This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Our data ingestion approach, in a nutshell, is classified broadly into two buckets?—?push In this model, we scan system logs and metadata generated by various compute engines to collect corresponding lineage data. push or pull. Today, we are operating using a pull-heavy model.
Data teams can create a job there to extract raw data from operational sources using JDBC connections or APIs. To avoid wasting computational work, and whenever possible, only the updated raw data since the last extraction should be incrementally added to the data product.
Finally, you should continuously monitor and update your data quality rules to ensure they remain relevant and effective in maintaining data quality. DataCleansingDatacleansing, also known as data scrubbing or data cleaning, is the process of identifying and correcting errors, inconsistencies, and inaccuracies in your data.
Data pipelines often involve a series of stages where data is collected, transformed, and stored. This might include processes like data extraction from different sources, datacleansing, data transformation (like aggregation), and loading the data into a database or a data warehouse.
This includes defining roles and responsibilities related to managing datasets and setting guidelines for metadata management. Data profiling: Regularly analyze dataset content to identify inconsistencies or errors. Datacleansing: Implement corrective measures to address identified issues and improve dataset accuracy levels.
The architecture is three layered: Database Storage: Snowflake has a mechanism to reorganize the data into its internal optimized, compressed and columnar format and stores this optimized data in cloud storage. This stage handles all the aspects of data storage like organization, file size, structure, compression, metadata, statistics.
Data Governance Examples Here are some examples of data governance in practice: Data quality control: Data governance involves implementing processes for ensuring that data is accurate, complete, and consistent. This may involve data validation, datacleansing, and data enrichment activities.
The significance of data engineering in AI becomes evident through several key examples: Enabling Advanced AI Models with Clean Data The first step in enabling AI is the provision of high-quality, structured data.
Poor data quality can lead to incorrect or misleading insights, which can have significant consequences for an organization. DataOps tools help ensure data quality by providing features like data profiling, data validation, and datacleansing.
There are several key practices and steps: Before embarking on the ETL process, it’s essential to understand the nature and quality of the source data through data profiling. Datacleansing is the process of identifying and correcting or removing inaccurate records from the dataset, improving the data quality.
In a DataOps architecture, it’s crucial to have an efficient and scalable data ingestion process that can handle data from diverse sources and formats. This requires implementing robust data integration tools and practices, such as data validation, datacleansing, and metadata management.
Instead of relying on traditional hierarchical structures and predefined schemas, as in the case of data warehouses, a data lake utilizes a flat architecture. This structure is made efficient by data engineering practices that include object storage. Watch our video explaining how data engineering works.
Integrating these principles with data operation-specific requirements creates a more agile atmosphere that supports faster development cycles while maintaining high quality standards. Organizations need to automate various aspects of their data operations, including data integration, data quality, and data analytics.
Even if the data is accurate, if it does not address the specific questions or requirements of the task, it may be of limited value or even irrelevant. Contextual understanding: Data quality is also influenced by the availability of relevant contextual information. is the gas station actually where the map says it is?).
Technical Data Engineer Skills 1.Python Python Python is one of the most looked upon and popular programming languages, using which data engineers can create integrations, data pipelines, integrations, automation, and datacleansing and analysis.
Snowflake hides user data objects and makes them accessible only through SQL queries through the compute layer. It handles the metadata related to these objects, access control configurations, and query optimization statistics. This includes tasks such as datacleansing, enrichment, and aggregation.
Also known as data scrubbing or data cleaning, it is the process of identifying and correcting or removing inaccuracies and inconsistencies in data. Datacleansing is often necessary because data can become dirty or corrupted due to errors, duplications, or other issues. Aggregation. Enrichment.
However, decentralized models may result in inconsistent and duplicate master data. There’s a centralized structure that provides a framework, which is then used by autonomous departments that own their data and metadata. Learn how data is prepared for machine learning in our dedicated video.
Why is HDFS only suitable for large data sets and not the correct tool for many small files? NameNode is often given a large space to contain metadata for large-scale files. The metadata should come from a single file for optimal space use and economic benefit. And storing these metadata in RAM will become problematic.
This project is an opportunity for data enthusiasts to engage in the information produced and used by the New York City government. Units cost per region Total revenue and cost per country Units sold by Country Revenue vs. Profit by region and sales Channel Get the downloaded data to S3 and create an EMR cluster that consists of hive service.
Data Volumes and Veracity Data volume and quality decide how fast the AI System is ready to scale. The larger the set of predictions and usage, the larger is the implications of Data in the workflow. Complex Technology Implications at Scale Onerous DataCleansing & Preparation Tasks 3.
Data Fabric is a comprehensive data management approach that goes beyond traditional methods , offering a framework for seamless integration across diverse sources. By upholding data quality, organizations can trust the information they rely on for decision-making, fostering a data-driven culture built on dependable insights.
We actually broke down that process and began to understand that the datacleansing and gathering upfront often contributed several months of cycle time to the process. Bergh added, “ DataOps is part of the data fabric. You should use DataOps principles to build and iterate and continuously improve your Data Fabric.
Transformation: Shaping Data for the Future: LLMs facilitate standardizing date formats with precision and translation of complex organizational structures into logical database designs, streamline the definition of business rules, automate datacleansing, and propose the inclusion of external data for a more complete analytical view.
This raw data from the devices needs to be enriched with content metadata and geolocation information before it can be processed and analyzed. Most analytics engines require the data to be formatted and structured in a specific schema. Our data is unstructured and sometimes incomplete and messy.
Build Data Migration: Data from the existing data warehouse is extracted to align with the schema and structure of the new target platform. This often involves data conversion, datacleansing, and other data transformation activities to help ensure data integrity and quality during the migration.
Poor data quality, on average, costs organizations $12.9 However, the more alarming insight is that 59% of organizations do not measure their data quality. The result is a broken, reactive process that fails to prevent data quality issues at their source. million annually , or 7% of their total revenue.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















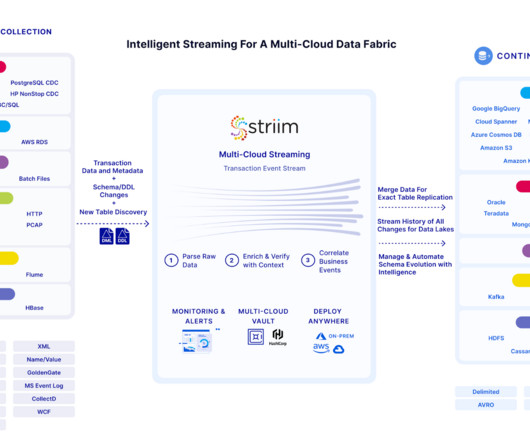











Let's personalize your content