This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For more information, check out the best Data Science certification. A data scientist’s job description focuses on the following – Automating the collection process and identifying the valuable data. To pursue a career in BI development, one must have a strong understanding of data mining, data warehouse design, and SQL.
Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making. These data sources serve as the starting point for the pipeline, providing the raw data that will be ingested, processed, and analyzed.
Best website for data visualization learning: geeksforgeeks.org Start learning Inferential Statistics and Hypothesis Testing Exploratory data analysis helps you to know patterns and trends in the data using many methods and approaches. In data analysis, EDA performs an important role.
Data quality refers to the degree of accuracy, consistency, completeness, reliability, and relevance of the datacollected, stored, and used within an organization or a specific context. High-quality data is essential for making well-informed decisions, performing accurate analyses, and developing effective strategies.
This ensures the reliability and accuracy of data-driven decision-making processes. Key components of an observability pipeline include: Datacollection: Acquiring relevant information from various stages of your data pipelines using monitoring agents or instrumentation libraries.
With CDW, as an integrated service of CDP, your line of business gets immediate resources needed for faster application launches and expedited data access, all while protecting the company’s multi-year investment in centralized data management, security, and governance. One IT-step away from a life outside the shadows.
From a data management point of view, FRTB’s requirements will require greatly increased quantities of historical data, along with an increased need for analysis and intensive computation against this data. . And there will be expansions on the requirements for managing and monitoring both data lineage and data security.
The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. The framework provides a way to divide a huge datacollection into smaller chunks and shove them across interconnected computers or nodes that make up a Hadoop cluster. Datastorage options.
Fingerprint Technology-Based ATM This project aims to enhance the security of ATM transactions by utilizing fingerprint recognition for user authentication. Top Software Engineer Project Ideas for Beginners 1. cvtColor(image, cv2.COLOR_BGR2GRAY) COLOR_BGR2GRAY) _, thresh = cv2.threshold(gray_image, threshold(gray_image, 127, 255, cv2.THRESH_BINARY)
Identifying and fixing data security flaws to shield the company from intrusions. Employing data integration technologies to get data from a single domain. Data is utilized in all facets of sales and results in life cycle analysis. To create autonomous data streams, Data Engineering teams use AWS.
Without a fixed schema, the data can vary in structure and organization. File systems, data lakes, and Big Data processing frameworks like Hadoop and Spark are often utilized for managing and analyzing unstructured data. The process requires extracting data from diverse sources, typically via APIs.
Using Data Analytics to Learn abilities: The AWS Data Analytics certification is a great way to learn crucial data analysis abilities. It covers data gathering, cloud computing, datastorage, processing, analysis, visualization, and data security.
This flexibility allows tracer libraries to record 100% traces in our mission-critical streaming microservices while collecting minimal traces from auxiliary systems like offline batch data processing. Our engineering teams tuned their services for performance after factoring in increased resource utilization due to tracing.
In 2023, Business Intelligence (BI) is a rapidly evolving field focusing on datacollection, analysis, and interpretation to enhance decision-making in organizations. Utilizing this information enables the customization of marketing campaigns, enhancement of customer experiences, and optimization of product offerings.
4 Purpose Utilize the derived findings and insights to make informed decisions The purpose of AI is to provide software capable enough to reason on the input provided and explain the output 5 Types of Data Different types of data can be used as input for the Data Science lifecycle.
From analysts to Big Data Engineers, everyone in the field of data science has been discussing data engineering. When constructing a data engineering project, you should prioritize the following areas: Multiple sources of data (APIs, websites, CSVs, JSON, etc.) Which queries do you have?
Few benefits of Cloud computing are listed below: Scalability: With Cloud computing we get scalable applications which suits for large scale production systems for Businesses which store and process large sets of data. They discussed the pros of real-time datacollection, improved care coordination, automated diagnosis and treatment.
Data Scientist: A Data Scientist studies data in depth to automate the datacollection and analysis process and thereby find trends or patterns that are useful for further actions. Also, experience is required in software development, data processes, and cloud platforms. . is highly beneficial.
Small Data is well-suited for focused decision-making, where specific insights drive actions. Big Data vs Small Data: Storage and Cost Big Data: Managing and storing Big Data requires specialized storage systems capable of handling large volumes of data.
”- Henry Morris, senior VP with IDC SAP is considering Apache Hadoop as large scale datastorage container for the Internet of Things (IoT) deployments and all other application deployments where datacollection and processing requirements are distributed geographically.
Data ingestion provides certain benefits to the business: The raw data coming from various sources is highly complex. However, a data ingestion framework reduces this complexity and makes it more interpretable. This data then could be utilized by various teams and stakeholders to make informed business decisions.
In this blog post, we will look at some of the world's highest paying data science jobs, what they entail, and what skills and experience you need to land them. What is Data Science? They manage datastorage and the ETL process. Generally, the range is $99,000 to $164,000.
Now you might be thinking about what a data structure is, well it is the specialized way of storing and arranging data in the computer’s memory, allowing for efficient retrieval, manipulation and utilization. Learning data structures is like understanding computer language. How are Data Structures Used?
Due to the data ingestion process, you can perform various operations like data analysis, dashboarding and other analytical and business tools. Like IoT devices, sensors, social media platforms, financial data, etc. It supports high-speed data streams from various sources and provides real-time insights.
