This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This was a great conversation about the complexities of working in a niche domain of data analysis and how to build a pipeline of highqualitydata from collection to analysis. The team at Audio Analytic are working to impart a sense of hearing to our myriad devices with their sound recognition technology.
In order to simplify the integration of AI capabilities into developer workflows Tsavo Knott helped create Pieces, a powerful collection of tools that complements the tools that developers already use. Data lakes are notoriously complex. Data lakes are notoriously complex. Your first 30 days are free! Sponsored By: Starburst :
Dataquality refers to the degree of accuracy, consistency, completeness, reliability, and relevance of the datacollected, stored, and used within an organization or a specific context. High-qualitydata is essential for making well-informed decisions, performing accurate analyses, and developing effective strategies.
Solving the Challenge of Untrustworthy AI Results AI has the potential to revolutionize industries by analyzing vast datasets and streamlining complex processes – but only when the tools are trained on high-qualitydata. So, the risk of entering into these initiatives without taking care of your data first is simply too high.
By: Clark Wright Introduction These days, as the volume of datacollected by companies grows exponentially, we’re all realizing that more data is not always better. In fact, more data, especially if you can’t rely on its quality, can hinder a company by slowing down decision-making or causing poor decisions.
The streaming event data within the product domain might benefit from being enriched by the custom datacollected by the centralized team, but that connection might never be made. two models for generative ai teams for more robust data teams. You can’t have a Gen AI project without discoverable, highqualitydata.
On the other hand, “Can the marketing team easily segment the customer data for targeted communications?” usability) would be about extrinsic dataquality. You might discover, for example, that a particular data source is consistently producing errors, indicating a need for better datacollection methods.
In contrast, data streaming offers continuous, real-time integration and analysis, ensuring predictive models always use the latest information. This makes it the superior option for timely and impactful insights — making it ideal for predictive analytics. Here’s the process.
How Predictive Maintenance Using AI Works: Let’s look at the process to understand how AI works in conjunction with predictive maintenance: DataCollection: Real-life data regarding various parameters such as temperature, pressure, vibration, and energy consumption is collected by sensors mounted on machines.
It moved from the speculation to the data engineers understanding the benefit of it and asking when we can get the implementation soon. I met many data leaders about Data Contracts, my project Schemata, and how the extended version we are building can help them create high-qualitydata.
The various steps in the data management process are listed below: . Datacollection, processing, validation, and archiving . Combining various data kinds, including both structured and unstructured data, from various sources . Ensuring catastrophe recovery and highdata availability .
GANs, or generative adversarial networks GANs, first developed by Ian Goodfellow in 2014, comprise a Discriminator network that assesses the data and a Generator network that generates it. The generator produces high-qualitydata because the two networks are trained together in a game-like setting.
The key differences are that data integrity refers to having complete and consistent data, while data validity refers to correctness and real-world meaning – validity requires integrity but integrity alone does not guarantee validity. What is Data Integrity?
Databand allows data engineering and data science teams to define dataquality rules, monitor data consistency, and identify data drift or anomalies. It also provides real-time notifications and alerts, enabling teams to proactively address issues and maintain high-qualitydata.
ML algorithms can be only as good as the data that we provide to it. This post will focus on the large volume of high-qualitydata stored in Axion?—?our Since we train our models on several weeks of data, this method is slow for us as we will have to wait for several weeks for the datacollection.
Big data insights assist in making informed decisions, while machine learning models automate decision-making based on acquired patterns. DataQuality: Both big data and machine learning demand high-qualitydata for reliable outcomes. What Should You Choose Between Big Data and Machine Learning?
AI models are only as good as the data they consume, making continuous data readiness crucial. Here are the key processes that need to be in place to guarantee consistently high-qualitydata for AI models: Data Availability: Establish a process to regularly check on data availability.
For example, highquality leads will be contacted directly by sales people, medium quality leads will receive a series of automatic personalized emails, and low quality leads will be ignored or pushed to provide more data, for example, by filling in the form. How much data is enough?
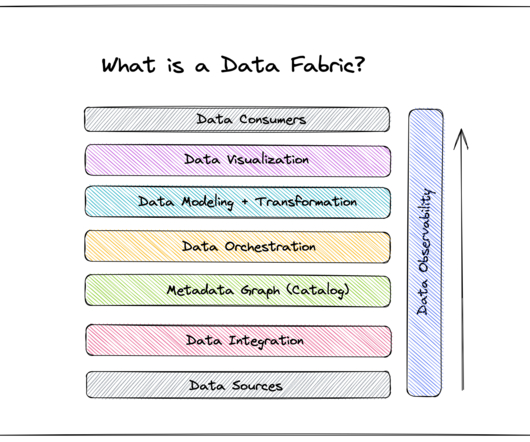
Ducati’s advantage lies in the volumes of valuable performance data that help drive innovation. Ducati built a data fabric that leveraged datacollected by sensors installed on each of its motorcycles. Ready to get started building your data fabric with reliable, high-qualitydata you can trust?
