This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The name comes from the concept of “spare cores:” machines currently unused, which can be reclaimed at any time, that cloud providers tend to offer at a steep discount to keep server utilization high. Storing data: datacollected is stored to allow for historical comparisons. Source: Spare Cores. Tech stack.
Summary With the attention being paid to the systems that power large volumes of high velocity data it is easy to forget about the value of datacollection at human scales. What are some of the integration challenges that are unique to the types of data that get collected by mobile field workers?
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. This nuanced integration of data and technology empowers us to offer bespoke content recommendations. This leads to a lot of false positives that require manual judgement.
In the utility sector, demand forecasting is crucial for customer satisfaction with energy services, ensuring the efficiency of operations and using the funds in a correct manner. This article explains the phenomena of GenAi in utilities: how it improves the processes of energy forecasting, operations, and decision-making.
The primary goal of datacollection is to gather high-quality information that aims to provide responses to all of the open-ended questions. Businesses and management can obtain high-quality information by collectingdata that is necessary for making educated decisions. . What is DataCollection?
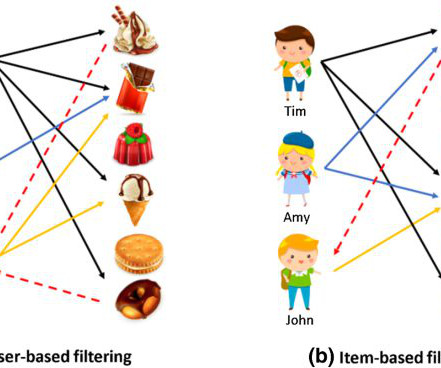
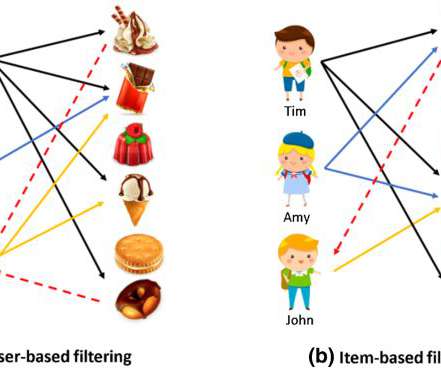
You’ll learn about the types of recommender systems, their differences, strengths, weaknesses, and real-life examples. Personalization and recommender systems in a nutshell. At the same time, the continuous growth of available data has led to information overload — when there are too many choices, complicating decision-making.
The secret sauce is datacollection. Data is everywhere these days, but how exactly is it collected? This article breaks it down for you with thorough explanations of the different types of datacollection methods and best practices to gather information. What Is DataCollection?
Next, in order for the client to leverage their collected user clickstream data to enhance the online user experience, the WeCloudData team was tasked with developing recommender system models whereby users can receive more personalized article recommendations.
Next, in order for the client to leverage their collected user clickstream data to enhance the online user experience, the WeCloudData team was tasked with developing recommender system models whereby users can receive more personalized article recommendations.
Unified Logging System: We implemented comprehensive engagement tracking that helps us understand how users interact with gift content differently from standardPins. Unified Logging System: We implemented comprehensive engagement tracking that helps us understand how users interact with gift content differently from standardPins.
Summary A lot of the work that goes into data engineering is trying to make sense of the "data exhaust" from other applications and services. There is an undeniable amount of value and utility in that information, but it also introduces significant cost and time requirements. When is Snowplow the wrong choice?
There are obligations on telecommunications providers to ensure that their systems of AI are accountable and understandable to clients and regulatory authorities. Using sophisticated AI, telecoms are also able to fully utilize their data, provide individualized interactions, and nurture customers over time.
For more information, check out the best Data Science certification. A data scientist’s job description focuses on the following – Automating the collection process and identifying the valuable data. A Python with Data Science course is a great career investment and will pay off great rewards in the future.
