This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
High-quality data is essential for making well-informed decisions, performing accurate analyses, and developing effective strategies. Data quality can be influenced by various factors, such as data collection methods, data entry processes, datastorage, and data integration. capitalization).
AI-driven data quality workflows deploy machine learning to automate datacleansing, detect anomalies, and validate data. Integrating AI into data workflows ensures reliable data and enables smarter business decisions. Data quality is the backbone of successful data engineering projects.
Data integrity tools are software applications or systems designed to ensure the accuracy, consistency, and reliability of data stored in databases, spreadsheets, or other datastorage systems. By doing so, data integrity tools enable organizations to make better decisions based on accurate, trustworthy information.
ELT offers a solution to this challenge by allowing companies to extract data from various sources, load it into a central location, and then transform it for analysis. The ELT process relies heavily on the power and scalability of modern datastorage systems. The data is loaded as-is, without any transformation.
Data pipelines often involve a series of stages where data is collected, transformed, and stored. This might include processes like data extraction from different sources, datacleansing, data transformation (like aggregation), and loading the data into a database or a data warehouse.
If you want to break into the field of data engineering but don't yet have any expertise in the field, compiling a portfolio of data engineering projects may help. Data pipeline best practices should be shown in these initiatives. In addition to this, they make sure that the data is always readily accessible to consumers.
However, Big Data encompasses unstructured data, including text documents, images, videos, social media feeds, and sensor data. Handling this variety of data requires flexible datastorage and processing methods. Veracity: Veracity in big data means the quality, accuracy, and reliability of data.
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. Datastorage and processing. Datacleansing.
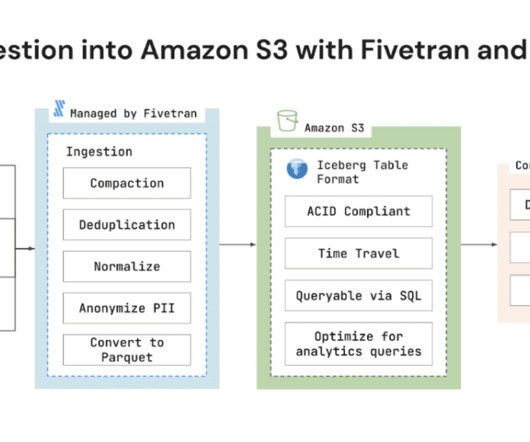
As organizations continue to leverage data lakes to run analytics and extract insights from their data, progressive marketing intelligence teams are demanding more of them, and solutions like Amazon S3 and automated pipeline support are meeting that demand.
DataOps Architecture Legacy data architectures, which have been widely used for decades, are often characterized by their rigidity and complexity. These systems typically consist of siloed datastorage and processing environments, with manual processes and limited collaboration between teams.
Data Processing and Cleaning : Preprocessing and data cleaning are important steps since raw data frequently has errors, duplication, missing information, and inconsistencies. To make sure the data is precise and suitable for analysis, data processing analysts use methods including datacleansing, imputation, and normalisation.
ETL Developer Roles and Responsibilities Below are the roles and responsibilities of an ETL developer: Extracting data from various sources such as databases, flat files, and APIs. Data Warehousing Knowledge of data cubes, dimensional modeling, and data marts is required.
The architecture is three layered: Database Storage: Snowflake has a mechanism to reorganize the data into its internal optimized, compressed and columnar format and stores this optimized data in cloud storage. The data objects are accessible only through SQL query operations run using Snowflake.
Consider taking a certification or advanced degree Being a certified data analyst gives you an edge in grabbing high-paying remote entry level data analyst jobs. It is always better to choose certifications that are globally recognized and build skills like datacleansing, data visualization, and so on.
Data Governance Examples Here are some examples of data governance in practice: Data quality control: Data governance involves implementing processes for ensuring that data is accurate, complete, and consistent. This may involve data validation, datacleansing, and data enrichment activities.
AI-Driven Data Engineering: Overview: Integration of artificial intelligence (AI) into data engineering workflows for enhanced automation and decision-making. Applications: Intelligent datacleansing, predictive data pipeline optimization, and autonomous data quality management.
Technical Data Engineer Skills 1.Python Python Python is one of the most looked upon and popular programming languages, using which data engineers can create integrations, data pipelines, integrations, automation, and datacleansing and analysis.
Datastorage is a vital aspect of any Snowflake Data Cloud database. Within Snowflake, data can either be stored locally or accessed from other cloud storage systems. Amazon S3 for AWS, Azure Blob Storage for Azure, or Google Cloud Storage for GCP) to store the actual data files in micro-partitions.
The emergence of cloud data warehouses, offering scalable and cost-effective datastorage and processing capabilities, initiated a pivotal shift in data management methodologies. Read More: Zero ETL: What’s Behind the Hype?
In 2010, a transformative concept took root in the realm of datastorage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data.
This can involve altering values, suppressing certain data points, or selectively presenting information to support a particular agenda. System or technical errors: Errors within the datastorage, retrieval, or analysis systems can introduce inaccuracies. is the gas station actually where the map says it is?).
It effectively works with Tableau Desktop and Tableau Server to allow users to publish bookmarked, cleaned-up data sources that can be accessed by other personnel within the same organization. This capability underpins sustainable, chattel datacleansing practices requisite to data governance. Excel), a cloud server (e.g.,
There are three steps involved in the deployment of a big data model: Data Ingestion: This is the first step in deploying a big data model - Data ingestion, i.e., extracting data from multiple data sources. Data Variety Hadoop stores structured, semi-structured and unstructured data.
Essentially, the fundamental principle underlying this process is to recognize data as a valuable resource, given its significant role in driving business success. Data management is a technical implementation of data governance and involves the practical aspects of working with data, such as datastorage, retrieval, and analysis.
Zero Copy Cloning: Create multiple ‘copies’ of tables, schemas, or databases without actually copying the data. This noticeably saves time on copying and drastically reduces datastorage costs.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content