This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Storing data: datacollected is stored to allow for historical comparisons. Benchmarking: for new server types identified – or ones that need an updated benchmark executed to avoid data becoming stale – those instances have a benchmark started on them.
While today’s world abounds with data, gathering valuable information presents a lot of organizational and technical challenges, which we are going to address in this article. We’ll particularly explore datacollection approaches and tools for analytics and machine learning projects. What is datacollection?
The primary goal of datacollection is to gather high-quality information that aims to provide responses to all of the open-ended questions. Businesses and management can obtain high-quality information by collectingdata that is necessary for making educated decisions. . What is DataCollection?
The secret sauce is datacollection. Data is everywhere these days, but how exactly is it collected? This article breaks it down for you with thorough explanations of the different types of datacollection methods and best practices to gather information. What Is DataCollection?
The data journey is not linear, but it is an infinite loop data lifecycle – initiating at the edge, weaving through a data platform, and resulting in business imperative insights applied to real business-critical problems that result in new data-led initiatives. DataCollection Challenge. Factory ID.
For more information, check out the best Data Science certification. A data scientist’s job description focuses on the following – Automating the collection process and identifying the valuable data. To pursue a career in BI development, one must have a strong understanding of data mining, data warehouse design, and SQL.
Data: In this sheet, you can save the rawdata tables. Enter Your Data Into Excel Spreadsheet You must select data sources before you can build an Excel Dashboard. If not, you must utilize external data sources. Select one of the import options from the Data tab.
If the general idea of stand-up meetings and sprint meetings is not taken into consideration, a day in the life of a data scientist would revolve around gathering data, understanding it, talking to relevant people about the data, asking questions about it, reiterating the requirement and the end product, and working on how it can be achieved.
The greatest data processing challenge of 2024 is the lack of qualified data scientists with the skill set and expertise to handle this gigantic volume of data. Inability to process large volumes of data Out of the 2.5 quintillion data produced, only 60 percent workers spend days on it to make sense of it.
The modeling process begins with datacollection. Here, Cloudera Data Flow is leveraged to build a streaming pipeline which enables the collection, movement, curation, and augmentation of rawdata feeds. These feeds are then enriched using external data sources (e.g.,
The one requirement that we do have is that after the data transformation is completed, it needs to emit JSON. data transformations can be defined using the Kafka Table Wizard. This might be OK for some cases.
Audio data transformation basics to know. Before diving deeper into processing of audio files, we need to introduce specific terms, that you will encounter at almost every step of our journey from sound datacollection to getting ML predictions. One of the largest audio datacollections is AudioSet by Google.
Ever wondered why building data-driven applications feels like an uphill battle? It’s not just you – turning rawdata into something meaningful can be a real challenge. This prolonged timeline is not just a minor inconvenience; it is the bottleneck that hampers responsiveness and agility in decision-making.
Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making. These data sources serve as the starting point for the pipeline, providing the rawdata that will be ingested, processed, and analyzed.
It involves extracting meaningful features from the data and using them to make informed decisions or predictions. DataCollection and Pre-processing The first step is to collect the relevant data that contains the patterns of interest. The steps involved in it can be summarized as follows: 1.
Data is an important feature for any organization because of its ability to guide decision-making based on facts, statistical numbers, and trends. Data Science is a notion that entails datacollection, processing, and exploration, which leads to data analysis and consolidation.
However, as we progressed, data became complicated, more unstructured, or, in most cases, semi-structured. This mainly happened because data that is collected in recent times is vast and the source of collection of such data is varied, for example, datacollected from text files, financial documents, multimedia data, sensors, etc.
Methodology In order to meet the technical requirements for recommender system development as well as other emerging data needs, the client has built a mature data pipeline through the use of cloud platforms like AWS in order to store user clickstream data, and Databricks in order to process the rawdata.
Methodology In order to meet the technical requirements for recommender system development as well as other emerging data needs, the client has built a mature data pipeline through the use of cloud platforms like AWS in order to store user clickstream data, and Databricks in order to process the rawdata.
