This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here are several reasons data quality is critical for organizations: Informed decision making: Low-quality data can result in incomplete or incorrect information, which negatively affects an organization’s decision-making process. Learn more in our detailed guide to data reliability 6 Pillars of Data Quality 1.
Error prevention: all of these data validation checks above contribute to a more proactive approach that minimizes the chance of downstream errors, and in turn, the effort required for datacleansing and correction later. Streamline the Process with Precisely Let’s talk about address data.
If you want to break into the field of data engineering but don't yet have any expertise in the field, compiling a portfolio of data engineering projects may help. Data pipeline best practices should be shown in these initiatives. Source: Use Stack Overflow Data for Analytic Purposes 4.
The distance between the owner and the domain that generated the data is key to expedite further analytical development. Discoverability : A shared data platform provides a catalog of operational datasets in the form of source-aligned data products that helped me to understand the status and nature of the data exposed.
AI-driven data quality workflows deploy machine learning to automate datacleansing, detect anomalies, and validate data. Integrating AI into data workflows ensures reliable data and enables smarter business decisions. Data quality is the backbone of successful data engineering projects.
Validity: Adherence to predefined formats, rules, or standards for each attribute within a dataset. Uniqueness: Ensuring that no duplicate records exist within a dataset. Integrity: Maintaining referential relationships between datasets without any broken links.
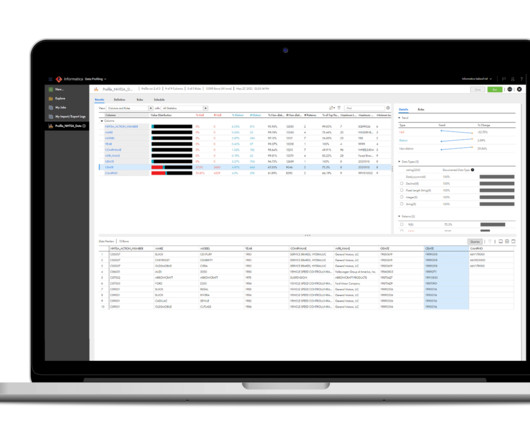
Data Profiling 2. DataCleansing 3. Data Validation 4. Data Auditing 5. Data Governance 6. Use of Data Quality Tools Refresh your intrinsic data quality with data observability 1. Data Profiling Data profiling is getting to know your data, warts and quirks and secrets and all.
Data profiling tools: Profiling plays a crucial role in understanding your dataset’s structure and content. Improved Data Quality The primary goal of using data testing tools is to enhance the overall quality of an organization’s data assets.
Spark Streaming Kafka Streams 1 Data received from live input data streams is Divided into Micro-batched for processing. processes per data stream(real real-time) 2 A separate processing Cluster is required No separate processing cluster is required. it's better for functions like row parsing, datacleansing, etc.
Consider exploring relevant Big Data Certification to deepen your knowledge and skills. What is Big Data? Big Data is the term used to describe extraordinarily massive and complicated datasets that are difficult to manage, handle, or analyze using conventional data processing methods.
As you now know the key characteristics, it gets clear that not all data can be referred to as Big Data. What is Big Data analytics? Big Data analytics is the process of finding patterns, trends, and relationships in massive datasets that can’t be discovered with traditional data management techniques and tools.
This includes defining roles and responsibilities related to managing datasets and setting guidelines for metadata management. Data profiling: Regularly analyze dataset content to identify inconsistencies or errors. Automated profiling tools can quickly detect anomalies or patterns indicating potential dataset integrity issues.
And how can a data engineer give their provider a ‘score’ on the data based on fact? The First of Five Use Cases in Data Observability Data Evaluation: This involves evaluating and cleansing new datasets before being added to production. This process is critical as it ensures data quality from the onset.
As we move firmly into the data cloud era, data leaders need metrics for the robustness and reliability of the machine–the data pipelines, systems, and engineers–just as much as the final (data) product it spits out. Pro-Tip: Data testing is often one of the data team’s biggest inefficiencies.
Let's dive into the top data cleaning techniques and best practices for the future – no mess, no fuss, just pure data goodness! What is Data Cleaning? It involves removing or correcting incorrect, corrupted, improperly formatted, duplicate, or incomplete data. Why Is Data Cleaning So Important?
In this article, we will learn different data-cleaning techniques in data science, like removing duplicates and irrelevant data, standardizing data types, fixing data format, handling missing values, etc. You can try some hands-on with online datasets to gain practical exposure.
