This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Operational datamanagement in Data Mesh A Data Mesh implementation improved my experience in these aspects: Knowledge : I could quickly identify the owners of the exposed data. The distance between the owner and the domain that generated the data is key to expedite further analytical development.
Our data ingestion approach, in a nutshell, is classified broadly into two buckets?—?push In this model, we scan system logs and metadata generated by various compute engines to collect corresponding lineage data. push or pull. Today, we are operating using a pull-heavy model.
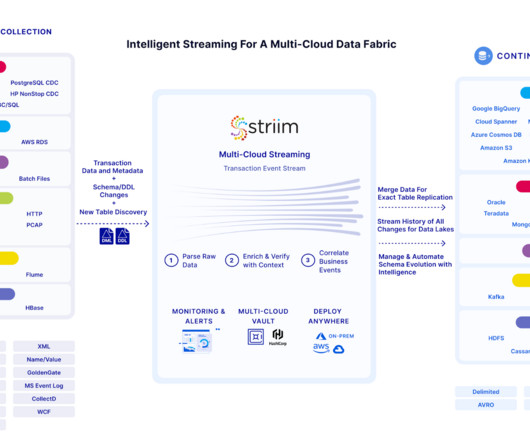
Data Fabric is a comprehensive datamanagement approach that goes beyond traditional methods , offering a framework for seamless integration across diverse sources. By upholding data quality, organizations can trust the information they rely on for decision-making, fostering a data-driven culture built on dependable insights.
This includes defining roles and responsibilities related to managing datasets and setting guidelines for metadatamanagement. Data profiling: Regularly analyze dataset content to identify inconsistencies or errors. Data profiling: Regularly analyze dataset content to identify inconsistencies or errors.
It involves establishing a framework for datamanagement that ensures data quality, privacy, security, and compliance with regulatory requirements. The mix of people, procedures, technologies, and systems ensures that the data within a company is reliable, safe, and simple for employees to access.
The architecture is three layered: Database Storage: Snowflake has a mechanism to reorganize the data into its internal optimized, compressed and columnar format and stores this optimized data in cloud storage. This stage handles all the aspects of data storage like organization, file size, structure, compression, metadata, statistics.
DataOps , short for data operations, is an emerging discipline that focuses on improving the collaboration, integration, and automation of data processes across an organization. These tools help organizations implement DataOps practices by providing a unified platform for data teams to collaborate, share, and manage their data assets.
The significance of data engineering in AI becomes evident through several key examples: Enabling Advanced AI Models with Clean Data The first step in enabling AI is the provision of high-quality, structured data. However, the reality of AI’s impact on data engineering is far more nuanced and, in many ways, reassuring.
DataOps is a collaborative approach to datamanagement that combines the agility of DevOps with the power of data analytics. It aims to streamline data ingestion, processing, and analytics by automating and integrating various data workflows.
There are several key practices and steps: Before embarking on the ETL process, it’s essential to understand the nature and quality of the source data through data profiling. Datacleansing is the process of identifying and correcting or removing inaccurate records from the dataset, improving the data quality.
Instead of relying on traditional hierarchical structures and predefined schemas, as in the case of data warehouses, a data lake utilizes a flat architecture. This structure is made efficient by data engineering practices that include object storage. Watch our video explaining how data engineering works.
Integrating these principles with data operation-specific requirements creates a more agile atmosphere that supports faster development cycles while maintaining high quality standards. Organizations need to automate various aspects of their data operations, including data integration, data quality, and data analytics.
This raw data from the devices needs to be enriched with content metadata and geolocation information before it can be processed and analyzed. Design for Human Efficiency An additional challenge that probably most other small companies face is the way data engineering and data analysis teams spend their time and resources.
However, decentralized models may result in inconsistent and duplicate master data. There’s a centralized structure that provides a framework, which is then used by autonomous departments that own their data and metadata. Datamanagement is the overall process of collecting, storing, organizing, maintaining, and using data.
Database Storage The Snowflake architecture’s database storage layer organizes data into multiple tiny partitions, which are compressed and optimized internally. Snowflake stores and managesdata in the cloud using a shared disk approach, which simplifies datamanagement.
As a Data Engineer, you must: Work with the uninterrupted flow of data between your server and your application. Work closely with software engineers and data scientists. Technical Data Engineer Skills 1.Python
Define Big Data and Explain the Seven Vs of Big Data. Big Data is a collection of large and complex semi-structured and unstructured data sets that have the potential to deliver actionable insights using traditional datamanagement tools. And storing these metadata in RAM will become problematic.
To truly understand its potential, we need to explore the benefits it brings, particularly when transitioning from traditional datamanagement structures. Why Migrate to a Modern Data Stack? This centralization streamlines datamanagement. Allowing data diff analysis and code generation.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content