This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
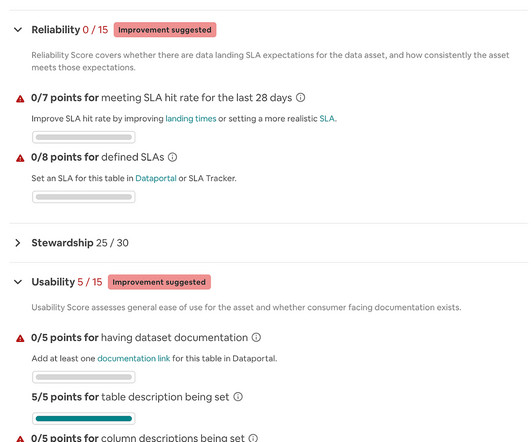
Storing data: datacollected is stored to allow for historical comparisons. Benchmarking: for new server types identified – or ones that need an updated benchmark executed to avoid data becoming stale – those instances have a benchmark started on them.
The data doesn’t accurately represent the real heights of the animals, so it lacks validity. Let’s dive deeper into these two crucial concepts, both essential for maintaining high-quality data. Let’s dive deeper into these two crucial concepts, both essential for maintaining high-quality data. What Is DataValidity?
The secret sauce is datacollection. Data is everywhere these days, but how exactly is it collected? This article breaks it down for you with thorough explanations of the different types of datacollection methods and best practices to gather information. What Is DataCollection?
Data quality refers to the degree of accuracy, consistency, completeness, reliability, and relevance of the datacollected, stored, and used within an organization or a specific context. High-quality data is essential for making well-informed decisions, performing accurate analyses, and developing effective strategies.
The value of that trust is why more and more companies are introducing Chief Data Officers – with the number doubling among the top publicly traded companies between 2019 and 2021, according to PwC. In this article: Why is data reliability important? Note that datavalidity is sometimes considered a part of data reliability.
In this article, we present six intrinsic data quality techniques that serve as both compass and map in the quest to refine the inner beauty of your data. Data Profiling 2. Data Cleansing 3. DataValidation 4. Data Auditing 5. Data Governance 6. Table of Contents 1.
Biases can arise from various factors such as sample selection methods, survey design flaws, or inherent biases in datacollection processes. Bugs in Application: Errors or bugs in datacollection, storage, and processing applications can compromise the accuracy of the data.
By: Clark Wright Introduction These days, as the volume of datacollected by companies grows exponentially, we’re all realizing that more data is not always better. In fact, more data, especially if you can’t rely on its quality, can hinder a company by slowing down decision-making or causing poor decisions.
What does a Data Processing Analysts do ? A data processing analyst’s job description includes a variety of duties that are essential to efficient data management. They must be well-versed in both the data sources and the data extraction procedures.
In a world where organizations rely heavily on data observability for informed decision-making, effective data testing methods are crucial to ensure high-quality standards across all stages of the data lifecycle—from datacollection and storage to processing and analysis.
And in the same way that no two organizations are identical, no two data integrity frameworks will be either. On the other hand, healthcare organizations with strict compliance standards related to sensitive patient information might require a completely different set of data integrity processes to maintain internal and external standards.
Data can go missing for nearly endless reasons, but here are a few of the most common challenges around data completeness: Inadequate datacollection processes Datacollection and data ingestion can cause data completion issues when collection procedures aren’t standardized, requirements aren’t clearly defined, and fields are incomplete or missing.
Introduction Transforming data to follow business rules can be a complex task, especially with the increasing amount of datacollected by companies. Figure 6 graphically illustrates the validation logic behind audit_helper.
Effective AI implementation requires data that’s accurate, consistent, and fit for purpose – which you gain with a proactive approach to data quality, robust data governance, and data observability. A strong data governance framework is the foundation of a comprehensive data quality solution to ensure trustworthy AI.
A business intelligence role typically consists of datacollection, analysis, and dissemination to the appropriate audience. A junior business intelligence analyst job description mainly comprises management of data retrieval and analysis within an organization.
The various steps in the data management process are listed below: . Datacollection, processing, validation, and archiving . Combining various data kinds, including both structured and unstructured data, from various sources . Ensuring catastrophe recovery and high data availability .