Ducati’s advantage lies in the volumes of valuable performance data that help drive innovation. Ducati built a data fabric that leveraged datacollected by sensors installed on each of its motorcycles. Ready to get started building your data fabric with reliable, high-qualitydata you can trust?
In other words, is it likely your data is accurate based on your expectations? Datacollection methods: Understand the methodology used to collect the data. Look for potential biases, flaws, or limitations in the datacollection process.
A Day in the Life of a Data Scientist: Daily responsibilities The daily responsibilities of a data scientist are diverse and multifaceted, reflecting the dynamic nature of their role. This involves writing scripts, using data extraction tools, and ensuring dataquality. Will data scientists be replaced by AI ?
It involves assessing the credibility and reputation of the sources from which the data is obtained. Data from trustworthy and reputable sources are more reliable and dependable. On the other hand, "methodology" refers to the techniques and procedures used for datacollection, processing, and analysis.
Among them, active learning proved to be an important way to collect additional training samples and to guarantee the required granularity in the training set. Annotation alignment - Highqualitydata and model performance are both connected to the annotation process (see more here ).
Data orchestration helps companies comply with various international privacy laws and regulations, many of which require companies to demonstrate the source and rationale for their datacollection. As data volume grows, scheduling becomes critical to successfully managing your data ingestion and transformation jobs.
DataQuality: Data Mining and BI rely on the availability of high-qualitydata. Both disciplines emphasize the importance of data accuracy, completeness, consistency, and reliability to ensure the reliability of the insights derived.
There are many reasons why the modern insurance sector prefers machine learning and data science : Rapidly growing data volumes- Consumer electronics with an internet connection, such as smartphones, smart TVs, and fitness trackers, are becoming increasingly popular today.
In this era of crowdsourcing platforms such as Amazon's Mechanical Turk and CrowdFlower , it makes sense to leverage these platforms to try to create these highqualitydata sets at a reasonable cost. Even with our "massive" overspend on the first job, we still spent less than $10 total on our experiments.
Secondly, BI requires access to high-qualitydata sources. If you do not have reliable data, your BI initiatives will not be successful. If you are considering implementing BI within your business, there are a few things to keep in mind.
With sufficient and qualitydata in place, ML becomes a valuable tool to forecast hotel deals. Datacollection and preprocessing As with any machine learning task, it all starts with high-qualitydata that should be enough for training a model. So how exactly are hotel price prediction tools built?
In addition to harming business ambitions, bad data can also affect corporate decision-making overall. According to Gartner , businesses spend $15 million per year on poor dataquality. The lack of systematic and continuous datacollection affects the quality of insights based on incomplete, inaccurate, or bad data.
But have a clear set of use cases that the platform will support, and sufficient flexibility in implementation and datacollection to allow for less common or more complex experiments to be reliably delivered. Don’t assume you can buy or build the platform to support all use cases.
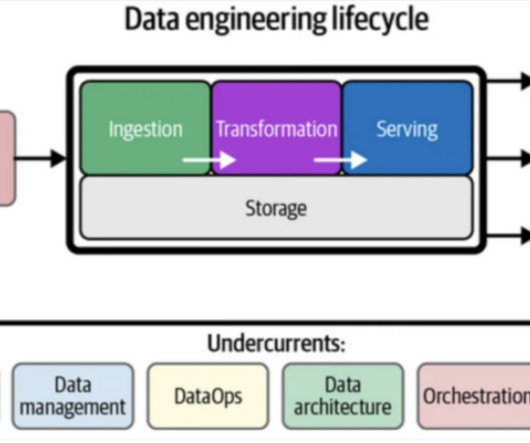
Knowledge of the definition and architecture of AWS Big Data services and their function in the data engineering lifecycle, including datacollection and ingestion, data analytics, data storage, data warehousing, data processing, and data visualization.
Instead, these teams can leverage business analysts who bring a combination of business understanding and familiarity with data. Typically a business analyst: Understands operational workflows and datacollection processes. These improvements empower sales teams to act on high-qualitydata, driving better outcomes.
Its goal is to understand the label data instead of creating a new one. Generative AI models work and revolve around learning from existing data and creating new ones. Generative Adversarial Networks are a powerful type of generative model used to create synthetic data that closely resembles real-world data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content