This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
An important part of this journey is the datavalidation and enrichment process. Defining DataValidation and Enrichment Processes Before we explore the benefits of datavalidation and enrichment and how these processes support the data you need for powerful decision-making, let’s define each term.
Here are several reasons data quality is critical for organizations: Informed decision making: Low-quality data can result in incomplete or incorrect information, which negatively affects an organization’s decision-making process. Learn more in our detailed guide to data reliability 6 Pillars of Data Quality 1.
The data doesn’t accurately represent the real heights of the animals, so it lacks validity. Let’s dive deeper into these two crucial concepts, both essential for maintaining high-quality data. Let’s dive deeper into these two crucial concepts, both essential for maintaining high-quality data. What Is DataValidity?
These tools play a vital role in data preparation, which involves cleaning, transforming, and enriching raw data before it can be used for analysis or machine learning models. There are several types of data testing tools.
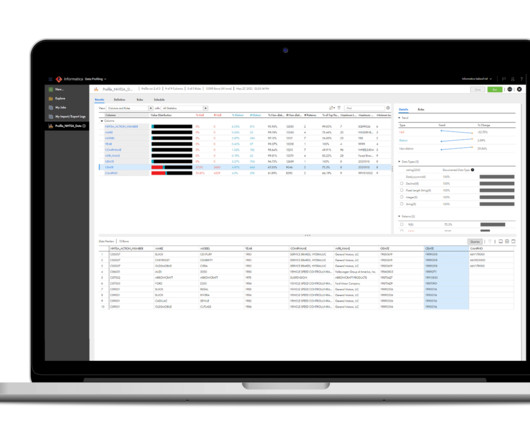
Data Profiling 2. DataCleansing 3. DataValidation 4. Data Auditing 5. Data Governance 6. Use of Data Quality Tools Refresh your intrinsic data quality with data observability 1. Data Profiling Data profiling is getting to know your data, warts and quirks and secrets and all.
Validity: Adherence to predefined formats, rules, or standards for each attribute within a dataset. Uniqueness: Ensuring that no duplicate records exist within a dataset. Integrity: Maintaining referential relationships between datasets without any broken links.
Consider exploring relevant Big Data Certification to deepen your knowledge and skills. What is Big Data? Big Data is the term used to describe extraordinarily massive and complicated datasets that are difficult to manage, handle, or analyze using conventional data processing methods.
Accurate data ensures that these decisions and strategies are based on a solid foundation, minimizing the risk of negative consequences resulting from poor data quality. There are various ways to ensure data accuracy. Datacleansing involves identifying and correcting errors, inconsistencies, and inaccuracies in data sets.
These tools play a vital role in data preparation, which involves cleaning, transforming and enriching raw data before it can be used for analysis or machine learning models. There are several types of data testing tools.
Let's dive into the top data cleaning techniques and best practices for the future – no mess, no fuss, just pure data goodness! What is Data Cleaning? It involves removing or correcting incorrect, corrupted, improperly formatted, duplicate, or incomplete data. Why Is Data Cleaning So Important?
To make sure the data is precise and suitable for analysis, data processing analysts use methods including datacleansing, imputation, and normalisation. Data integration and transformation: Before analysis, data must frequently be translated into a standard format.
This includes defining roles and responsibilities related to managing datasets and setting guidelines for metadata management. Data profiling: Regularly analyze dataset content to identify inconsistencies or errors. Automated profiling tools can quickly detect anomalies or patterns indicating potential dataset integrity issues.
Enhancing Data Quality Data ingestion plays an instrumental role in enhancing data quality. During the data ingestion process, various validations and checks can be performed to ensure the consistency and accuracy of data. Another way data ingestion enhances data quality is by enabling data transformation.
Data Profiling, also referred to as Data Archeology is the process of assessing the data values in a given dataset for uniqueness, consistency and logic. Data profiling cannot identify any incorrect or inaccurate data but can detect only business rules violations or anomalies. 5) What is datacleansing?
Photo by Markus Spiske on Unsplash Introduction Senior data engineers and data scientists are increasingly incorporating artificial intelligence (AI) and machine learning (ML) into datavalidation procedures to increase the quality, efficiency, and scalability of data transformations and conversions.
The key features of the Data Load Accelerator include: Minimal and reusable coding: The model used is configuration-based and all data load requirements will be managed with one code base. Snowflake allows the loading of both structured and semi-structured datasets from cloud storage.
When crucial information is omitted or unavailable, the analysis or conclusions drawn from the data may be flawed or misleading. Inconsistent data: Inconsistencies within a dataset can indicate inaccuracies. This can include contradictory information or data points that do not align with established patterns or trends.
Data Analysis: Perform basic data analysis and calculations using DAX functions under the guidance of senior team members. Data Integration: Assist in integrating data from multiple sources into Power BI, ensuring data consistency and accuracy. Define data architecture standards and best practices.
said Martha Crow, Senior VP of Global Testing at Lionbridge Big data is all the rage these days as various organizations dig through large datasets to enhance their operations and discover novel solutions to big data problems. We’re looking at the next evolution. a different way of business getting done."-
As per Microsoft, “A Power BI report is a multi-perspective view of a dataset, with visuals representing different findings and insights from that dataset. ” Reports and dashboards are the two vital components of the Power BI platform, which are used to analyze and visualize data. Use descriptive names.
MapReduce is a Hadoop framework used for processing large datasets. Another name for it is a programming model that enables us to process big datasets across computer clusters. This program allows for distributed data storage, simplifying complex processing and vast amounts of data. What is MapReduce in Hadoop?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content