Data Versioning: Want to know how your data changed over time? Improved Performance: Rawdata lakes can be slow since they require scanning every file during a search. Delta Lake speeds things up by optimizing queries, giving you faster results without locking you into a rigid data warehouse. Why Data Lake?
The role can also be defined as someone who has the knowledge and skills to generate findings and insights from available rawdata. Data Engineer A professional who has expertise in data engineering and programming to collect and covert rawdata and build systems that can be usable by the business.
Identify and study the rawdata. Modeling Test and optimize the output Productionise into a usable format [link] Sponsored: Replacing GA4 with Analytics on your Data Cloud The GA4 migration deadline is fast approaching. Join our webinar to learn how you can replace GA with analytics on your data cloud.
Organisations and businesses are flooded with enormous amounts of data in the digital era. Rawdata, however, is frequently disorganised, unstructured, and challenging to work with directly. Data processing analysts can be useful in this situation. What does a Data Processing Analysts do ?
More importantly, we will contextualize ELT in the current scenario, where data is perpetually in motion, and the boundaries of innovation are constantly being redrawn. Extract The initial stage of the ELT process is the extraction of data from various source systems. What Is ELT? So, what exactly is ELT?
If you work at a relatively large company, you've seen this cycle happening many times: Analytics team wants to use unstructured data on their models or analysis. For example, an industrial analytics team wants to use the logs from rawdata. Data Sources: How different are your data sources?
By implementing an observability pipeline, which typically consists of multiple technologies and processes, organizations can gain insights into data pipeline performance, including metrics, errors, and resource usage. This ensures the reliability and accuracy of data-driven decision-making processes.
Receipt table (later referred to as table_receipts_index): It turns out that all the receipts were manually entered into the system, which creates unstructured data that is error-prone. This datacollection method was chosen because it was simple to deploy, with each employee responsible for their own receipts.
This data is typically used by system apps to inform users when apps are disproportionately draining their battery and provide estimates of remaining battery hours depending on their personal usage. We use power to monitor the power Our datacollection service is clearly going to be consuming some power when collecting energy values.
Transforming Data Complexity into Strategic Insight At first glance, the process of transforming rawdata into actionable insights can seem daunting. The journey from datacollection to insight generation often feels like operating a complex machine shrouded in mystery and uncertainty.
You can find a comprehensive guide on how data ingestion impacts a data science project with any Data Science course. Why Data Ingestion is Important? Data ingestion provides certain benefits to the business: The rawdata coming from various sources is highly complex. Why Data Ingestion is Important?
DL models automatically learn features from rawdata, eliminating the need for explicit feature engineering. Machine Learning vs Deep Learning: Feature Engineering ML algorithms require manual feature engineering, where domain experts extract and engineer relevant features from the data.
Factors Data Engineer Machine Learning Definition Data engineers create, maintain, and optimize data infrastructure for data. In addition, they are responsible for developing pipelines that turn rawdata into formats that data consumers can use easily.
The fundamental purpose of a data warehouse is the aggregation of information from diverse sources to inform data-driven decision-making processes. What is a Data Lake? There is no processing to integrate and manage data, including quality checks or detect inconsistencies, duplications, or discrepancies.
As a data engineer, my time is spent either moving data from one place to another, or preparing it for exposure to either reporting tools or front end users. As datacollection and usage have become more sophisticated, the sources of data have become a lot more varied and disparate, volumes have grown and velocity has increased.
Levels of Data Aggregation Now lets look at the levels of data aggregation Level 1: At this level, unprocessed data are collected from various sources and put in one source. Level 2: At this stage, the rawdata is processed and cleaned to get rid of inconsistent data, duplicates values, and error in datatype.
The key differentiation lies in the transformational steps that a data pipeline includes to make data business-ready. Ultimately, the core function of a pipeline is to take rawdata and turn it into valuable, accessible insights that drive business growth. cleaning, formatting)?
