This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While today’s world abounds with data, gathering valuable information presents a lot of organizational and technical challenges, which we are going to address in this article. We’ll particularly explore datacollection approaches and tools for analytics and machine learning projects. What is datacollection?
The primary goal of datacollection is to gather high-quality information that aims to provide responses to all of the open-ended questions. Businesses and management can obtain high-quality information by collectingdata that is necessary for making educated decisions. . What is DataCollection?
You’ll learn about the types of recommender systems, their differences, strengths, weaknesses, and real-life examples. Personalization and recommender systems in a nutshell. Primarily developed to help users deal with a large range of choices they encounter, recommender systems come into play. Amazon, Booking.com) and.
Preamble Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline you’ll need somewhere to deploy it, so check out Linode. What are the limitations of crowd-sourced data labels? What are the limitations of crowd-sourced data labels?
Here are six key components that are fundamental to building and maintaining an effective data pipeline. Data sources The first component of a modern data pipeline is the data source, which is the origin of the data your business leverages. Historically, batch processing was sufficient for many use cases.
They build scalable data processing pipelines and provide analytical insights to business users. A Data Engineer also designs, builds, integrates, and manages large-scale data processing systems. Let’s take a look at Morgan Stanley interview question : What is data engineering? What is a data warehouse?
These projects typically involve a collaborative team of software developers, data scientists, machine learning engineers, and subject matter experts. The development process may include tasks such as building and training machine learning models, datacollection and cleaning, and testing and optimizing the final product.
You might think that datacollection in astronomy consists of a lone astronomer pointing a telescope at a single object in a static sky. While that may be true in some cases (I collected the data for my Ph.D. thesis this way), the field of astronomy is rapidly changing into a data-intensive science with real-time needs.
The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. The framework provides a way to divide a huge datacollection into smaller chunks and shove them across interconnected computers or nodes that make up a Hadoop cluster. cost-effectiveness.
Among the use cases for the government organizations that we are working on is one which leverages machine learning to detect fraud in payment systems nationwide. Through processing vast amounts of structured and semi-structureddata, AI and machine learning enabled effective fraud prevention in real-time on a national scale. .
A database is a structureddatacollection that is stored and accessed electronically. File systems can store small datasets, while computer clusters or cloud storage keeps larger datasets. According to a database model, the organization of data is known as database design.
They identify business problems and opportunities to enhance the practices, processes, and systems within an organization. Using Big Data, they provide technical solutions and insights that can help achieve business goals. They transform data into easily understandable insights using predictive, prescriptive, and descriptive analysis.
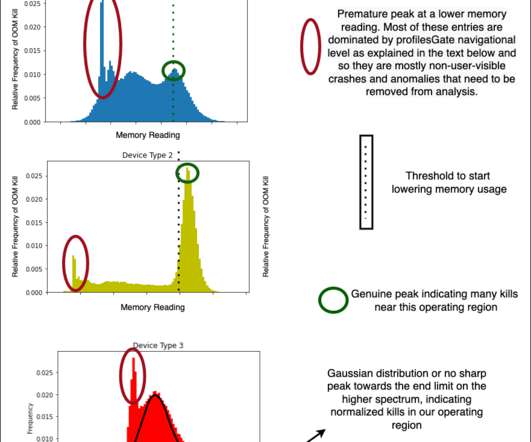
It also prevents the system running out of memory during execution of the query. Striking a balance between driver and executor memory configurations in SparkSQL-like systems. Too high allocations may fail and restrict system processes. Labeling the data? Restricting Testing and Analysis to one day and device at a time.
Artificial Intelligence, at its core, is a branch of Computer Science that aims to replicate or simulate human intelligence in machines and systems. These streams basically consist of algorithms that seek to make either predictions or classifications by creating expert systems that are based on the input data.
What is unstructured data? Definition and examples Unstructured data , in its simplest form, refers to any data that does not have a pre-defined structure or organization. It can come in different forms, such as text documents, emails, images, videos, social media posts, sensor data, etc. Sensor data.
Big Data vs Small Data: Function Variety Big Data encompasses diverse data types, including structured, unstructured, and semi-structureddata. It involves handling data from various sources such as text documents, images, videos, social media posts, and more.
Focus Exploration and discovery of hidden patterns and trends in data. Reporting, querying, and analyzing structureddata to generate actionable insights. Data Sources Diverse and vast data sources, including structured, unstructured, and semi-structureddata.
Similar laws in other jurisdictions are raising the stakes for enterprises, compelling them to govern their data more effectively than they have in the past. Traditional frameworks for data governance often work well for smaller volumes of data, and for highly structureddata. Here are five to consider.
A single car connected to the Internet with a telematics device plugged in generates and transmits 25 gigabytes of data hourly at a near-constant velocity. And most of this data has to be handled in real-time or near real-time. Variety is the vector showing the diversity of Big Data. Data storage and processing.
Depending on what sort of leaky analogy you prefer, data can be the new oil , gold , or even electricity. Of course, even the biggest data sets are worthless, and might even be a liability, if they arent organized properly. Datacollected from every corner of modern society has transformed the way people live and do business.
Specific Skills and Knowledge: Datacollection and storage optimization Data processing and interpretation Reporting and displaying statistical and pattern information Developing and evaluating models to handle huge amounts of data Understanding programming languages C. Data mining's usefulness varies per sector.
