This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
Solution: Generative AI-Driven Customer Insights In the project, Random Trees, a Generative AI algorithm was created as part of a suite of models for data mining the patterns from patterns in datacollections that were too large for traditional models to easily extract insights from.
For more information, check out the best Data Science certification. A data scientist’s job description focuses on the following – Automating the collection process and identifying the valuable data. To pursue a career in BI development, one must have a strong understanding of data mining, data warehouse design, and SQL.
Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making. These data sources serve as the starting point for the pipeline, providing the raw data that will be ingested, processed, and analyzed.
Let’s take a look at Morgan Stanley interview question : What is data engineering? The data engineering process involves the creation of systems that enable the collection and utilization of data. Analyzing this data often involves Machine Learning, a part of Data Science.
Data Science is a field of study that handles large volumes of data using technological and modern techniques. This field uses several scientific procedures to understand structured, semi-structured, and unstructureddata. Both data science and software engineering rely largely on programming skills.
Big data vs machine learning is indispensable, and it is crucial to effectively discern their dissimilarities to harness their potential. Big Data vs Machine Learning Big data and machine learning serve distinct purposes in the realm of data analysis.
Artificial intelligence (AI) projects are software-based initiatives that utilize machine learning, deep learning, natural language processing, computer vision, and other AI technologies to develop intelligent programs capable of performing various tasks with minimal human intervention. Let us get started!
Big data stands out due to its significant volume, quick velocity, and wide variety, leading to difficulties in storage, processing, analysis, and interpretation. Organizations can utilize big data to discover valuable insights, patterns, and trends that encourage innovation, enhance decision-making, and boost operational efficiency.
Depending on what sort of leaky analogy you prefer, data can be the new oil , gold , or even electricity. Of course, even the biggest data sets are worthless, and might even be a liability, if they arent organized properly. Datacollected from every corner of modern society has transformed the way people live and do business.
An information and computer scientist, database and software programmer, curator, and knowledgeable annotator are all examples of data scientists. They are all crucial for the administration of digital datacollection to be successful. In the twenty-first century, data science is regarded as a profitable career.
Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization Image Credit: twitter.com There are hundreds of companies like Facebook, Twitter, and LinkedIn generating yottabytes of data. What is Big Data according to EMC? What is Hadoop?
The various steps in the data management process are listed below: . Datacollection, processing, validation, and archiving . Combining various data kinds, including both structured and unstructureddata, from various sources . Ensuring catastrophe recovery and high data availability .
Use Stack Overflow Data for Analytic Purposes Project Overview: What if you had access to all or most of the public repos on GitHub? As part of similar research, Felipe Hoffa analysed gigabytes of data spread over many publications from Google's BigQuery datacollection. Which queries do you have?
There are many data science fields in which experts may contribute to the success of a business, and you can hone the abilities you need by specializing in data science subfields. Data Engineering and Warehousing The data is the lifeblood of every successful Data Science endeavor.
Additionally, they create and test the systems necessary to gather and process data for predictive modelling. Data engineers play three important roles: Generalist: With a key focus, data engineers often serve in small teams to complete end-to-end datacollection, intake, and processing.
The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. The framework provides a way to divide a huge datacollection into smaller chunks and shove them across interconnected computers or nodes that make up a Hadoop cluster.
Deep Learning is an AI Function that involves imitating the human brain in processing data and creating patterns for decision-making. It’s a subset of ML which is capable of learning from unstructureddata. Also, experience is required in software development, data processes, and cloud platforms. .
.”- Henry Morris, senior VP with IDC SAP is considering Apache Hadoop as large scale data storage container for the Internet of Things (IoT) deployments and all other application deployments where datacollection and processing requirements are distributed geographically. Table of Contents How SAP Hadoop work together?
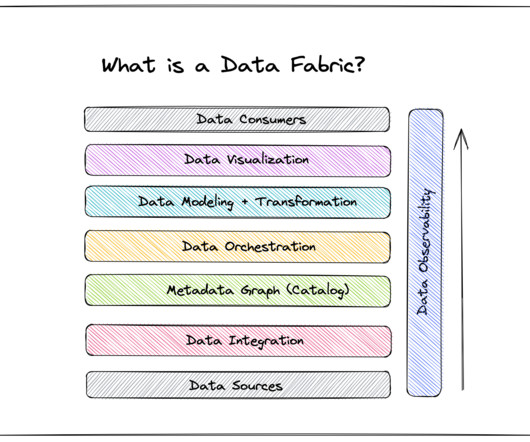
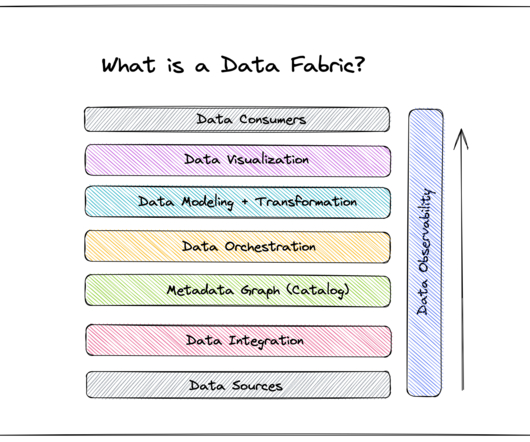
A data fabric isn’t a standalone technology—it’s a data management architecture that leverages an integrated data layer atop underlying data in order to empower business leaders with real-time analytics and data-driven insights. And this innovation ultimately creates bikes that the competition can only dream of.”