We use different SAS statements for reading the data, cleaning and manipulating it in the data step prior to analyzing it. The rawdata gets transformed into a SAS dataset during the data stage. SAS library Remote access for data sources such as Azure, SAS catalogue, Hadoop, S3, zip and more.
For example, service agreements may cover data quality, latency, and availability, but they are outside the organization's control. Primary Data Sources are those where datacollection is from its point of creation before any processing. It may be rawdata, validated data, or big data.
In 2023, Business Intelligence (BI) is a rapidly evolving field focusing on datacollection, analysis, and interpretation to enhance decision-making in organizations. Careful consideration of research methodology, datacollection methods, and analysis techniques helps in ensuring the validity and reliability of your findings.
Data Science- Definition Data Science is an interdisciplinary branch encompassing data engineering and many other fields. Data Science involves applying statistical techniques to rawdata, just like data analysts, with the additional goal of building business solutions. Who is a Data Scientist?
.” In this article, you will find out what data labeling is, how it works, which data labeling types exist, and what best practices to follow to make this process smooth as glass. What is data labeling? A label or a tag is a descriptive element that tells a model what an individual data piece is so it can learn by example.
Data plays a crucial role in identifying opportunities for growth and decision-making in today's business landscape. Business intelligence collects techniques, tools, and methodologies organizations use to transform rawdata into valuable information and meaningful insights. Automation can help businesses in several ways.
They employ a wide array of tools and techniques, including statistical methods and machine learning, coupled with their unique human understanding, to navigate the complex world of data. A significant part of their role revolves around collecting, cleaning, and manipulating data, as rawdata is seldom pristine.
In this respect, the purpose of the blog is to explain what is a data engineer , describe their duties to know the context that uses data, and explain why the role of a data engineer is central. What Does a Data Engineer Do? Design algorithms transforming rawdata into actionable information for strategic decisions.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















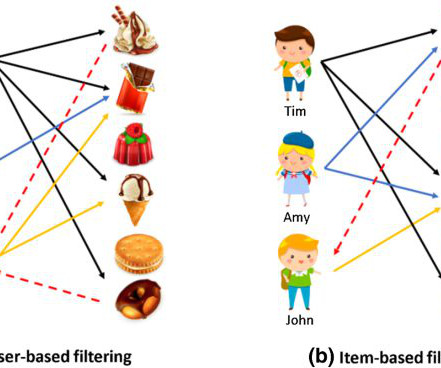
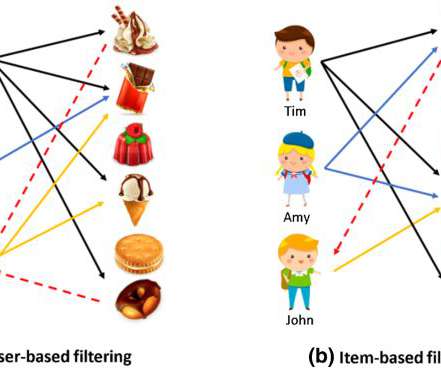
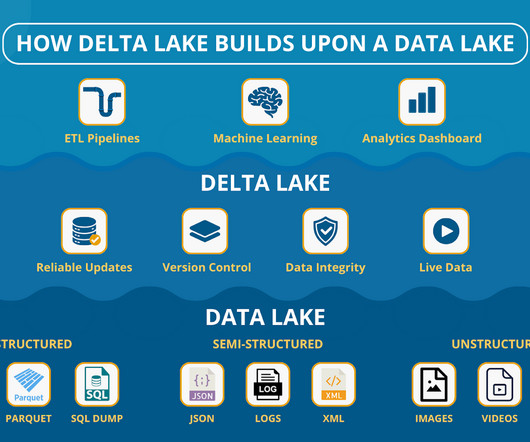






























Let's personalize your content