In other words, is it likely your data is accurate based on your expectations? Datacollection methods: Understand the methodology used to collect the data. Look for potential biases, flaws, or limitations in the datacollection process. is the gas station actually where the map says it is?).
link] Sarah Krasnik: The Analytics Requirements Document The first critical step to bringing data-driven culture into an organization is to embed the datacollection and analytical requirement part of the product development workflow.
If the data includes an old record or an incorrect value, then it’s not accurate and can lead to faulty decision-making. Data content: Are there significant changes in the data profile? Datavalidation: Does the data conform to how it’s being used?
An instructive example is clickstream data, which records a user’s interactions on a website. Another example would be sensor datacollected in an industrial setting. The common thread across these examples is that a large amount of data is being generated in real time.
Tianhui Michael Li The Three Rs of Data Engineering by Tobias Macey Data testing and quality Automate Your Pipeline Tests by Tom White Data Quality for Data Engineers by Katharine Jarmul DataValidation Is More Than Summary Statistics by Emily Riederer The Six Words That Will Destroy Your Career by Bartosz Mikulski Your Data Tests Failed!
For example, service agreements may cover data quality, latency, and availability, but they are outside the organization's control. Primary Data Sources are those where datacollection is from its point of creation before any processing. It may be raw data, validateddata, or big data.
Inaccurate Data: Establish an accountable culture and highlight the significance of data reporting to motivate team members to provide accurate information. To guarantee data quality, conduct regular audits and datavalidation checks.
If undetected, corruption of data and its information will compromise the processes that utilize that data. Personal DataCollecting and managing data carries regulatory responsibilities regarding data protection and evidence required for regulatory compliance.
Big data solutions that once took several hours for computations now can now be done just in few seconds with various predictive analytics tools that analyse tons of data points. Organizations need to collect thousands of data points to meet large scale decision challenges.
Design and maintain pipelines: Bring to life the robust architectures of pipelines with efficient data processing and testing. Collaborate with Management: Management shall collaborate, understanding the objectives while aligning data strategies. Databases: Knowledgeable about SQL and NoSQL databases.
Data quality control — to ensure that all information is correct by applying datavalidation logic. Data security and governance — to provide different security levels to admins, developers, and consumer groups as well as define clear data governance rules, removing barriers for information sharing. ?
Data freshness (aka data timeliness) means your data should be up-to-date and relevant to the timeframe of analysis. Datavalidity means your data conforms to the required format, type, or range of values. Example: Email addresses in the customer database should match a valid format (e.g.,
Here’s a quick breakdown of other day-to-day data analyst responsibilities apart from meetings and reporting– Collectdata from diverse sources and maintain them. Build and deploy datacollection systems. Define novel datacollection strategies as per business needs.
To ensure consistency in the data product definitions across domains, these guidelines should at least cover: Metadata standards: Define a standard set of metadata to accompany every data product. This might include information about the data source, the type of data, the date of creation, and any relevant context or description.
There are three steps involved in the deployment of a big data model: Data Ingestion: This is the first step in deploying a big data model - Data ingestion, i.e., extracting data from multiple data sources. It ensures that the datacollected from cloud sources or local databases is complete and accurate.
HBase is ideal for real time querying of big data where Hive is an ideal choice for analytical querying of datacollected over period of time. On issuing a delete command in HBase through the HBase client, data is not actually deleted from the cells but rather the cells are made invisible by setting a tombstone marker.
Inconsistent, outdated, or inaccurate data can compromise the results of your automation efforts. Solution: Regularly audit your data sources to ensure accuracy and consistency. Establish protocols for datavalidation and cleansing before integrating them into automated workflows.
Data Quality and Observability: Confidence in Every Pipeline In data integration, quality is everything. Bad data doesnt just waste time; it can lead to incorrect decisions and lost opportunities.
The data sources can be an RDBMS or some file formats like XLSX, CSV, JSON, etc., We need to extract data from all the sources and convert it into a single format for standardized processing. Validatedata: Validating the data after extraction is essential to ensure it matches the expected range and rejects it if it does not.
Verification is checking that data is accurate, complete, and consistent with its specifications or documentation. This includes checking for errors, inconsistencies, or missing values and can be done through various methods such as data profiling, datavalidation, and data quality assessments.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content