This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
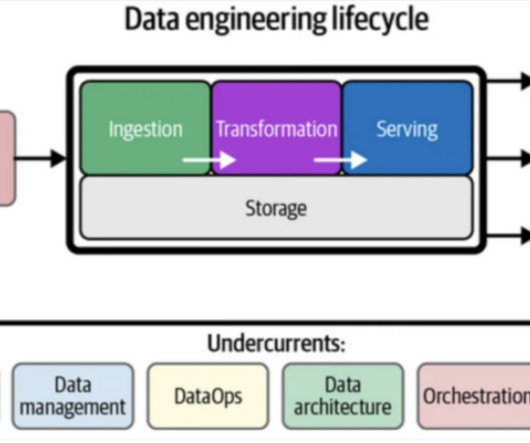
To accomplish this, ECC is leveraging the Cloudera Data Platform (CDP) to predict events and to have a top-down view of the car’s manufacturing process within its factories located across the globe. . Having completed the DataCollection step in the previous blog, ECC’s next step in the data lifecycle is Data Enrichment.
Datapipelines are the backbone of your business’s data architecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. We’ll answer the question, “What are datapipelines?” Table of Contents What are DataPipelines?
This is where real-time dataingestion comes into the picture. Data is collected from various sources such as social media feeds, website interactions, log files and processing. This refers to Real-time dataingestion. To achieve this goal, pursuing Data Engineer certification can be highly beneficial.
A well-executed datapipeline can make or break your company’s ability to leverage real-time insights and stay competitive. Thriving in today’s world requires building modern datapipelines that make moving data and extracting valuable insights quick and simple. What is a DataPipeline?
We have simplified this journey into five discrete steps with a common sixth step speaking to data security and governance. The six steps are: DataCollection – dataingestion and monitoring at the edge (whether the edge be industrial sensors or people in a brick and mortar retail store). Factory ID.
While today’s world abounds with data, gathering valuable information presents a lot of organizational and technical challenges, which we are going to address in this article. We’ll particularly explore datacollection approaches and tools for analytics and machine learning projects. What is datacollection?
In the modern world of data engineering, two concepts often find themselves in a semantic tug-of-war: datapipeline and ETL. Fast forward to the present day, and we now have datapipelines. DataIngestionDataingestion is the first step of both ETL and datapipelines.
While Cloudera Flow Management has been eagerly awaited by our Cloudera customers for use on their existing Cloudera platform clusters, Cloudera Edge Management has generated equal buzz across the industry for the possibilities that it brings to enterprises in their IoT initiatives around edge management and edge datacollection.
But let’s be honest, creating effective, robust, and reliable datapipelines, the ones that feed your company’s reporting and analytics, is no walk in the park. From building the connectors to ensuring that data lands smoothly in your reporting warehouse, each step requires a nuanced understanding and strategic approach.
This blog series follows the manufacturing and operations data lifecycle stages of an electric car manufacturer – typically experienced in large, data-driven manufacturing companies. The first blog introduced a mock vehicle manufacturing company, The Electric Car Company (ECC) and focused on DataCollection.
Datapipelines are integral to business operations, regardless of whether they are meticulously built in-house or assembled using various tools. As companies become more data-driven, the scope and complexity of datapipelines inevitably expand. Ready to fortify your data management practice?
From exploratory data analysis (EDA) and data cleansing to data modeling and visualization, the greatest data engineering projects demonstrate the whole data process from start to finish. Datapipeline best practices should be shown in these initiatives. Which queries do you have?
You are about to make structural changes to the data and want to know who and what downstream to your service will be impacted. Finally, imagine yourself in the role of a data platform reliability engineer tasked with providing advanced lead time to datapipeline (ETL) owners by proactively identifying issues upstream to their ETL jobs.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack provides datapipelines that make it easy to collectdata from every application, website, and SaaS platform, then activate it in your warehouse and business tools. Sign up free to test out the tool today.
Let us now look into the differences between AI and Data Science: Data Science vs Artificial Intelligence [Comparison Table] SI Parameters Data Science Artificial Intelligence 1 Basics Involves processes such as dataingestion, analysis, visualization, and communication of insights derived.
Data integrity issues can arise at multiple points across the datapipeline. We often refer to these issues as data freshness or stale data. For example: The source system could provide corrupt data or rows with excessive NULLs. Learn more in our blog post 9 Best Practices To Maintain Data Integrity.
This continuous adaptation ensures that your data management stays effective and compliant with current standards. The goal is to ensure your organization has the capability to process and prepare data effectively for your AI models. Your datapipeline platform should excel in collectingdata from a wide array of sources.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack provides datapipelines that make it easy to collectdata from every application, website, and SaaS platform, then activate it in your warehouse and business tools. Sign up free to test out the tool today.
