This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Understanding Bias in AI Bias in AI arises when the data used to train machine learning models reflects historical inequalities, stereotypes, or inaccuracies. This bias can be introduced at various stages of the AI development process, from datacollection to algorithm design, and it can have far-reaching consequences.
Raw data, however, is frequently disorganised, unstructured, and challenging to work with directly. Dataprocessing analysts can be useful in this situation. Let’s take a deep dive into the subject and look at what we’re about to study in this blog: Table of Contents What Is DataProcessing Analysis?
There are two main dataprocessing paradigms: batch processing and stream processing. Batch processing: data is typically extracted from databases at the end of the day, saved to disk for transformation, and then loaded in batch to a data warehouse. Stream processing is (near) real-time processing.
However, this leveraging of information will not be effective unless the organization can preserve the integrity of the underlying data over its lifetime. Integrity is a critical aspect of dataprocessing; if the integrity of the data is unknown, the trustworthiness of the information it contains is unknown.
As the hyper-automation trend accelerates, supporting citizen developers who can drive process automation across the entire organization is key. DataIntegrity Today’s innovators take proactive steps to improve the quality and integrity of their most important data. We call these strategic dataprocesses.
The datacollected feeds into a comprehensive quality dashboard and supports a tiered threshold-based alerting system. The Flink jobs sink is equipped with a data mesh connector, as detailed in our Data Mesh platform which has two outputs: Kafka and Iceberg.
new Intercom Reader makes it even easier by enabling seamless real-time dataintegration from the Intercom platform into your analytics systems. It captures the necessary data and emits WAEvents, which can be propagated to any supported target systems , such as Google BigQuery, Snowflake, or Microsoft Azure Synapse. Striim 5.0s
While Cloudera Flow Management has been eagerly awaited by our Cloudera customers for use on their existing Cloudera platform clusters, Cloudera Edge Management has generated equal buzz across the industry for the possibilities that it brings to enterprises in their IoT initiatives around edge management and edge datacollection.
Data Lake A data lake would serve as a repository for raw and unstructured data generated from various sources within the Formula 1 ecosystem: telemetry data from the cars (e.g. Data Lake & DataIntegration We’ll face our first challenge while we integrate and consolidate everything in a single place.
Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making. These data sources serve as the starting point for the pipeline, providing the raw data that will be ingested, processed, and analyzed.
Explosion of data availability from a variety of sources, including on-premises data stores used by enterprise data warehousing / data lake platforms, data on cloud object stores typically produced by heterogenous, cloud-only processing technologies, or data produced by SaaS applications that have now evolved into distinct platform ecosystems (e.g.,
Organizations deal with datacollected from multiple sources, which increases the complexity of managing and processing it. Oracle offers a suite of tools that helps you store and manage the data, and Apache Spark enables you to handle large-scale dataprocessing tasks.
While all these solutions help data scientists, data engineers and production engineers to work better together, there are underlying challenges within the hidden debts: Datacollection (i.e., integration) and preprocessing need to run at scale. Apache Kafka and KSQL for data scientists and data engineers.
What is Big Data? Big Data is the term used to describe extraordinarily massive and complicated datasets that are difficult to manage, handle, or analyze using conventional dataprocessing methods. The real-time or near-real-time nature of Big Data poses challenges in capturing and processingdata rapidly.
While legacy ETL has a slow transformation step, modern ETL platforms, like Striim, have evolved to replace disk-based processing with in-memory processing. This advancement allows for real-time data transformation , enrichment, and analysis, providing faster and more efficient dataprocessing.
The emergence of cloud data warehouses, offering scalable and cost-effective data storage and processing capabilities, initiated a pivotal shift in data management methodologies. This approach ensures that only processed and refined data is housed in the data warehouse, leaving the raw data outside of it.
Audio data transformation basics to know. Before diving deeper into processing of audio files, we need to introduce specific terms, that you will encounter at almost every step of our journey from sound datacollection to getting ML predictions. One of the largest audio datacollections is AudioSet by Google.
Here’s the process. DataCollection and Integration: Data is gathered from various sources, including sensor and IoT data, transportation management systems, transactional systems, and external data sources such as economic indicators or traffic data.
Use Cases of Real-time Ingestion Real-time ingestion provides organizations with infrastructure for implementing various data capture, dataprocessing and data analyzing tools. Here are some key uses of real-time data ingestion: 1. This process requires dataintegration tools and APIs for seamless connections.
In a world where organizations rely heavily on data observability for informed decision-making, effective data testing methods are crucial to ensure high-quality standards across all stages of the data lifecycle—from datacollection and storage to processing and analysis.
Our Solution: Custom Build Analytics To address the challenges and limitations in our build management process, we developed a multi-step Build Analytics solution using ThoughtSpot as the central platform. Step 3: Implementing a data pipeline To automate the datacollection and processing, we integrated a Jenkins job that runs hourly.
The data source is the location of the data that the processing will consume for dataprocessing functions. This can be the point of origin of the data, the place of its creation. Alternatively, this can be data generated by another process and then made available for subsequent processing.
However, having a lot of data is useless if businesses can't use it to make informed, data-driven decisions by analyzing it to extract useful insights. Business intelligence (BI) is becoming more important as a result of the growing need to use data to further organizational objectives.
Data Engineer roles and responsibilities have certain important components, such as: Refining the software development process using industry standards. Identifying and fixing data security flaws to shield the company from intrusions. Employing dataintegration technologies to get data from a single domain.
AI enhances predictive maintenance in several ways: Data Analysis: In real-time modes, AI processes large volumes of information while detecting any patterns or anomalies that could indicate an impending failure ahead of traditional monitoring systems. AI algorithms can be used to access this data to start its analysis.