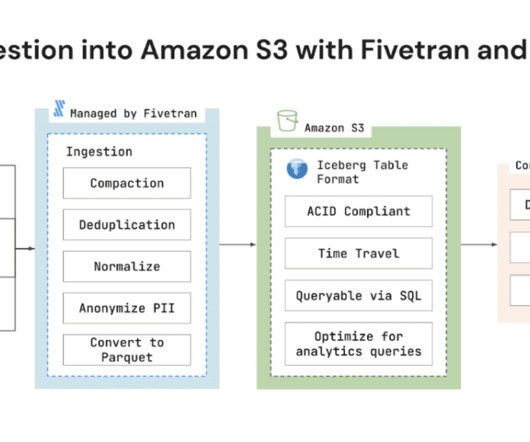
As organizations continue to leverage data lakes to run analytics and extract insights from their data, progressive marketing intelligence teams are demanding more of them, and solutions like Amazon S3 and automated pipeline support are meeting that demand.
Cleansing and enriching data due to inefficient cleansing processes, address data inconsistencies, and limited access to external datasets. While each presents its own challenges, they all make it difficult to effectively leverage data for strong, agile decision-making. How many of these resonate with you?
There are various ways to ensure data accuracy. Data validation involves checking data for errors, inconsistencies, and inaccuracies, often using predefined rules or algorithms. Datacleansing involves identifying and correcting errors, inconsistencies, and inaccuracies in data sets.
Data Profiling, also referred to as Data Archeology is the process of assessing the data values in a given dataset for uniqueness, consistency and logic. Data profiling cannot identify any incorrect or inaccurate data but can detect only business rules violations or anomalies. 5) What is datacleansing?
Data profiling tools: Profiling plays a crucial role in understanding your dataset’s structure and content. Improved data quality The primary goal of using data testing tools is to enhance the overall quality of an organization’s data assets.
We also leverage metadata from another internal tool, Genie , internal job and resource manager, to add job metadata (such as job owner, cluster, scheduler metadata) on lineage data.
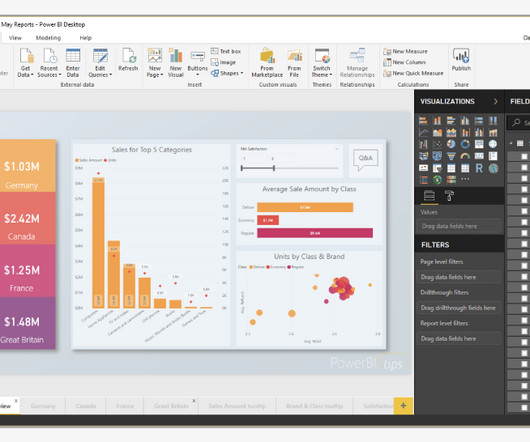
The PowerBI Site or service, PowerBI.com , is widely used to share reports, datasets, and dashboards. Data quality Microsoft Power BI does not provide any datacleansing solution. Meaning it assumes that the data you are pulling has been cleaned up well in advance, and is of high quality.
Data Processing and Cleaning : Preprocessing and data cleaning are important steps since raw data frequently has errors, duplication, missing information, and inconsistencies. To make sure the data is precise and suitable for analysis, data processing analysts use methods including datacleansing, imputation, and normalisation.
Does not offer any datacleansing solution and assumes that the data provided is of high quality. Unable to handle large data sources properly causing issues in connecting and importing large datasets, slow performance, and time-outs. What are the disadvantages of Power BI?
NiFi would capture the various datasets, do the required transformations (schema validation, format transformation, datacleansing, etc.) on each dataset and send the datasets in a data warehouse powered by Hive. Once the data is sent there, NiFi could trigger a Hive query to perform the joint operation.
It entails using various technologies, including data mining, data transformation, and datacleansing, to examine and analyze that data. Both data science and software engineering rely largely on programming skills. However, data scientists are primarily concerned with working with massive datasets.
There are several key practices and steps: Before embarking on the ETL process, it’s essential to understand the nature and quality of the source data through data profiling. Datacleansing is the process of identifying and correcting or removing inaccurate records from the dataset, improving the data quality.
Over the years, the field of data engineering has seen significant changes and paradigm shifts driven by the phenomenal growth of data and by major technological advances such as cloud computing, data lakes, distributed computing, containerization, serverless computing, machine learning, graph database, etc.
