This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
From origin through all points of consumption both on-prem and in the cloud, all data flows need to be controlled in a simple, secure, universal, scalable, and cost-effective way. controlling distribution while also allowing the freedom and flexibility to deliver the data to different services is more critical than ever. .
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
There are obligations on telecommunications providers to ensure that their systems of AI are accountable and understandable to clients and regulatory authorities. The considerable amount of unstructureddata required Random Trees to create AI models that ensure privacy and data handling.
While today’s world abounds with data, gathering valuable information presents a lot of organizational and technical challenges, which we are going to address in this article. We’ll particularly explore datacollection approaches and tools for analytics and machine learning projects. What is datacollection?
A fragmented resource planning system causes data silos, making enterprise-wide visibility virtually impossible. And in many ERP consolidations, historical data from the legacy system is lost, making it challenging to do predictive analytics. Ease of use Snowflake’s architectural simplicity improves ease of use.
As advanced use cases, like advanced driver assistance systems featuring lane change departure detection, advanced vehicle diagnostics, or predictive maintenance move forward, the existing infrastructure of the connected car is being stressed. billion in 2019, and is projected to reach $225.16 billion by 2027, registering a CAGR of 17.1%
For more information, check out the best Data Science certification. A data scientist’s job description focuses on the following – Automating the collection process and identifying the valuable data. A Python with Data Science course is a great career investment and will pay off great rewards in the future.
You’ll learn about the types of recommender systems, their differences, strengths, weaknesses, and real-life examples. Personalization and recommender systems in a nutshell. Primarily developed to help users deal with a large range of choices they encounter, recommender systems come into play. Amazon, Booking.com) and.
They build scalable data processing pipelines and provide analytical insights to business users. A Data Engineer also designs, builds, integrates, and manages large-scale data processing systems. Let’s take a look at Morgan Stanley interview question : What is data engineering? What is a data warehouse?
Data Science is a field of study that handles large volumes of data using technological and modern techniques. This field uses several scientific procedures to understand structured, semi-structured, and unstructureddata. Both data science and software engineering rely largely on programming skills.
We’ll build a data architecture to support our racing team starting from the three canonical layers : Data Lake, Data Warehouse, and Data Mart. Data Lake A data lake would serve as a repository for raw and unstructureddata generated from various sources within the Formula 1 ecosystem: telemetry data from the cars (e.g.
Here are six key components that are fundamental to building and maintaining an effective data pipeline. Data sources The first component of a modern data pipeline is the data source, which is the origin of the data your business leverages. Historically, batch processing was sufficient for many use cases.
More Data Sources Than Ever Before The world has moved away from big monolithic systems that house most of their mission-critical data. Today, organizations augment large-scale ERP systems with CRM software and digital marketing automation, ecommerce systems, customer service tools, and more.
These projects typically involve a collaborative team of software developers, data scientists, machine learning engineers, and subject matter experts. The development process may include tasks such as building and training machine learning models, datacollection and cleaning, and testing and optimizing the final product.
Intel and Cloudera saved a hospital system millions of dollars. A large hospital group partnered with Intel, the world’s leading chipmaker, and Cloudera, a Big Data platform built on Apache Hadoop , to create AI mechanisms predicting a discharge date at the time of admission. As with any ML initiative, everything starts with data.
In legacy analytical systems such as enterprise data warehouses, the scalability challenges of a system were primarily associated with computational scalability, i.e., the ability of a data platform to handle larger volumes of data in an agile and cost-efficient way. Introduction. CRM platforms).
However, as we progressed, data became complicated, more unstructured, or, in most cases, semi-structured. This mainly happened because data that is collected in recent times is vast and the source of collection of such data is varied, for example, datacollected from text files, financial documents, multimedia data, sensors, etc.
The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. The framework provides a way to divide a huge datacollection into smaller chunks and shove them across interconnected computers or nodes that make up a Hadoop cluster. cost-effectiveness.
The approach finds application in security systems for user authentication. Systems like Audio Analytic ‘listen’ to the events inside and outside your car, enabling the vehicle to make adjustments in order to increase a driver’s safety. Audio data file formats. Audio data transformation basics to know. Music recognition.
