

DataOps vs. DevOps-Key Differences Data Engineers Must Know
ProjectPro
JUNE 6, 2025
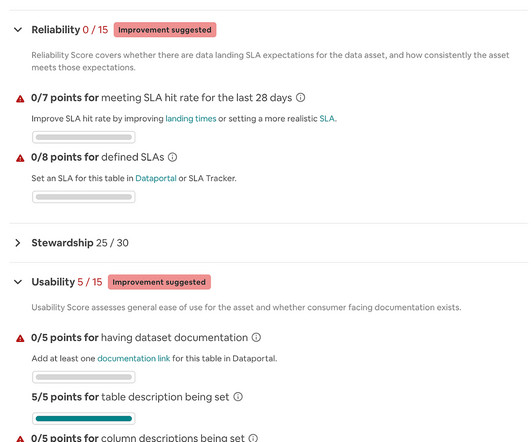
It is a set of concepts you can apply to instances where data is present. Continuous data delivery through data collection, curation, integration, and modeling automation. Data curation, data governance, and other processes are all automated.




























Let's personalize your content