AI-driven tools can analyze large datasets in real time to detect subtle or unexpected deviations in schemachanges in field names, column counts, data types, or structural hierarchieswithout requiring extensive manual oversight. This is particularly helpful in environments where upstream data sources are subject to frequent revisions.
You need to clean your data before you begin analyzing it so that you don’t end up with false conclusions or inaccurate results. . There are two main ways to clean your data: manual and automatic. Data cleaning and data transformation are processes that help transform data from its original state into a more useful format.
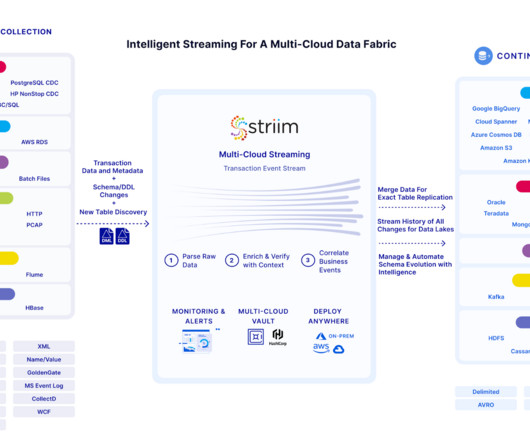
Enhanced Data Quality Striim incorporates robust data quality measures such as validation rules and datacleansing processes. By enforcing data quality standards throughout the integration pipeline, Striim ensures the integrity and accuracy of data.
Define data architecture standards and best practices. Advanced Data Modeling: Create and maintain advanced data models that support complex reporting requirements, including handling large datasets and optimizing performance. Mentor team members in data modeling techniques.
Whether it's aggregating customer interactions, analyzing historical sales trends, or processing real-time sensor data, data extraction initiates the process. What is the purpose of extracting data? The purpose of data extraction is to transform large, unwieldy datasets into a usable and actionable format.
As we move firmly into the data cloud era, data leaders need metrics for the robustness and reliability of the machine–the data pipelines, systems, and engineers–just as much as the final (data) product it spits out. Pro-Tip: Data testing is often one of the data team’s biggest inefficiencies.
Due to its strong data analysis and manipulation skills, it has significantly increased its prominence in the field of data science. Python offers a strong ecosystem for data scientists to carry out activities like datacleansing, exploration, visualization, and modeling thanks to modules like NumPy, Pandas, and Matplotlib.
The key features of the Data Load Accelerator include: Minimal and reusable coding: The model used is configuration-based and all data load requirements will be managed with one code base. Snowflake allows the loading of both structured and semi-structured datasets from cloud storage.
Enhancing Data Quality Data ingestion plays an instrumental role in enhancing data quality. During the data ingestion process, various validations and checks can be performed to ensure the consistency and accuracy of data. Another way data ingestion enhances data quality is by enabling data transformation.
Hadoop and Spark: The cavalry arrived in the form of Hadoop and Spark, revolutionizing how we process and analyze large datasets. Cloud Era: Cloud platforms like AWS and Azure took center stage, making sophisticated data solutions accessible to all.
Data modeling for AI involves making a structured framework that helps AI systems efficiently process, analyze, and understand data to make smart decisions: The 5 Funda mentals: DataCleansing and Validation : Provide data accuracy and consistency by addressing errors, missing values, and inconsistencies.
Examples of data validity include verifying that email addresses follow a standard format, ensuring that numerical data falls within a certain range, and checking that mandatory fields are filled out in a form. How Do You Maintain Data Validity? Learn more in our blog post Data Validity: 8 Clear Rules You Can Use Today.
When crucial information is omitted or unavailable, the analysis or conclusions drawn from the data may be flawed or misleading. Inconsistent data: Inconsistencies within a dataset can indicate inaccuracies. This can include contradictory information or data points that do not align with established patterns or trends.
Step 2: Extract data: The next step is to extract the data from the sources using tools such as ETL (Extract, Transform, Load) or API (Application Programming Interface). Step 5: Summarize data: The aggregated data is then summarized into meaningful metrics such as averages, sums, and count or any useful data operation.
The significance of data engineering in AI becomes evident through several key examples: Enabling Advanced AI Models with Clean Data The first step in enabling AI is the provision of high-quality, structured data. ChatGPT screenshot showing the schema of a dataset and the documentation for it.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content