Use Stack Overflow Data for Analytic Purposes Project Overview: What if you had access to all or most of the public repos on GitHub? As part of similar research, Felipe Hoffa analysed gigabytes of data spread over many publications from Google's BigQuery datacollection. Which queries do you have?
They identify business problems and opportunities to enhance the practices, processes, and systems within an organization. Using Big Data, they provide technical solutions and insights that can help achieve business goals. They transform data into easily understandable insights using predictive, prescriptive, and descriptive analysis.
As our catalog expands, we seek new approaches driven by machine learning to auto-enrich SKU data. Extracting attribute-value information from unstructureddata is formally known as named-entity recognition ; most recent approaches model the extraction task as a token classification.
Change Data Capture (CDC) plays a key role here by capturing and streaming only the changes (inserts, updates, deletes) in real time, ensuring efficient data handling and up-to-date information across systems. Why are Data Pipelines Significant? Now that we’ve answered the question, ‘What is a data pipeline?’
Data Types and Dimensionality ML algorithms work well with structured and tabular data, where the number of features is relatively small. DL models excel at handling unstructureddata such as images, audio, and text, where the data has a large number of features or high dimensionality.
Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization Image Credit: twitter.com There are hundreds of companies like Facebook, Twitter, and LinkedIn generating yottabytes of data. What is Big Data according to EMC? What is Hadoop?
The process of identifying the sources and then getting Big Data varies from company to company. It’s worth noting though that datacollection commonly happens in real-time or near real-time to ensure immediate processing. Data storage and processing. Hadoop architecture layers. Source: phoenixNAP. NoSQL databases.
An information and computer scientist, database and software programmer, curator, and knowledgeable annotator are all examples of data scientists. They are all crucial for the administration of digital datacollection to be successful. In the twenty-first century, data science is regarded as a profitable career.
The larger the company, the more data it has to generate actionable insights. Because it is scattered across disparate systems, hardly available for analytical apps. Evidently, common storage solutions fail to provide a unified data view and meet the needs of companies for seamless data flow. Data lake vs data hub.
Another important task is to evaluate the company’s hardware and software and identify if there is a need to replace old components and migrate data to a new system. Source: Pragmatic Works This specialist also oversees the deployment of the proposed framework as well as data migration and data integration processes.
Depending on what sort of leaky analogy you prefer, data can be the new oil , gold , or even electricity. Of course, even the biggest data sets are worthless, and might even be a liability, if they arent organized properly. Datacollected from every corner of modern society has transformed the way people live and do business.
Receipt table (later referred to as table_receipts_index): It turns out that all the receipts were manually entered into the system, which creates unstructureddata that is error-prone. This datacollection method was chosen because it was simple to deploy, with each employee responsible for their own receipts.
Access to employee data and information is essential for efficient staff management. Employee database software used is also recognized to encourage openness, maintain organization, centralize employee records, and maintain an employee payroll management system. . The various steps in the data management process are listed below: .
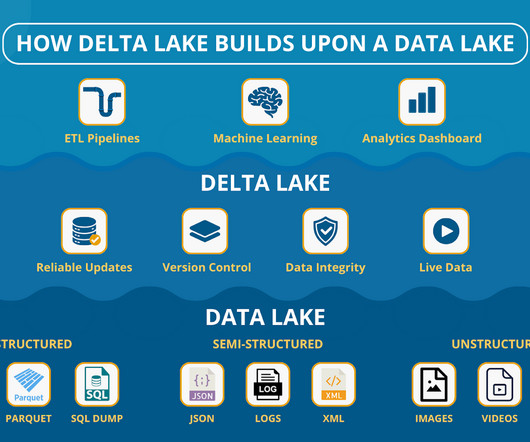
You might end up with missing or inconsistent data, which means your fraud detection system wont always catch issues fast enough. Plus, versioning keeps your data accurate and up to date at all times. The Outcome: Your fraud detection system becomes rock-solid. Think of Delta Lake as a data lake on steroids.