In our previous system, which operated on a daily budget allocation model, the system relied on predicting daily budgets for individual users on a daily basis, constraining the flexibility and responsiveness required for dynamic user engagement and content changes. Figure 1 below shows the overview of the system architecture.
This talk showcases Bifrost and Echo , which are the first networks to directly connect the US and Singapore and will support SGA, Meta’s first APAC data center. Millisampler data allows us to characterize microbursts at millisecond or even microsecond granularity.
The data journey is not linear, but it is an infinite loop data lifecycle – initiating at the edge, weaving through a data platform, and resulting in business imperative insights applied to real business-critical problems that result in new data-led initiatives. DataCollection Challenge. Factory ID.
Furthermore, the same tools that empower cybercrime can drive fraudulent use of public-sector data as well as fraudulent access to government systems. In financial services, another highly regulated, data-intensive industry, some 80 percent of industry experts say artificial intelligence is helping to reduce fraud.
For instance, if you’re marketing premium spirits and only train your AI using data that mimics beer drinkers’ behavior, the results will be highly wrong and distorted. The datautilized to train the ML models is a major contributor to these biases. The source material is not the only way bias can enter data.
Here are six key components that are fundamental to building and maintaining an effective data pipeline. Data sources The first component of a modern data pipeline is the data source, which is the origin of the data your business leverages. Historically, batch processing was sufficient for many use cases.
Your electric consumption is collected during a month and then processed and billed at the end of that period. Stream processing: data is continuously collected and processed and dispersed to downstream systems. Real-time data processing has many use cases. Stream processing is (near) real-time processing.
Best website for data visualization learning: geeksforgeeks.org Start learning Inferential Statistics and Hypothesis Testing Exploratory data analysis helps you to know patterns and trends in the data using many methods and approaches. In data analysis, EDA performs an important role.
Andreas von Buchwaldt, Grant Mitchell, and Steve Varley of EY (2022) write, “Typically, the necessary data is not captured by legacy processes and systems. CEOs need to identify early the new internal business and impact data they will use to create a true measurement of progress and achievement.”
Summary Industrial applications are one of the primary adopters of Internet of Things (IoT) technologies, with business critical operations being informed by datacollected across a fleet of sensors. What kinds of analysis are you performing on the collecteddata? Closing Announcements Thank you for listening!
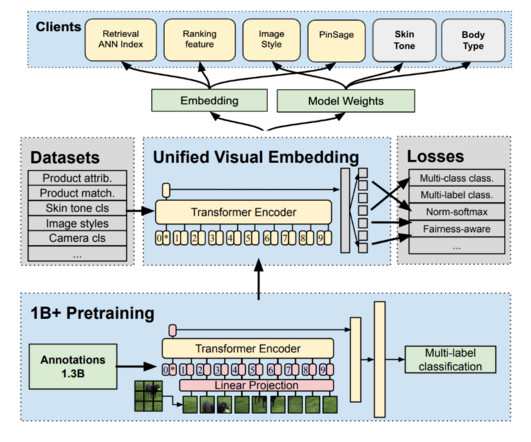
Signal Development and Indexing The process of developing our visual body type signal essentially begins with datacollection. As a first step, we took on the challenge of building a visual body type signal which will help us surface diverse content and also help ensure our recommendations are more representative of various body types.
From his early days at Quora to leading projects at Facebook and his current venture at Fennel (a real-time feature store for ML), Nikhil has traversed the evolving landscape of machine learning engineering and machine learning infrastructure specifically in the context of recommendation systems.
You will learn how to build up Kube-state-metrics system, pull and collect metrics, deploy a Prometheus server and metrics exporters, configure alerts with Alertmanager, and create Grafana dashboards. For use instances when Prometheus cannot scrape the data, it is possible to push metrics to Prometheus using Pushgateway.
Data quality refers to the degree of accuracy, consistency, completeness, reliability, and relevance of the datacollected, stored, and used within an organization or a specific context. High-quality data is essential for making well-informed decisions, performing accurate analyses, and developing effective strategies.