Goal To extract and transform data from its raw form into a structured format for analysis. To uncover hidden knowledge and meaningful patterns in data for decision-making. Data Source Typically starts with unprocessed or poorly structureddata sources. Analyzing and deriving valuable insights from data.
If you're wondering how the ETL process can drive your company to a new era of success, this blog will help you discover what use cases of ETL make it a critical component in many data management and analytic systems. Business Intelligence - ETL is a key component of BI systems for extracting and preparing data for analytics.
However, as we progressed, data became complicated, more unstructured, or, in most cases, semi-structured. This mainly happened because data that is collected in recent times is vast and the source of collection of such data is varied, for example, datacollected from text files, financial documents, multimedia data, sensors, etc.
Google AI: The Data Cards Playbook: A Toolkit for Transparency in Dataset Documentation Google published Data Cards , a dataset documentation framework aimed at increasing transparency across dataset lifecycles. The trade-off plays a critical role in a critical system like Experimentation.
Big data can be summed up as a sizable datacollection comprising a variety of informational sets. It is a vast and intricate data set. Big data has been a concept for some time, but it has only just begun to change the corporate sector. This knowledge is expanding quickly.
Change Data Capture (CDC) plays a key role here by capturing and streaming only the changes (inserts, updates, deletes) in real time, ensuring efficient data handling and up-to-date information across systems. Why are Data Pipelines Significant? Now that we’ve answered the question, ‘What is a data pipeline?’
In addition, business analysts benefit from using programming languages like Python and R to handle large amounts of data. Database management systems should also be something that business analysts can work on. To do this, they can extract, generate, and edit data from various databases using languages like SQL.
There are several basic and advanced types of datastructures for arranging the information for specific purposes. Datastructure makes it very easy to maintain data as per your requirements. Most importantly, datastructures frame the organization of data so the computer system and humans can better understand it.
This velocity aspect is particularly relevant in applications such as social media analytics, financial trading, and sensor data processing. Variety: Variety represents the diverse range of data types and formats encountered in Big Data. Handling this variety of data requires flexible data storage and processing methods.
ELT (Extract, Load, Transform) is a data integration technique that collects raw data from multiple sources and directly loads it into the target system, typically a cloud data warehouse. Extract The initial stage of the ELT process is the extraction of data from various source systems.
There are three steps involved in the deployment of a big data model: Data Ingestion: This is the first step in deploying a big data model - Data ingestion, i.e., extracting data from multiple data sources. RDBMS is a part of system software used to create and manage databases based on the relational model.
Did you know that almost all database management systems (DBMS) use a particular data organization model? This article provides an introduction to the relational model, which is by far the most common data organization model in DBMS today. In the concept of a relational database management system, data is organized into tables.
They are essential to the data lifecycle because they take unstructured data and turn it into something that can be used. They are responsible for processing, cleaning, and transforming raw data into a structured and usable format for further analysis or integration into databases or datasystems.
This article will define in simple terms what a data warehouse is, how it’s different from a database, fundamentals of how they work, and an overview of today’s most popular data warehouses. What is a data warehouse? An ETL tool or API-based batch processing/streaming is used to pump all of this data into a data warehouse.
ML algorithms are versatile and widely used across various domains, including finance, healthcare, marketing , and recommendation systems. DL models have demonstrated superior performance in several domains, particularly in tasks involving complex and unstructured data. When to Use Deep Learning 1.
For example, Amazon Redshift can load static data to Spark and process it before sending it to downstream systems. Image source - Databricks You can analyze the datacollected in real-time ad-hoc using Spark and post-processed for report generation. live logs, IoT device data, system telemetry data, etc.)
It’s a continuous and unbounded stream of information that is generated at a high frequency and delivered to a system or application. An instructive example is clickstream data, which records a user’s interactions on a website. Another example would be sensor datacollected in an industrial setting.
Data can go missing for nearly endless reasons, but here are a few of the most common challenges around data completeness: Inadequate datacollection processes Datacollection and data ingestion can cause data completion issues when collection procedures aren’t standardized, requirements aren’t clearly defined, and fields are incomplete or missing.
Life sciences organizations are continually sharing data—with collaborators, clinical partners, and pharmaceutical industry data services. But legacy systems and data silos prevent easy and secure data sharing. Snowflake can help life sciences companies query and analyze data easily, efficiently, and securely.
Data monitoring is very static and reactive, simply showing a limited view of an isolated incident of failure. Data observability, on the other hand, is much more holistic and proactive, uncovering the root case of an issue and its impact on downstream systems.
In a dimensional approach, data partitioning techniques separately store facts and dimensions. Typically, organizational business processes and systems define the facts, while dimensions provide the metrics for the facts. What is a Data Lake? The facts are valuable information, and the dimensions provide context to these facts.
Data science and artificial intelligence might be the buzzwords of recent times, but they are of no value without the right data backing them. The process of datacollection has increased exponentially over the last few years. NoSQL databases are designed to store unstructured data like graphs, documents, etc.,
PySpark is a handy tool for data scientists since it makes the process of converting prototype models into production-ready model workflows much more effortless. Another reason to use PySpark is that it has the benefit of being able to scale to far more giant data sets compared to the Python Pandas library.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content