This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While today’s world abounds with data, gathering valuable information presents a lot of organizational and technical challenges, which we are going to address in this article. We’ll particularly explore datacollection approaches and tools for analytics and machine learning projects. What is datacollection?
The focus has also been hugely centred on compute rather than datastorage and analysis. In reality, enterprises need their data and compute to occur in multiple locations, and to be used across multiple time frames — from real time closed-loop actions, to analysis of long-term archived data.
[link] Sneha Ghantasala: Slow Reads for S3 Files in Pandas & How to Optimize it DeepSeek’s Fire-Flyer File System (3FS) re-triggers the importance of an optimized file system for efficient data processing.
For more information, check out the best Data Science certification. A data scientist’s job description focuses on the following – Automating the collection process and identifying the valuable data. To pursue a career in BI development, one must have a strong understanding of data mining, data warehouse design, and SQL.
The goal is to define, implement and offer a data lifecycle platform enabling and optimizing future connected and autonomous vehicle systems that would train connected vehicle AI/ML models faster with higher accuracy and delivering a lower cost.
Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making. These data sources serve as the starting point for the pipeline, providing the raw data that will be ingested, processed, and analyzed.
Data quality refers to the degree of accuracy, consistency, completeness, reliability, and relevance of the datacollected, stored, and used within an organization or a specific context. High-quality data is essential for making well-informed decisions, performing accurate analyses, and developing effective strategies.
This is especially crucial to state and local government IT teams, who must balance their vital missions against resource constraints, compliance requirements, cybersecurity risks, and ever-increasing volumes of data. Hybrid cloud delivers that “best-of-both” approach, which is why it has become the de facto model for state and local CIOs.
Full-stack data science is a method of ensuring the end-to-end application of this technology in the real world. For an organization, full-stack data science merges the concept of data mining with decision-making, datastorage, and revenue generation.
A database is a structured datacollection that is stored and accessed electronically. File systems can store small datasets, while computer clusters or cloud storage keeps larger datasets. According to a database model, the organization of data is known as database design.
This ensures the reliability and accuracy of data-driven decision-making processes. Key components of an observability pipeline include: Datacollection: Acquiring relevant information from various stages of your data pipelines using monitoring agents or instrumentation libraries.
For example, banks may need data from external sources like Bloomberg to supplement trading data they already have on hand — and these external sources will likely not conform to the same data structures as the internal data. Expanded requirements for a centralized and secure single view of risk data. .
The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. The framework provides a way to divide a huge datacollection into smaller chunks and shove them across interconnected computers or nodes that make up a Hadoop cluster. Datastorage options.
Using Data Analytics to Learn abilities: The AWS Data Analytics certification is a great way to learn crucial data analysis abilities. It covers data gathering, cloud computing, datastorage, processing, analysis, visualization, and data security.
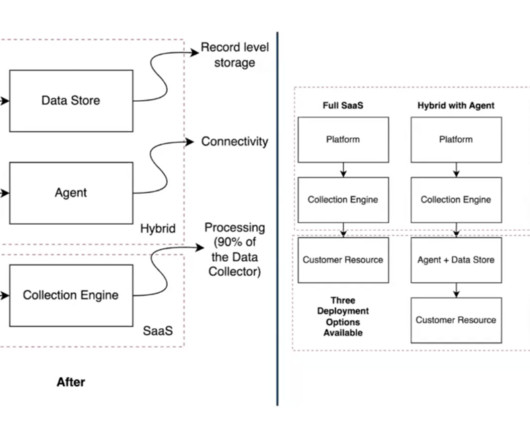
It consisted of three core components: Data connection: the connectivity to resources like Redshift, Snowflake, BigQuery, Databricks and many more (e.g., Datastorage: any record-level or troubleshooting data (e.g., for data sampling) Data processing: the extraction and transformation collection engine (e.g.,
In 2023, Business Intelligence (BI) is a rapidly evolving field focusing on datacollection, analysis, and interpretation to enhance decision-making in organizations. Careful consideration of research methodology, datacollection methods, and analysis techniques helps in ensuring the validity and reliability of your findings.
Few benefits of Cloud computing are listed below: Scalability: With Cloud computing we get scalable applications which suits for large scale production systems for Businesses which store and process large sets of data. They discussed the pros of real-time datacollection, improved care coordination, automated diagnosis and treatment.
We chose Mantis as our backbone to transport and process large volumes of trace data because we needed a backpressure-aware, scalable stream processing system. Our trace datacollection agent transports traces to Mantis job cluster via the Mantis Publish library.
Data infrastructure readiness – IoT architectures can be insanely complex and sophisticated. Topics like datastorage need to be well thought out before embarking on an IoT initiative. Will you be needing local edge storage? Will your data be stored on-premises, on the cloud or in a hybrid architecture?
From analysts to Big Data Engineers, everyone in the field of data science has been discussing data engineering. When constructing a data engineering project, you should prioritize the following areas: Multiple sources of data (APIs, websites, CSVs, JSON, etc.) Which queries do you have?
