This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The primary goal of datacollection is to gather high-quality information that aims to provide responses to all of the open-ended questions. Businesses and management can obtain high-quality information by collectingdata that is necessary for making educated decisions. . What is DataCollection?
Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making. These data sources serve as the starting point for the pipeline, providing the raw data that will be ingested, processed, and analyzed.
Best website for data visualization learning: geeksforgeeks.org Start learning Inferential Statistics and Hypothesis Testing Exploratory data analysis helps you to know patterns and trends in the data using many methods and approaches. In data analysis, EDA performs an important role.
Let’s take a look at Morgan Stanley interview question : What is data engineering? The data engineering process involves the creation of systems that enable the collection and utilization of data. Analyzing this data often involves Machine Learning, a part of Data Science. What is AWS Kinesis?
Artificial intelligence (AI) projects are software-based initiatives that utilize machine learning, deep learning, natural language processing, computer vision, and other AI technologies to develop intelligent programs capable of performing various tasks with minimal human intervention. Let us get started!
Big data can be summed up as a sizable datacollection comprising a variety of informational sets. It is a vast and intricate data set. Big data has been a concept for some time, but it has only just begun to change the corporate sector. This results in a lack of management of data effectively. use big data.
What is unstructured data? Definition and examples Unstructured data , in its simplest form, refers to any data that does not have a pre-defined structure or organization. It can come in different forms, such as text documents, emails, images, videos, social media posts, sensor data, etc.
The answer lies in the strategic utilization of business intelligence for data mining (BI). This table highlights various aspects such as data mining for business intelligence concepts techniques and applications. Focus Exploration and discovery of hidden patterns and trends in data.
Big Data vs Small Data: Function Variety Big Data encompasses diverse data types, including structured, unstructured, and semi-structureddata. It involves handling data from various sources such as text documents, images, videos, social media posts, and more.
Depending on what sort of leaky analogy you prefer, data can be the new oil , gold , or even electricity. Of course, even the biggest data sets are worthless, and might even be a liability, if they arent organized properly. Datacollected from every corner of modern society has transformed the way people live and do business.
The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. The framework provides a way to divide a huge datacollection into smaller chunks and shove them across interconnected computers or nodes that make up a Hadoop cluster.
4 Purpose Utilize the derived findings and insights to make informed decisions The purpose of AI is to provide software capable enough to reason on the input provided and explain the output 5 Types of Data Different types of data can be used as input for the Data Science lifecycle.
Its flexibility allows organizations to leverage data value, regardless of its format or source, and can reside in various storage environments, from on-premises solutions to cloud-based platforms or a hybrid approach, tailored to the organization's specific needs and strategies. What is the purpose of extracting data?
There are many data science fields in which experts may contribute to the success of a business, and you can hone the abilities you need by specializing in data science subfields. Data Engineering and Warehousing The data is the lifeblood of every successful Data Science endeavor.
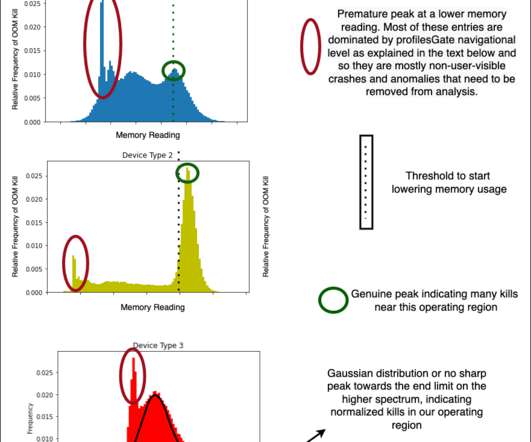
Data Analysis and Observations Without diving very deep into the actual devices and results of the classification, we now show some examples of how we could use the structureddata for some preliminary analysis and make observations. We will try to soon post results of our models on the dataset that we have created.
Big data stands out due to its significant volume, quick velocity, and wide variety, leading to difficulties in storage, processing, analysis, and interpretation. Organizations can utilize big data to discover valuable insights, patterns, and trends that encourage innovation, enhance decision-making, and boost operational efficiency.
The new features also enable customers to easily search in logs and semi-structureddata stored in VARIANT, ARRAY, and OBJECT columns, which prove to be especially useful for cybersecurity vendors who perform needle-in-a-haystack-type queries. メディカル・データ・ビジョン株式会社 ) Medical Data Vision Co., Abacus Insights, Inc.
Now you might be thinking about what a datastructure is, well it is the specialized way of storing and arranging data in the computer’s memory, allowing for efficient retrieval, manipulation and utilization. Learning datastructures is like understanding computer language.
SQL and SQL Server BAs must deal with the organization's structureddata. BAs can store and process massive volumes of data with the use of these databases. It is utilized by BAs to carry out various calculations, data, and budget assessments. They produce pivot tables to summarize the data.
However, the vast volume of data will overwhelm you if you start looking at historical trends. The time-consuming method of datacollection and transformation can be eliminated using ETL. You can analyze and optimize your investment strategy using high-quality structureddata.
