This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
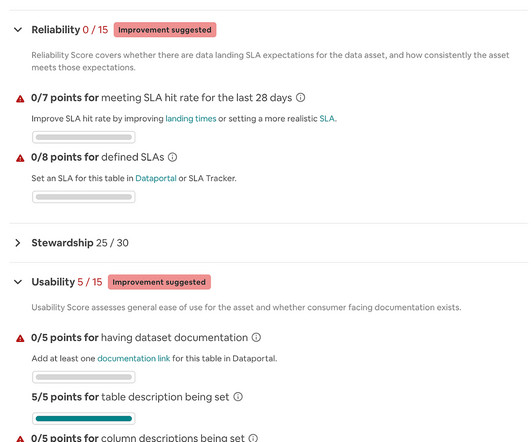
Dataquality refers to the degree of accuracy, consistency, completeness, reliability, and relevance of the datacollected, stored, and used within an organization or a specific context. High-qualitydata is essential for making well-informed decisions, performing accurate analyses, and developing effective strategies.
To maximize your investments in AI, you need to prioritize data governance, quality, and observability. Solving the Challenge of Untrustworthy AI Results AI has the potential to revolutionize industries by analyzing vast datasets and streamlining complex processes – but only when the tools are trained on high-qualitydata.
By: Clark Wright Introduction These days, as the volume of datacollected by companies grows exponentially, we’re all realizing that more data is not always better. In fact, more data, especially if you can’t rely on its quality, can hinder a company by slowing down decision-making or causing poor decisions.
On the other hand, “Can the marketing team easily segment the customer data for targeted communications?” usability) would be about extrinsic dataquality. Use of DataQuality Tools Refresh your intrinsic dataquality with data observability 1.
ML algorithms can be only as good as the data that we provide to it. This post will focus on the large volume of high-qualitydata stored in Axion?—?our Since we train our models on several weeks of data, this method is slow for us as we will have to wait for several weeks for the datacollection.
Recognizing the difference between big data and machine learning is crucial since big data involves managing and processing extensive datasets, while machine learning revolves around creating algorithms and models to extract valuable information and make data-driven predictions.
Generative algorithms go beyond the capabilities of discriminative models, which are best at identifying and classifying elements within a given data set, such as determining whether an email is spam. The generator produces high-qualitydata because the two networks are trained together in a game-like setting.
Big data has revolutionized the world of data science altogether. With the help of big data analytics, we can gain insights from large datasets and reveal previously concealed patterns, trends, and correlations. Learn more about the 4 Vs of big data with examples by going for the Big Data certification online course.
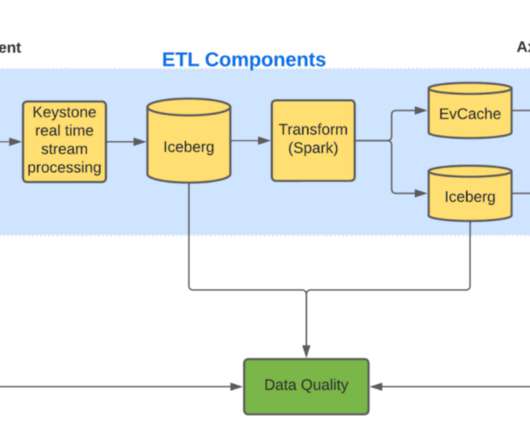
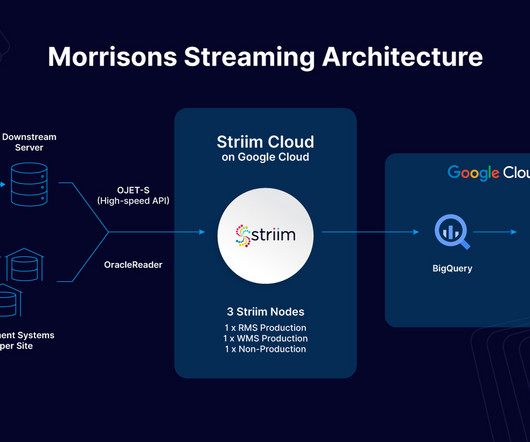
In contrast, data streaming offers continuous, real-time integration and analysis, ensuring predictive models always use the latest information. This step is pivotal in ensuring data consistency and relevance, essential for the accuracy of subsequent predictive models. Here’s the process.
This blog offers an exclusive glimpse into the daily rituals, challenges, and moments of triumph that punctuate the professional journey of a data scientist. The primary objective of a data scientist is to analyze complex datasets to uncover patterns, trends, and valuable information that can aid in informed decision-making.
In other words, is it likely your data is accurate based on your expectations? Datacollection methods: Understand the methodology used to collect the data. Look for potential biases, flaws, or limitations in the datacollection process. Consistency: Consistency is an important aspect of dataquality.
Data relevance. Including irrelevant data in the training dataset can make the model overly complex, as it tries to learn patterns that don’t actually fit the task. Just as bad dataquality and scarcity, irrelevance can cause the model to make incorrect predictions when presented with new, unseen data.
The key differences are that data integrity refers to having complete and consistent data, while data validity refers to correctness and real-world meaning – validity requires integrity but integrity alone does not guarantee validity. What is Data Integrity? How Do You Maintain Data Validity?
If you feel like you strike a match with predictive analytics, keep reading to learn a crucial part: what data the system will require to determine winning attributes. Key data points for predictive lead scoring. Let’s review all data points that can help the engine identify key attributes. Demographic data.
By examining these factors, organizations can make informed decisions on which approach best suits their data analysis and decision-making needs. Parameter Data Mining Business Intelligence (BI) Definition The process of uncovering patterns, relationships, and insights from extensive datasets.
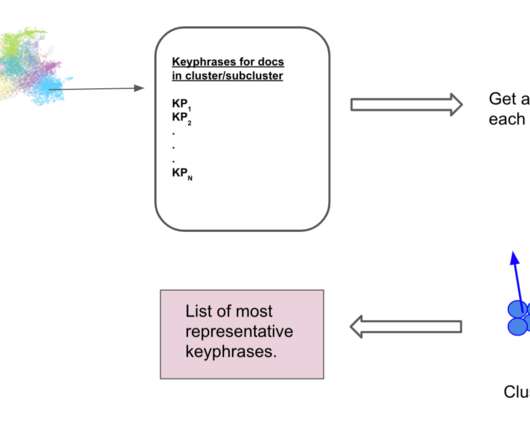
Additional insights from data In the first iteration of the model, we had a dataset for training collected by our experts to fit the definition of each category. Among them, active learning proved to be an important way to collect additional training samples and to guarantee the required granularity in the training set.
In this era of crowdsourcing platforms such as Amazon's Mechanical Turk and CrowdFlower , it makes sense to leverage these platforms to try to create these highqualitydata sets at a reasonable cost. This became our “fashion” dataset.
Knowledge of the definition and architecture of AWS Big Data services and their function in the data engineering lifecycle, including datacollection and ingestion, data analytics, data storage, data warehousing, data processing, and data visualization.
Instead, these teams can leverage business analysts who bring a combination of business understanding and familiarity with data. Typically a business analyst: Understands operational workflows and datacollection processes. BI Platforms: For data visualization and reporting.
should be similar to the data it is trained on. It does this by learning and finding patterns in the training dataset and analyzing them to create new content. Traditional AI primarily focuses on studying existing data to make decisions using the algorithms required. Typically, the process runs as follows: 1.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content