Data science is an interdisciplinary field that employs scientific techniques, procedures, formulas, and systems to draw conclusions and knowledge from a variety of structured and unstructureddata sources. For example, entrepreneurs can identify opportunities for new features or products by analyzing customer data.
In addition, they are responsible for developing pipelines that turn raw data into formats that data consumers can use easily. He researches, develops, and implements artificial intelligence (AI) systems to automate predictive models. They transform unstructureddata into scalable models for data science.
This article will define in simple terms what a data warehouse is, how it’s different from a database, fundamentals of how they work, and an overview of today’s most popular data warehouses. What is a data warehouse? An ETL tool or API-based batch processing/streaming is used to pump all of this data into a data warehouse.
A Data Engineer's primary responsibility is the construction and upkeep of a data warehouse. In this role, they would help the Analytics team become ready to leverage both structured and unstructureddata in their model creation processes. They construct pipelines to collect and transform data from many sources.
Deep Learning is an AI Function that involves imitating the human brain in processing data and creating patterns for decision-making. It’s a subset of ML which is capable of learning from unstructureddata. Their role focuses on ensuring a smooth and efficient flow of data. ML And AI Are The Future.
What follows is an elaborate explanation on how SAP and Hadoop together can bring in novel big data solutions to the enterprise. “SAP systems hold vast amounts of valuable business data -- and there is a need to enrich this, bring context to it, using the kinds of data that is being stored in Hadoop.
In a dimensional approach, data partitioning techniques separately store facts and dimensions. Typically, organizational business processes and systems define the facts, while dimensions provide the metrics for the facts. What is a Data Lake? The facts are valuable information, and the dimensions provide context to these facts.
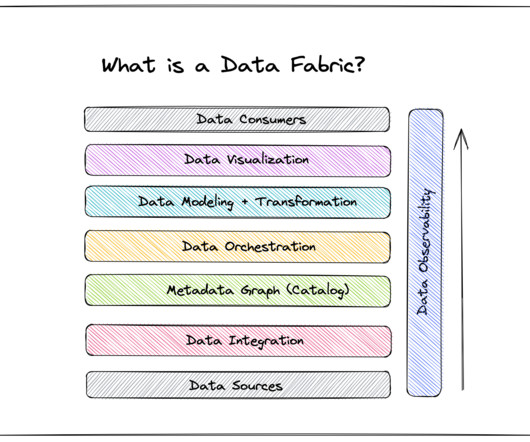
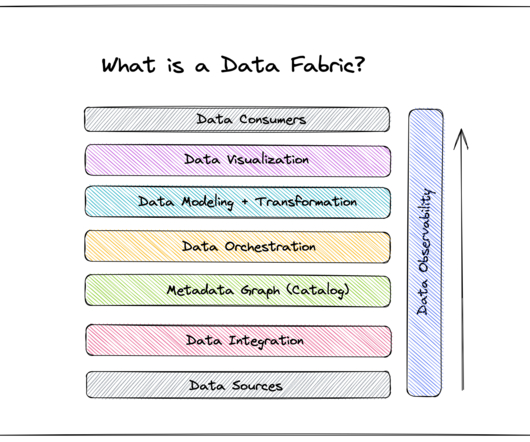
A data fabric isn’t a standalone technology—it’s a data management architecture that leverages an integrated data layer atop underlying data in order to empower business leaders with real-time analytics and data-driven insights. To integrate and unify that distributed data, Domino’s implemented a data fabric.
A data fabric isn’t a standalone technology—it’s a data management architecture that leverages an integrated data layer atop underlying data in order to empower business leaders with real-time analytics and data-driven insights. To integrate and unify that distributed data, Domino’s implemented a data fabric.
Big data enables businesses to get valuable insights into their products or services. Almost every company employs data models and big data technologies to improve its techniques and marketing campaigns. Most leading companies use big data analytical tools to enhance business decisions and increase revenues.
If you're wondering how the ETL process can drive your company to a new era of success, this blog will help you discover what use cases of ETL make it a critical component in many data management and analytic systems. Business Intelligence - ETL is a key component of BI systems for extracting and preparing data for analytics.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content