Customer Segmentation: Storage and analysis of customer data makes it possible to gain valuable insights. This information can be utilized to create highly targeted customer segments. Personalization: Computer databases can be used to store and analyze customer data in real-time.
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. Big Data analytics processes and tools. Data ingestion.
Destination and Data Sharing The final component of the data pipeline involves its destinations – the points where processed data is made available for analysis and utilization. Plan the Data Consumption Layer Finally, it’s time to consider how the processed data will be put to use.
However, Big Data encompasses unstructured data, including text documents, images, videos, social media feeds, and sensor data. Handling this variety of data requires flexible datastorage and processing methods. Veracity: Veracity in big data means the quality, accuracy, and reliability of data.
These platforms excel in ingesting, organizing, and deploying data directly from and to your cloud data warehouse, thereby preserving the integrity and accessibility of your customer data within your own cloud infrastructure. The ELT platform offers 200+ pre-built connections to centralize data to any data platform.
Depending on what sort of leaky analogy you prefer, data can be the new oil , gold , or even electricity. Of course, even the biggest data sets are worthless, and might even be a liability, if they arent organized properly. Datacollected from every corner of modern society has transformed the way people live and do business.
Data Structure: What Is It? Data types from data administration, categorization, and warehousing are included in the data structure so that customers who utilize the information for their businesses can have adequate access. In the chapter below, a few key data structures have been covered.
Data ingestion can be divided into two categories: . A batch is a method of gathering and delivering huge data groups at once. Conditions can trigger datacollection, scheduled or done on the fly. A constant flow of data is referred to as streaming. For real-time data analytics, this is required.
Business Intelligence is closely knitted to the field of data science since it leverages information acquired through large data sets to deliver insightful reports. Companies utilize different approaches to deal with data in order to extract information from structured, semi-structured, or unstructured data sets.
Unauthorized or malicious changes made to data can undermine the business purposes that use the data. If undetected, corruption of data and its information will compromise the processes that utilize that data. If detected, investigation and correction will consume resources.
Logstash is a server-side data processing pipeline that ingests data from multiple sources, transforms it, and then sends it to Elasticsearch for indexing. Fluentd is a data collector and a lighter-weight alternative to Logstash. It is designed to unify datacollection and consumption for better use and understanding.
Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization Image Credit: twitter.com There are hundreds of companies like Facebook, Twitter, and LinkedIn generating yottabytes of data.
There are three steps involved in the deployment of a big data model: Data Ingestion: This is the first step in deploying a big data model - Data ingestion, i.e., extracting data from multiple data sources. Data Variety Hadoop stores structured, semi-structured and unstructured data.
PySpark is a handy tool for data scientists since it makes the process of converting prototype models into production-ready model workflows much more effortless. Another reason to use PySpark is that it has the benefit of being able to scale to far more giant data sets compared to the Python Pandas library.
Fingerprint Technology-Based ATM This project aims to enhance the security of ATM transactions by utilizing fingerprint recognition for user authentication. Top Software Engineer Project Ideas for Beginners 1. cvtColor(image, cv2.COLOR_BGR2GRAY) COLOR_BGR2GRAY) _, thresh = cv2.threshold(gray_image, threshold(gray_image, 127, 255, cv2.THRESH_BINARY)
AI has enabled businesses to generate more data, interpret it faster and utilize it to make smarter decisions. It is a strategic approach that supports organizations to effectively manage their data assets and ensure they are used responsibly and securely.
Additionally, some systems utilize pre-computed lists, such as those generated by data pipelines that identify the top 100 most popular content pieces globally, serving as another form of candidate generator. However, with the advancement of network technologies, there's been a shift back to remote storage.
Hadoop YARN – This platform is in charge of managing computing resources in clusters and utilizing them for planning users' applications. Hadoop MapReduce – This application of the MapReduce programming model is useful for large-scale data processing. Another name for Hadoop common is Hadoop Stack.
This involves: Building data pipelines and efficiently storing data for tools that need to query the data. Analyzing the data, ensuring it adheres to data governance rules and regulations. Understanding the pros and cons of datastorage and query options. This led to a 10% increase in conversion.
Difference between Data Science and Data Engineering Data Science Data Engineering Data Science involves extracting information from raw data to derive business insights and values using statistical methods. Data Engineering is associated with datacollecting, processing, analyzing, and cleaning data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























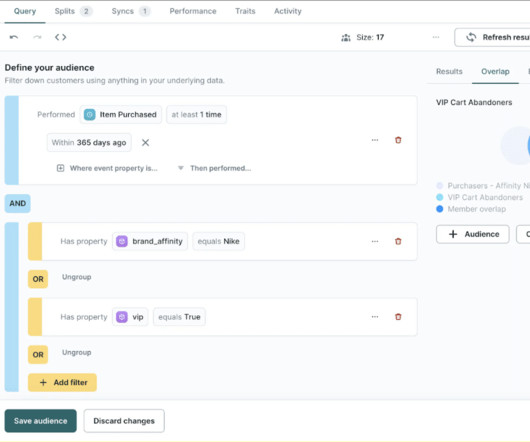



















Let's personalize your content