This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Raw data, however, is frequently disorganised, unstructured, and challenging to work with directly. Dataprocessing analysts can be useful in this situation. Let’s take a deep dive into the subject and look at what we’re about to study in this blog: Table of Contents What Is DataProcessing Analysis?
AI-driven data quality workflows deploy machine learning to automate datacleansing, detect anomalies, and validate data. Integrating AI into data workflows ensures reliable data and enables smarter business decisions. Data quality is the backbone of successful data engineering projects.
If you want to break into the field of data engineering but don't yet have any expertise in the field, compiling a portfolio of data engineering projects may help. Data pipeline best practices should be shown in these initiatives. Source Code: Finnhub API with Kafka for Real-Time Financial Market Data Pipeline 3.
Spark Streaming Kafka Streams 1 Data received from live input data streams is Divided into Micro-batched for processing. processes per data stream(real real-time) 2 A separate processing Cluster is required No separate processing cluster is required. Looking to dive into the world of data science?
Finally, you should continuously monitor and update your data quality rules to ensure they remain relevant and effective in maintaining data quality. DataCleansingDatacleansing, also known as data scrubbing or data cleaning, is the process of identifying and correcting errors, inconsistencies, and inaccuracies in your data.
What is Big Data? Big Data is the term used to describe extraordinarily massive and complicated datasets that are difficult to manage, handle, or analyze using conventional dataprocessing methods. The real-time or near-real-time nature of Big Data poses challenges in capturing and processingdata rapidly.
Data pipelines often involve a series of stages where data is collected, transformed, and stored. This might include processes like data extraction from different sources, datacleansing, data transformation (like aggregation), and loading the data into a database or a data warehouse.
ETL Developer Roles and Responsibilities Below are the roles and responsibilities of an ETL developer: Extracting data from various sources such as databases, flat files, and APIs. Data Warehousing Knowledge of data cubes, dimensional modeling, and data marts is required.
DataOps , short for data operations, is an emerging discipline that focuses on improving the collaboration, integration, and automation of dataprocesses across an organization. Accelerated Data Analytics DataOps tools help automate and streamline various dataprocesses, leading to faster and more efficient data analytics.
A Beginner’s Guide [SQ] Niv Sluzki July 19, 2023 ELT is a dataprocessing method that involves extracting data from its source, loading it into a database or data warehouse, and then later transforming it into a format that suits business needs. This can be achieved through datacleansing and data validation.
There are also client layers where all data management activities happen. When data is in place, it needs to be converted into the most digestible forms to get actionable results on analytical queries. For that purpose, different dataprocessing options exist. This, in turn, makes it possible to processdata in parallel.
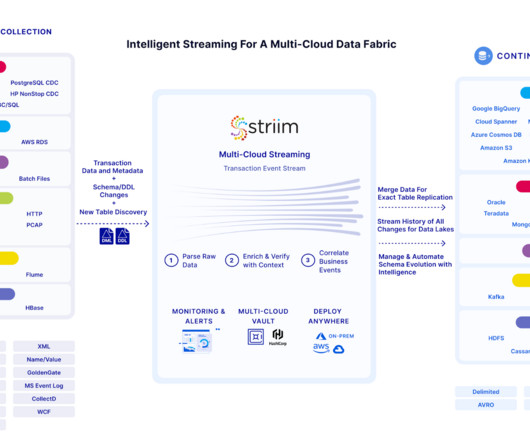
Its flexible and scalable data integration backbone supports real-time data delivery via intelligent pipelines that span hybrid cloud and multi-cloud environments. Striim continuously ingests transaction data and metadata from on-premise and cloud sources.
Due to its strong data analysis and manipulation skills, it has significantly increased its prominence in the field of data science. Python offers a strong ecosystem for data scientists to carry out activities like datacleansing, exploration, visualization, and modeling thanks to modules like NumPy, Pandas, and Matplotlib.
Challenges of Legacy Data Architectures Some of the main challenges associated with legacy data architectures include: Lack of flexibility: Traditional data architectures are often rigid and inflexible, making it difficult to adapt to changing business needs and incorporate new data sources or technologies.
Let's dive into the top data cleaning techniques and best practices for the future – no mess, no fuss, just pure data goodness! What is Data Cleaning? It involves removing or correcting incorrect, corrupted, improperly formatted, duplicate, or incomplete data. Why Is Data Cleaning So Important?
Whether it is intended for analytics purposes, application development, or machine learning, the aim of data ingestion is to ensure that data is accurate, consistent, and ready to be utilized. It is a crucial step in the dataprocessing pipeline, and without it, we’d be lost in a sea of unusable data.
Data modeling for AI involves making a structured framework that helps AI systems efficiently process, analyze, and understand data to make smart decisions: The 5 Funda mentals: DataCleansing and Validation : Provide data accuracy and consistency by addressing errors, missing values, and inconsistencies.
This is again identified and fixed during datacleansing in data science before using it for our analysis or other purposes. Benefits of Data Cleaning in Data Scienece Your analysis will be reliable and free of bias if you have a clean and correct data collection.
Cloud-Native Data Engineering: Overview: Embracing cloud-native approaches will redefine how data engineering is done, leveraging the scalability and flexibility of cloud platforms. Applications: Seamless integration with cloud services, improved resource utilization, and enhanced dataprocessing capabilities.