Modern, dynamic dashboards use an HR analytics platform, which facilitates the easy combination of data from various systems and detailed exploration of this data directly within the dashboard. This data can be used to spark effective future efforts. If the data is already in Excel, go to the next step.
Due to the inability to delete or amend the chain without network consensus, the data remains chronologically consistent. To manage orders, payments, accounts, and other transactions, you can utilize blockchain technology to establish an unchangeable or immutable ledger. How to Select a Blockchain Platform for your Business?
To explain Apache Kafka in a simple manner would be to compare it to a central nervous system than collectsdata from various sources. This data is constantly changing, and is voluminous. This data can be anything from clickstream data, activity/ web logs, consumer data, etc.
For stream processing and transformations, one can utilize the Kafka Streams API, which offers T in ETL. Due to the fact that Spark enables users to retrieve, store, and alter data. Its interoperability with other kinds of systems, however, might appear to be extremely difficult. A continuous processing model is an outcome.
These include security concerns and data privacy regulations, data access and management issues, and the complexities of implementing AI solutions into existing life sciences workflows. Additionally, there are high costs associated with implementing AI and maintaining a team of skilled professionals to develop and manage AI systems.
Example 4: To utilize my background in mechanical engineering to improve the efficiency of manufacturing processes for a leading automotive company. Example 9: To utilize my experience in chemical engineering to develop new, environmentally-friendly products for a consumer goods company. Undergone data science course.
They build scalable data processing pipelines and provide analytical insights to business users. A Data Engineer also designs, builds, integrates, and manages large-scale data processing systems. Let’s take a look at Morgan Stanley interview question : What is data engineering? What is a data warehouse?
With the rise of streaming architectures and digital transformation initiatives everywhere, enterprises are struggling to find comprehensive tools for data management to handle high volumes of high-velocity streaming data. He currently works at Cloudera, managing their Data-in-Motion product line.
Artificial intelligence (AI) projects are software-based initiatives that utilize machine learning, deep learning, natural language processing, computer vision, and other AI technologies to develop intelligent programs capable of performing various tasks with minimal human intervention. Let us get started!
We were able to meaningfully improve both the predictability and performance of these containers by taking some of the CPU isolation responsibility away from the operating system and moving towards a data driven solution involving combinatorial optimization and machine learning. can we actually make this work in practice?
There are many data science fields in which experts may contribute to the success of a business, and you can hone the abilities you need by specializing in data science subfields. Data Engineering and Warehousing The data is the lifeblood of every successful Data Science endeavor.
For those interested in studying this programming language, several best books for python data science are accessible. Top 8 Python Data Science Books for 2023 Python is one of the programming languages that is most commonly utilized in the field of data science. Let's have a look at some of the top ones.
Artificial Intelligence, at its core, is a branch of Computer Science that aims to replicate or simulate human intelligence in machines and systems. These streams basically consist of algorithms that seek to make either predictions or classifications by creating expert systems that are based on the input data.
Fingerprint Technology-Based ATM This project aims to enhance the security of ATM transactions by utilizing fingerprint recognition for user authentication. Android Local Train Ticketing System Developing an Android Local Train Ticketing System with Java, Android Studio, and SQLite. cvtColor(image, cv2.COLOR_BGR2GRAY)
which is difficult when troubleshooting distributed systems. Troubleshooting a session in Edgar When we started building Edgar four years ago, there were very few open-source distributed tracing systems that satisfied our needs. The next challenge was to stream large amounts of traces via a scalable data processing platform.
Big data can be summed up as a sizable datacollection comprising a variety of informational sets. It is a vast and intricate data set. Big data has been a concept for some time, but it has only just begun to change the corporate sector. This results in a lack of management of data effectively.
It involves extracting meaningful features from the data and using them to make informed decisions or predictions. DataCollection and Pre-processing The first step is to collect the relevant data that contains the patterns of interest. The steps involved in it can be summarized as follows: 1.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content