This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While today’s world abounds with data, gathering valuable information presents a lot of organizational and technical challenges, which we are going to address in this article. We’ll particularly explore datacollection approaches and tools for analytics and machine learning projects. What is datacollection?
Integrity is a critical aspect of data processing; if the integrity of the data is unknown, the trustworthiness of the information it contains is unknown. What is DataIntegrity? Dataintegrity is the accuracy and consistency over the lifetime of the content and format of a data item.
Data quality refers to the degree of accuracy, consistency, completeness, reliability, and relevance of the datacollected, stored, and used within an organization or a specific context. High-quality data is essential for making well-informed decisions, performing accurate analyses, and developing effective strategies.
Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making. These data sources serve as the starting point for the pipeline, providing the raw data that will be ingested, processed, and analyzed.
Few benefits of Cloud computing are listed below: Scalability: With Cloud computing we get scalable applications which suits for large scale production systems for Businesses which store and process large sets of data. Create a dataintegrity protection system based on blockchain that is compatible with current cloud computing platforms.
It is meant for you to assess if you have thought through processes such as continuous data ingestion, enterprise dataintegration and data governance. Data infrastructure readiness – IoT architectures can be insanely complex and sophisticated.
However, Big Data encompasses unstructured data, including text documents, images, videos, social media feeds, and sensor data. Handling this variety of data requires flexible datastorage and processing methods. Veracity: Veracity in big data means the quality, accuracy, and reliability of data.
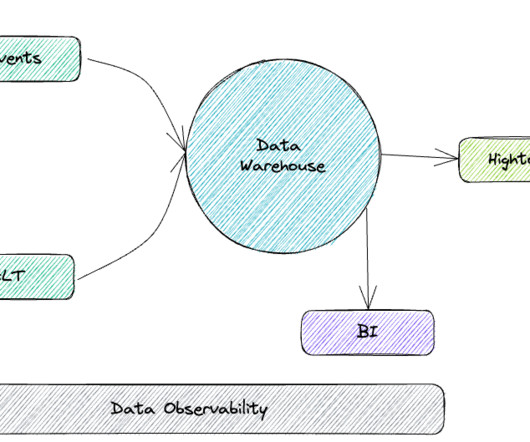
The emergence of cloud data warehouses, offering scalable and cost-effective datastorage and processing capabilities, initiated a pivotal shift in data management methodologies. This approach ensures that only processed and refined data is housed in the data warehouse, leaving the raw data outside of it.
Data Engineer roles and responsibilities have certain important components, such as: Refining the software development process using industry standards. Identifying and fixing data security flaws to shield the company from intrusions. Employing dataintegration technologies to get data from a single domain.
A data hub is a central mediation point between various data sources and data consumers. It’s not a single technology, but rather an architectural approach that unites storages, dataintegration and orchestration tools. An ETL approach in the DW is considered slow, as it ships data in portions (batches.)
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. Big Data analytics processes and tools. Data ingestion.
What does a Data Processing Analysts do ? A data processing analyst’s job description includes a variety of duties that are essential to efficient data management. They must be well-versed in both the data sources and the data extraction procedures.
Skills along the lines of Data Mining, Data Warehousing, Math and statistics, and Data Visualization tools that enable storytelling. This data can be of any type, i.e., structured or unstructured, which also includes images, videos and social media, and more.
Here are some examples of how Python can be applied to various facets of data engineering: DataCollection Web scraping has become an accessible task thanks to Python libraries like Beautiful Soup and Scrapy, empowering engineers to easily gather data from web pages.
”- Henry Morris, senior VP with IDC SAP is considering Apache Hadoop as large scale datastorage container for the Internet of Things (IoT) deployments and all other application deployments where datacollection and processing requirements are distributed geographically.
Tools and platforms for unstructured data management Unstructured datacollection Unstructured datacollection presents unique challenges due to the information’s sheer volume, variety, and complexity. The process requires extracting data from diverse sources, typically via APIs.
The infrastructure for real-time data ingestion typically consists of several key features: Data Sources: These are the Systems, devices, and applications which create vast amounts of data in real-time. Like IoT devices, sensors, social media platforms, financial data, etc.
In other words, is it likely your data is accurate based on your expectations? Datacollection methods: Understand the methodology used to collect the data. Look for potential biases, flaws, or limitations in the datacollection process. is the gas station actually where the map says it is?).
Once data has been added to such a database, it cannot be modified or deleted. This is particularly useful in situations where dataintegrity is critical, such as in financial transactions or supply chain management. DataStorage and Retrieval: Spatio-temporal data tends to be very high-volume.
For example, service agreements may cover data quality, latency, and availability, but they are outside the organization's control. Primary Data Sources are those where datacollection is from its point of creation before any processing.
Small Data is well-suited for focused decision-making, where specific insights drive actions. Big Data vs Small Data: Storage and Cost Big Data: Managing and storing Big Data requires specialized storage systems capable of handling large volumes of data.
There are three steps involved in the deployment of a big data model: Data Ingestion: This is the first step in deploying a big data model - Data ingestion, i.e., extracting data from multiple data sources. Data Variety Hadoop stores structured, semi-structured and unstructured data.
Big Data Engineers are professionals who handle large volumes of structured and unstructured data effectively. They are responsible for changing the design, development, and management of data pipelines while also managing the data sources for effective datacollection.
Set up your pipeline orchestration, including scheduling the data flows, defining dependencies, and establishing protocols for handling failed jobs. Security management is difficult and datacollection needs to be idempotent. Adapting to Change: In the world of data, change is the only constant.
Although it's open source, it only supports 10000 data rows and one logical processor. ML models can be deployed to the web or mobile (only when the user interface is ready for real-time datacollection) with the assistance of Rapid Miner. is an all-in-one solution for businesses to connect their data and applications.
Core components of a Hadoop application are- 1) Hadoop Common 2) HDFS 3) Hadoop MapReduce 4) YARN Data Access Components are - Pig and Hive DataStorage Component is - HBase DataIntegration Components are - Apache Flume, Sqoop, Chukwa Data Management and Monitoring Components are - Ambari, Oozie and Zookeeper.
While these bundled solutions quickly rose in popularity for marketing organizations over the past decade, questions lingered in their supporting data teams’ minds as to whether these were actually the right solution for collecting and activating customer data.
Artificial Intelligence is transforming the business environment, enabling organizations to rethink how they analyze data, integrate information, and use insights to improve decision-making. It can also be connected with Azure Bot Services to extract information from datacollected via the bot interface.
For such scenarios, data-driven integration becomes less comfortable, so you must prefer event-based dataintegration. This project will teach you how to design and implement an event-based dataintegration pipeline on the Google Cloud Platform by processing data using DataFlow.
It’s like building your own data Avengers team, with each component bringing its own superpowers to the table. Here’s how a composable CDP might incorporate the modeling approaches we’ve discussed: DataStorage and Processing : This is your foundation. Launched a new loyalty program? Those days are gone!
Flat Files: CSV, TXT, and Excel spreadsheets are standard text file formats for storing data. Nontechnical users can easily access these data formats without installing data science software. SQL RDBMS: The SQL database is a trendy datastorage where we can load our processed data.
Data lineage is what’s in your database – which is not everything. Data lineage primarily focuses on tracking the movement and transformation of data within the database or datastorage systems. Data lineage does not directly improve data quality. They measure data sets at a point in time.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content