The integration of data from separate sources becomes a self-consistent data set with the removal of duplications and flagging of inconsistencies or, if possible, their resolution. Datastorage uses a non-volatile environment with strict management controls on the modification and deletion of data.
Tools and platforms for unstructured data management Unstructured datacollection Unstructured datacollection presents unique challenges due to the information’s sheer volume, variety, and complexity. The process requires extracting data from diverse sources, typically via APIs.
”- Henry Morris, senior VP with IDC SAP is considering Apache Hadoop as large scale datastorage container for the Internet of Things (IoT) deployments and all other application deployments where datacollection and processing requirements are distributed geographically.
Preparing the data for use in the model is paramount to the benefits of machine learning predictions , so let’s review what steps to take to ensure you’re getting the most out of your model. It may hurt it by adding in irrelevant, noisy data.
Skills along the lines of Data Mining, Data Warehousing, Math and statistics, and Data Visualization tools that enable storytelling. This data can be of any type, i.e., structured or unstructured, which also includes images, videos and social media, and more.
Azure Storage As the name suggests, Azure storage deals with datastorage solutions on the Microsoft cloud. It is highly secure and scalable and can be used to store a variety of data objects. They can also use Azure CLI or Azure PowerShell for configuring tasks and data management.
With CDW, as an integrated service of CDP, your line of business gets immediate resources needed for faster application launches and expedited data access, all while protecting the company’s multi-year investment in centralized data management, security, and governance.
In this section, we will explore how database technology is being used to analyze spatio-temporal data, and the benefits this research offers. DataStorage and Retrieval: Spatio-temporal data tends to be very high-volume. Interviews: This is one of the most common methods of datacollection in qualitative research.
On the other hand, data observability provides visibility into your data system and helps you determine what exactly happened, what changes occurred, who made them, and more. It combines artificial intelligence, machine learning, and DevOps best practices to create systems to improve monitoring and debug the datacollected.
link] Meta: Tulip - Schematizing Meta’s data platform Numerous heterogeneous services make up a data platform, such as warehouse datastorage and various real-time systems. The schematization of data plays a vital role in a data platform. The author shares the experience of one such transition.
Data Scientist: A Data Scientist studies data in depth to automate the datacollection and analysis process and thereby find trends or patterns that are useful for further actions. Data Analysts: With the growing scope of data and its utility in economics and research, the role of data analysts has risen.
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. Big Data analytics processes and tools. Data ingestion.
As a Data Engineer, you must: Work with the uninterrupted flow of data between your server and your application. Work closely with software engineers and data scientists. DataStorage Specialists A data engineer needs to specialize in datastorage, database management, and working on data warehouses (both cloud and on-premises).
Because of this, all businesses—from global leaders like Apple to sole proprietorships—need Data Engineers proficient in SQL. NoSQL – This alternative kind of datastorage and processing is gaining popularity. They’ll come up during your quest for a Data Engineer job, so using them effectively will be quite helpful.
According to the World Economic Forum, the amount of data generated per day will reach 463 exabytes (1 exabyte = 10 9 gigabytes) globally by the year 2025. They collect and extract data from warehouses using querying techniques, analyze this data and create summary reports of the company's current standings.
Here are some examples of how Python can be applied to various facets of data engineering: DataCollection Web scraping has become an accessible task thanks to Python libraries like Beautiful Soup and Scrapy, empowering engineers to easily gather data from web pages.
However, Big Data encompasses unstructured data, including text documents, images, videos, social media feeds, and sensor data. Handling this variety of data requires flexible datastorage and processing methods. Veracity: Veracity in big data means the quality, accuracy, and reliability of data.
The components of a Composable CDP can be broken down as follows: DataCollection : For batch data sources like SaaS applications and on-prem systems, Fivetran is the standard. The ELT platform offers 200+ pre-built connections to centralize data to any data platform.
There are three steps involved in the deployment of a big data model: Data Ingestion: This is the first step in deploying a big data model - Data ingestion, i.e., extracting data from multiple data sources. Data Variety Hadoop stores structured, semi-structured and unstructured data.
What does a Data Processing Analysts do ? A data processing analyst’s job description includes a variety of duties that are essential to efficient data management. They must be well-versed in both the data sources and the data extraction procedures.
Small Data is well-suited for focused decision-making, where specific insights drive actions. Big Data vs Small Data: Storage and Cost Big Data: Managing and storing Big Data requires specialized storage systems capable of handling large volumes of data.
PROCs can be used to evaluate data in a SAS datacollection, generate formatted reports or other outputs, or provide methods for managing SAS files. PROCs can also do things like present information about SAS datacollection. This helps in preventing incorrect data from being saved in a SAS datacollection.
For example, service agreements may cover data quality, latency, and availability, but they are outside the organization's control. Primary Data Sources are those where datacollection is from its point of creation before any processing.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content