This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Aspiring data scientists must familiarize themselves with the best programminglanguages in their field. ProgrammingLanguages for Data Scientists Here are the top 11 programminglanguages for data scientists, listed in no particular order: 1.
Although the titles of these jobs are frequently used interchangeably, they are separate and call for different skill sets, which results in the difference of the salaries for data engineers and data analysts. A data analyst is responsible for analyzing large data sets and extracting insights from them.
Spark Streaming Kafka Streams 1 Data received from live input data streams is Divided into Micro-batched for processing. processes per data stream(real real-time) 2 A separate processing Cluster is required No separate processing cluster is required. it's better for functions like row parsing, datacleansing, etc.
This field uses several scientific procedures to understand structured, semi-structured, and unstructured data. It entails using various technologies, including data mining, data transformation, and datacleansing, to examine and analyze that data.
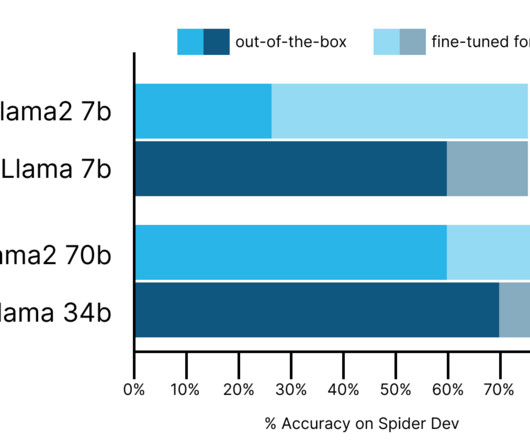
Along with the model release, Meta published Code Llama performance benchmarks on HumanEval and MBPP for common coding languages such as Python, Java, and JavaScript. SQL—the standard programminglanguage of relational databases—was not included in these benchmarks.
ETL Developer Roles and Responsibilities Below are the roles and responsibilities of an ETL developer: Extracting data from various sources such as databases, flat files, and APIs. Data Warehousing Knowledge of data cubes, dimensional modeling, and data marts is required.
Technical Data Engineer Skills 1.Python Python Python is one of the most looked upon and popular programminglanguages, using which data engineers can create integrations, data pipelines, integrations, automation, and datacleansing and analysis.
For this project, you can start with a messy dataset and use tools like Excel, Python, or OpenRefine to clean and pre-process the data. You’ll learn how to use techniques like data wrangling, datacleansing, and data transformation to prepare the data for analysis.
Improved efficiency: Data can be organized more effectively over the course of a business to isolate external variables and even reduce these variables for the business to be more efficient. . Data Manipulation Language . Data connectors or parsers can be used to connect or store heterogeneous data from diverse sources. .
Also known as data scrubbing or data cleaning, it is the process of identifying and correcting or removing inaccuracies and inconsistencies in data. Datacleansing is often necessary because data can become dirty or corrupted due to errors, duplications, or other issues. Aggregation.
The MapReduce program works in two different phases: Map and Reduce. Map tasks deal with mapping and data splitting, whereas Reduce tasks shuffle and reduce data. Hadoop can execute MapReduce applications in various languages, including Java, Ruby, Python, and C++. What is a UDF? may be used with it.
This architecture shows that simulated sensor data is ingested from MQTT to Kafka. The data in Kafka is analyzed with Spark Streaming API, and the data is stored in a column store called HBase. Finally, the data is published and visualized on a Java-based custom Dashboard. for building effective workflows.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content