Transformation: Shaping Data for the Future: LLMs facilitate standardizing date formats with precision and translation of complex organizational structures into logical database designs, streamline the definition of business rules, automate datacleansing, and propose the inclusion of external data for a more complete analytical view.
The pipelines and workflows that ingest data, process it and output charts, dashboards, or other analytics resemble a production pipeline. The execution of these pipelines is called data operations or data production. Data sources must deliver error-free data on time. Dataprocessing must work perfectly.
The emergence of cloud data warehouses, offering scalable and cost-effective data storage and processing capabilities, initiated a pivotal shift in data management methodologies. Developer Resources: While custom-built ETL processes are an option, they can be resource-intensive and costly.
Big Data Uses in Cloud Computing Scalable and Affordable DataProcessing and Storage: Cloud computing has become a beloved trend because it allows companies to leverage dataprocessing and analytic services beyond their capability.
These experts will need to combine their expertise in dataprocessing, storage, transformation, modeling, visualization, and machine learning algorithms, working together on a unified platform or toolset.
The first step is capturing data, extracting it periodically, and adding it to the pipeline. The next step includes several activities: database management, dataprocessing, datacleansing, database staging, and database architecture. Consequently, dataprocessing is a fundamental part of any Data Science project.
The significance of data engineering in AI becomes evident through several key examples: Enabling Advanced AI Models with Clean Data The first step in enabling AI is the provision of high-quality, structured data. ChatGPT screenshot of AI-generated Python code and an explanation of what it means.
This involves the implementation of processes and controls that help ensure the accuracy, completeness, and consistency of data. Data quality management can include data validation, datacleansing, and the enforcement of data standards.
The goal of a big data crowdsourcing model is to accomplish the given tasks quickly and effectively at a lower cost. Crowdsource workers can perform several tasks for big data operations like- datacleansing, data validation, data tagging, normalization and data entry.
The following statement lists all the files contained in the internal named stage: List @my_internal_stage; There are several scenarios where internal stages can be used, including: Data Staging: If you need to temporarily store data within Snowflake for processing or analysis, internal stages can be used as a staging area.
For instance, automating data cleaning and transformation can save time and reduce errors in the dataprocessing stage. Together, automation and DataOps are transforming the way businesses approach data analytics, making it faster, more accurate, and more efficient.
This proactive feedback mechanism helps senior data engineers and data scientists address issues quickly, reducing downtime and ensuring accurate analytics deliverables. How ItWorks AI-based datacleansing models detect common errors introduced during conversions (e.g.,
Different instance types offer varying levels of compute power, memory, and storage, which directly influence tasks such as dataprocessing, application responsiveness, and overall system throughput. In-Memory Caching- Memory-optimized instances are suitable for in-memory caching solutions, enhancing the speed of data access.
Data engineers design, manage, test, maintain, store, and work on the data infrastructure that allows easy access to structured and unstructured data. Data engineers need to work with large amounts of data and maintain the architectures used in various data science projects. Technical Data Engineer Skills 1.Python
ELT makes it easier to manage and access all this information by allowing both raw and cleaned data to be loaded and stored for further analysis. With the ETL shift from a traditional on-premise variant to a cloud solution, you can also use it to work with different data sources and move a lot of data. Aggregation.
The first step is to compile the pertinent data and business requirements. Data warehousing, datacleansing, architecture, and staging are used to store data after it has been gathered. .
The Need for Operational Analytics The clickstream data scenario has some well-defined patterns with proven options for data ingestion: streaming and messaging systems like Kafka and Pulsar, data routing and transformation with Apache NiFi, dataprocessing with Spark, Flink or Kafka Streams.
This project is an opportunity for data enthusiasts to engage in the information produced and used by the New York City government. to accumulate data over a given period for better analysis. There are many more aspects to it and one can learn them better if they work on a sample data aggregation project.
Apache Kafka and AWS Kinesis are popular tools for handling real-time data ingestion. Video explaining how data streaming works. After residing in the raw zone, data undergoes various transformations. This section is highly versatile, supporting both batch and stream processing.
Source: McKinsy&Company For example, a data science team may spend 70 to 80 percent of their time preparing data for machine learning projects , with a prevailing part of this time being spent on datacleansing alone. Learn how data is prepared for machine learning in our dedicated video.
Geocoding Finding geographic coordinates for place names, street addresses, and codes is a process known as geocoding (e.g., Preprocessing and standardizing the format of the data you will be geocoding are often steps in the datacleansingprocess that come before geocoding. zip codes).
2) Your Data Analytics Projects Understanding a business problem, extracting data with SQL, datacleansing and validation using Python or R , and lastly, visualizing the insights for successful business choices are all part of a data analyst's job description.
Data Storage: The next step after data ingestion is to store it in HDFS or a NoSQL database such as HBase. HBase storage is ideal for random read/write operations, whereas HDFS is designed for sequential processes. DataProcessing: This is the final step in deploying a big data model. How to avoid the same.
First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based data warehouse. Central Source of Truth for Analytics A Cloud Data Warehouse (CDW) is a type of database that provides analytical dataprocessing and storage capabilities within a cloud-based infrastructure.
Data Volumes and Veracity Data volume and quality decide how fast the AI System is ready to scale. The larger the set of predictions and usage, the larger is the implications of Data in the workflow. Complex Technology Implications at Scale Onerous DataCleansing & Preparation Tasks 3.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content