scale.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content