By utilizing ML algorithms and data, it is possible to create smart models that can precisely predict customer intent and as such provide quality one-to-one recommendations. At the same time, the continuous growth of available data has led to information overload — when there are too many choices, complicating decision-making.
DataStructure: What Is It? Data types from data administration, categorization, and warehousing are included in the datastructure so that customers who utilize the information for their businesses can have adequate access. They enable effective recall utilization.
PySpark is a handy tool for data scientists since it makes the process of converting prototype models into production-ready model workflows much more effortless. Another reason to use PySpark is that it has the benefit of being able to scale to far more giant data sets compared to the Python Pandas library.
A single car connected to the Internet with a telematics device plugged in generates and transmits 25 gigabytes of data hourly at a near-constant velocity. And most of this data has to be handled in real-time or near real-time. Variety is the vector showing the diversity of Big Data.
This velocity aspect is particularly relevant in applications such as social media analytics, financial trading, and sensor data processing. Variety: Variety represents the diverse range of data types and formats encountered in Big Data. Handling this variety of data requires flexible data storage and processing methods.
And analytic workflows involve periods of intense computation followed by relatively low utilization. Life sciences organizations are continually sharing data—with collaborators, clinical partners, and pharmaceutical industry data services. But legacy systems and data silos prevent easy and secure data sharing.
Moreover, Spark SQL makes it possible to combine streaming data with a wide range of static data sources. For example, Amazon Redshift can load static data to Spark and process it before sending it to downstream systems. Kafka Streams is a client library for processing and analyzing Kafka data inputs.
Business Intelligence is closely knitted to the field of data science since it leverages information acquired through large data sets to deliver insightful reports. Companies utilize different approaches to deal with data in order to extract information from structured, semi-structured, or unstructured data sets.
In fact, in recent times, more data has been created than in the entire history of the human species, and this trend is only expected to continue. Datacollecting and storage have grown increasingly more difficult with so many ways to connect to and access the internet.
There are three steps involved in the deployment of a big data model: Data Ingestion: This is the first step in deploying a big data model - Data ingestion, i.e., extracting data from multiple data sources. Data Variety Hadoop stores structured, semi-structured and unstructured data.
Here’s an example showing how to utilize the distinct() and dropDuplicates() methods- First, we need to create a sample dataframe. Cluster mode should be utilized for deployment if the client computers are not near the cluster. Client mode can be utilized for deployment if the client computer is located within the cluster.
What Is Data Manipulation? . In data manipulation, data is organized in a way that makes it easier to read, or that makes it more visually appealing, or that makes it more structured. Datacollections can be organized alphabetically to make them easier to understand. .
Don’t forget to publish business key definitions for relating domain data and maintain a simple-to-use catalog of domain data. These practices can support data users across domains in efficiently locating and utilizing the data they need.
Thus, as a learner, your goal should be to work on projects that help you explore structured and unstructured data in different formats. Data Warehousing: Data warehousing utilizes and builds a warehouse for storing data. A data engineer interacts with this warehouse almost on an everyday basis.
Hadoop vs RDBMS Criteria Hadoop RDBMS Datatypes Processes semi-structured and unstructured data. Processes structureddata. Schema Schema on Read Schema on Write Best Fit for Applications Data discovery and Massive Storage/Processing of Unstructured data. are all examples of unstructured data.
Work on Interesting Big Data and Hadoop Projects to build an impressive project portfolio! How big data helps businesses? Companies using big data excel in sorting the growing influx of big datacollected, filtering out the relevant information to draw deeper insights through big data analytics.
Data Engineer Interview Questions on Big Data Any organization that relies on data must perform big data engineering to stand out from the crowd. But datacollection, storage, and large-scale data processing are only the first steps in the complex process of big data analysis.
In order to uncover intricate patterns, each neuron in a hidden layer applies activation functions, biases, and weights to the data from the layer below it. The output is utilized as the anticipated value in regression. Data Preprocessing: Tools for cleaning, normalizing, and augmenting data to ensure accuracy and relevance.
Not all of this data is erroneous. The majority of this unstructured, meaningless data can be well converted into a more organized (tabular/more comprehensible) format. In simpler terms, good data use implies thriving businesses. . Data mining is a broad and complex process with several components. . Conclusion .
After carefully exploring what we mean when we say "big data," the book explores each phase of the big data lifecycle. With Tableau, which focuses on big data visualization , you can create scatter plots, histograms, bar, line, and pie charts. Learn how big data transform banking, law, hospitality, fashion, and science.
To create a successful data project, collect and integrate data from as many different sources as possible. Here are some options for collectingdata that you can utilize: Connect to an existing database that is already public or access your private database. Source Code: Fruit Image Classification 2.
Note: The Date column in Walmart_Sales is continuous and part of a valid date table marked in your data model. Now, we will examine the process of working with DAX in Power BI to create powerful calculations and unlock advanced data insights. Fuel_Price is the intended metric for this calculation.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content