Big Data vs Small Data: Volume Big Data refers to large volumes of data, typically in the order of terabytes or petabytes. It involves processing and analyzing massive datasets that cannot be managed with traditional dataprocessing techniques. What Should You Choose Between Big Data and Small Data?
Users: Who are users that will interact with your data and what's their technical proficiency? Data Sources: How different are your data sources? Latency: What is the minimum expected latency between datacollection and analytics? And what is their format?
Blockchain data-based cloud dataintegrity protection mechanism The "Blockchain data-based cloud dataintegrity protection mechanism" paper suggests a method for safeguarding the integrity of cloud data and which is one of the Cloud computing research topics.
Big Data analytics processes and tools. Data ingestion. The process of identifying the sources and then getting Big Data varies from company to company. It’s worth noting though that datacollection commonly happens in real-time or near real-time to ensure immediate processing.
From blockchain-based database systems to real-time dataprocessing with in-memory databases, these topics offer a glimpse into the exciting future of database research. Once data has been added to such a database, it cannot be modified or deleted. Relational databases, with their inherent structure, aid in this process.
Without a fixed schema, the data can vary in structure and organization. File systems, data lakes, and Big Dataprocessing frameworks like Hadoop and Spark are often utilized for managing and analyzing unstructured data. The process requires extracting data from diverse sources, typically via APIs.
Sample of a high-level data architecture blueprint for Azure BI programs. Source: Pragmatic Works This specialist also oversees the deployment of the proposed framework as well as data migration and dataintegrationprocesses. In some locations, this certification can be acquired online.
Integration with Spark: When paired with platforms like Spark, Python’s performance is further amplified. PySpark, for instance, optimizes distributed data operations across clusters, ensuring faster dataprocessing. getOrCreate() data = spark.read.csv("big_data.csv") data.groupBy("category").count().show()
Who Uses Real-time Data Analytics? Many industries and businesses utilize real-time data analytics to get insights and make decisions based on datacollected in real time. Rapid ongoing dataprocessing can be necessary for real-time data analytics.
Big data tools are used to perform predictive modeling, statistical algorithms and even what-if analyses. Some important big dataprocessing platforms are: Microsoft Azure. Why Is Big Data Analytics Important? Let's check some of the best big data analytics tools and free big data analytics tools.
Transforming Data Complexity into Strategic Insight At first glance, the process of transforming raw data into actionable insights can seem daunting. The journey from datacollection to insight generation often feels like operating a complex machine shrouded in mystery and uncertainty.
Now, you might ask, “How is this different from data stack architecture, or data architecture?” ” Data Stack Architecture : Your data stack architecture defines the technology and tools used to handle data, like databases, dataprocessing platforms, analytic tools, and programming languages.
Business Intelligence: Business Intelligence can handle moderate to large volumes of structured data. While it may not be designed specifically for big dataprocessing, it can integrate with dataprocessing technologies to analyze substantial amounts of data.
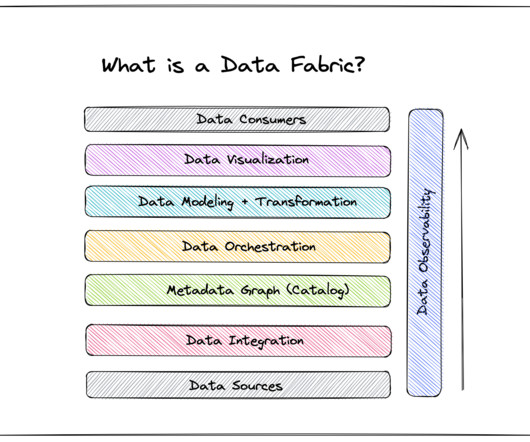
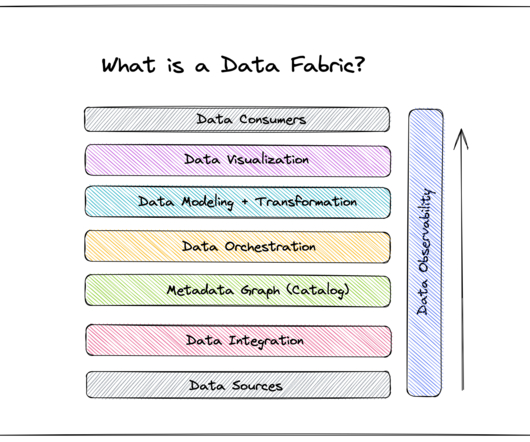
Reduced reliance on IT Integral to a data fabric is a set of pre-built models and algorithms that expedite dataprocessing. Ducati’s advantage lies in the volumes of valuable performance data that help drive innovation. And this innovation ultimately creates bikes that the competition can only dream of.”
Reduced reliance on IT Integral to a data fabric is a set of pre-built models and algorithms that expedite dataprocessing. Ducati’s advantage lies in the volumes of valuable performance data that help drive innovation. And this innovation ultimately creates bikes that the competition can only dream of.”
Actions: Establish connections to your data sources like CRM systems or social media platforms. Implement processes to validate and clean incoming data, such as verifying data formats or removing duplicates 3. Objective: Refine the data through specific transformations to make it suitable for analysis.
Learning Outcomes: You will understand the processes and technology necessary to operate large data warehouses. Engineering and problem-solving abilities based on Big Data solutions may also be taught. Additionally, you will learn how to design and manage dataprocessing systems.
This process involves datacollection from multiple sources, such as social networking sites, corporate software, and log files. Data Storage: The next step after data ingestion is to store it in HDFS or a NoSQL database such as HBase. DataProcessing: This is the final step in deploying a big data model.
Kafka is extensively being used across industries for general – purpose messaging system where high availability and real time dataintegration and analytics are of utmost importance.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content