A data fabric isn’t a standalone technology—it’s a data management architecture that leverages an integrated data layer atop underlying data in order to empower business leaders with real-time analytics and data-driven insights. And this innovation ultimately creates bikes that the competition can only dream of.”
Medical data labeling. Medical or not, unstructureddata — like texts, images, or audio files — require labeling or annotation to train machine learning models. This process involves adding descriptive elements — tags — to pieces of data so that a computer could understand what the image or text is about.
Data generated from various sources including sensors, log files and social media, you name it, can be utilized both independently and as a supplement to existing transactional data many organizations already have at hand. The process of identifying the sources and then getting Big Data varies from company to company.
NLP also allows businesses to generate insights from unstructureddata sources like customer feedback and social media. Data Discovery and Visualization Data discovery and visualization are also emerging trends in BI. Data discovery refers to exploring data to identify patterns, trends, and outliers.
By utilizing ML algorithms and data, it is possible to create smart models that can precisely predict customer intent and as such provide quality one-to-one recommendations. At the same time, the continuous growth of available data has led to information overload — when there are too many choices, complicating decision-making.
However, the vast volume of data will overwhelm you if you start looking at historical trends. The time-consuming method of datacollection and transformation can be eliminated using ETL. You can analyze and optimize your investment strategy using high-quality structured data.
These factors all work together to help us uncover underlying patterns or observations in raw data that can be extremely useful when making important business choices. Both organized and unstructureddata are used in Data Science. Data Science is thus entirely concerned with the present moment.
Who Uses Real-time Data Analytics? Many industries and businesses utilize real-time data analytics to get insights and make decisions based on datacollected in real time. The data is continually watched, processed, and the necessary actions are done in an iterative process known as real-time analytics.
Its flexibility allows organizations to leverage data value, regardless of its format or source, and can reside in various storage environments, from on-premises solutions to cloud-based platforms or a hybrid approach, tailored to the organization's specific needs and strategies. What is the purpose of extracting data?
In their quest for knowledge, data scientists meticulously identify pertinent questions that require answers and source the relevant data for analysis. Beyond their analytical prowess, they possess the ability to uncover, refine, and present data effectively. Optimizing resource utilization is crucial.
More than 97% of mobile users reportedly utilize AI voice assistants. This is done in the following sequence: Datacollection, Data processing, Feature extraction, Model selection, Training. They can also work with unstructureddata (like emails, feedback, webpages, images, videos, etc.) What is Automation?
Variety: Variety represents the diverse range of data types and formats encountered in Big Data. Traditional data sources typically involve structured data, such as databases and spreadsheets. However, Big Data encompasses unstructureddata, including text documents, images, videos, social media feeds, and sensor data.
Business Intelligence is closely knitted to the field of data science since it leverages information acquired through large data sets to deliver insightful reports. Companies utilize different approaches to deal with data in order to extract information from structured, semi-structured, or unstructureddata sets.
In this blog post, we will look at some of the world's highest paying data science jobs, what they entail, and what skills and experience you need to land them. What is Data Science? Generally, the range is $99,000 to $164,000.
We are producing huge amount of big data ranging from our online purchases on e-commerce websites, our social interactions, financial activities, energy utilization, driving activities, online marketing campaigns and online petitions. The customer’s data is highly valuable to a company.
Big data enables businesses to get valuable insights into their products or services. Almost every company employs data models and big data technologies to improve its techniques and marketing campaigns. Most leading companies use big data analytical tools to enhance business decisions and increase revenues.
With sufficient and quality data in place, ML becomes a valuable tool to forecast hotel deals. Datacollection and preprocessing As with any machine learning task, it all starts with high-quality data that should be enough for training a model. So how exactly are hotel price prediction tools built? Public datasets.
It is difficult to make sense out of billions of unstructureddata points (in the form of news articles, forum comments, and social media data) without powerful technologies like Hadoop, Spark and NoSQL in place. times better than those with ad-hoc or decentralized teams.
It helps teams organize large amounts of unstructureddata or ideas into meaningful groups based on their natural relationships or similarities. The resulting diagram provides a visual representation of the data, making it easier to identify patterns, themes, and insights that can inform decision-making.
Data Engineer Interview Questions on Big Data Any organization that relies on data must perform big data engineering to stand out from the crowd. But datacollection, storage, and large-scale data processing are only the first steps in the complex process of big data analysis.
These indices are specially designed data structures that map out the data for rapid searches, allowing for the retrieval of queries in milliseconds. As a result, Elasticsearch is exceptionally efficient in managing structured and unstructureddata. Fluentd is a data collector and a lighter-weight alternative to Logstash.
Difference between Data Science and Data Engineering Data Science Data Engineering Data Science involves extracting information from raw data to derive business insights and values using statistical methods. Data Engineering is associated with datacollecting, processing, analyzing, and cleaning data.
Hadoop vs RDBMS Criteria Hadoop RDBMS Datatypes Processes semi-structured and unstructureddata. Processes structured data. Schema Schema on Read Schema on Write Best Fit for Applications Data discovery and Massive Storage/Processing of Unstructureddata. are all examples of unstructureddata.
Thus, as a learner, your goal should be to work on projects that help you explore structured and unstructureddata in different formats. Data Warehousing: Data warehousing utilizes and builds a warehouse for storing data. A data engineer interacts with this warehouse almost on an everyday basis.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content