Users: Who are users that will interact with your data and what's their technical proficiency? Data Sources: How different are your data sources? Latency: What is the minimum expected latency between datacollection and analytics? And what is their format?
Picture this: your data is scattered. Datapipelines originate in multiple places and terminate in various silos across your organization. Your data is inconsistent, ungoverned, inaccessible, and difficult to use. Some of the value companies can generate from data orchestration tools include: Faster time-to-insights.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack provides datapipelines that make it easy to collectdata from every application, website, and SaaS platform, then activate it in your warehouse and business tools. Sign up free to test out the tool today.
Data Sourcing: Building pipelines to source data from different company data warehouses is fundamental to the responsibilities of a data engineer. So, work on projects that guide you on how to build end-to-end ETL/ELT datapipelines. Google BigQuery receives the structured data from workers.
One was to create another datapipeline that would aggregate data as it was ingested into DynamoDB. All in all, trying to make DynamoDB support fast analytics was a nightmare that would not end. And with the NFL season set to start in less than a month, we were in a bind.
Knowledge of the definition and architecture of AWS Big Data services and their function in the data engineering lifecycle, including datacollection and ingestion, data analytics, data storage, data warehousing, data processing, and data visualization.
DataPipelines Snowpipe Streaming – public preview While data generated in real time is valuable, it is more valuable when paired with historical data that helps provide context. The company’s data is highly accurate, which makes deriving insights easy and decision-making truly fact based.
Today’s modern approach to data governance is incredibly complex, with governance teams needing to oversee increasing volumes of dataingested from diverse sources, dispersed storage across cloud-based infrastructures, and an appetite for democratized access across the organization.
Data must be consumed from many sources, translated and stored, and then processed before being presented understandably. However, the benefits might be game-changing: a well-designed big datapipeline can significantly differentiate a company. Dataingestion can be divided into two categories: .
The role of a data engineer is going to vary depending on the particular needs of your organization. It’s the role of a data engineer to store, extract, transform, load, aggregate, and validate data. This involves: Building datapipelines and efficiently storing data for tools that need to query the data.
Big Data analytics encompasses the processes of collecting, processing, filtering/cleansing, and analyzing extensive datasets so that organizations can use them to develop, grow, and produce better products. Big Data analytics processes and tools. Dataingestion. Let’s take a closer look at these procedures.
This article will define in simple terms what a data warehouse is, how it’s different from a database, fundamentals of how they work, and an overview of today’s most popular data warehouses. What is a data warehouse? Finally, where and how the datapipeline broke isn’t always obvious. They need to be transformed.
There are three steps involved in the deployment of a big data model: DataIngestion: This is the first step in deploying a big data model - Dataingestion, i.e., extracting data from multiple data sources. Steps for Data preparation. How can AWS solve Big Data Challenges?
PySpark is a handy tool for data scientists since it makes the process of converting prototype models into production-ready model workflows much more effortless. Another reason to use PySpark is that it has the benefit of being able to scale to far more giant data sets compared to the Python Pandas library.
Moreover, Spark SQL makes it possible to combine streaming data with a wide range of static data sources. For example, Amazon Redshift can load static data to Spark and process it before sending it to downstream systems. Streaming, batch, and interactive processing pipelines can share and reuse code and business logic.
Overview of the Customer 360 App Our app will make use of real-time data on customer orders and events. We’ll use Rockset to get data from different sources and run analytical queries that power our app in Retool. For our example, DynamoDB will store customers’ orders, and we will get the customer_events stream through Amazon Kinesis.
Additionally, some systems utilize pre-computed lists, such as those generated by datapipelines that identify the top 100 most popular content pieces globally, serving as another form of candidate generator. Moreover, the system is latency-bound, often needing to process these millions of data points within tens of milliseconds.
The fast development of digital technologies, IoT goods and connectivity platforms, social networking apps, video, audio, and geolocation services has created the potential for massive amounts of data to be collected/accumulated. In this post, we’ll explain each Big Data component along with the Big Data ecosystem.
Below is a list of Big Data project ideas and an idea of the approach you could take to develop them; hoping that this could help you learn more about Big Data and even kick-start a career in Big Data. Organizations constantly run their operations so that every department has its data.
Having multiple data integration routes helps optimize the operational as well as analytical use of data. Experimentation in production Big DataData Warehouse for core ETL tasks Direct datapipelines Tiered Data Lake 4. Data: Data Engineering PipelinesData is everything.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content